
Published on September 25, 2024 8:37 PM GMT
This research was completed for London AI Safety Research (LASR) Labs 2024. The team was supervised by Stefan Heimershiem (Apollo Research). Find out more about the programme and express interest in upcoming iterations here.
TL;DR
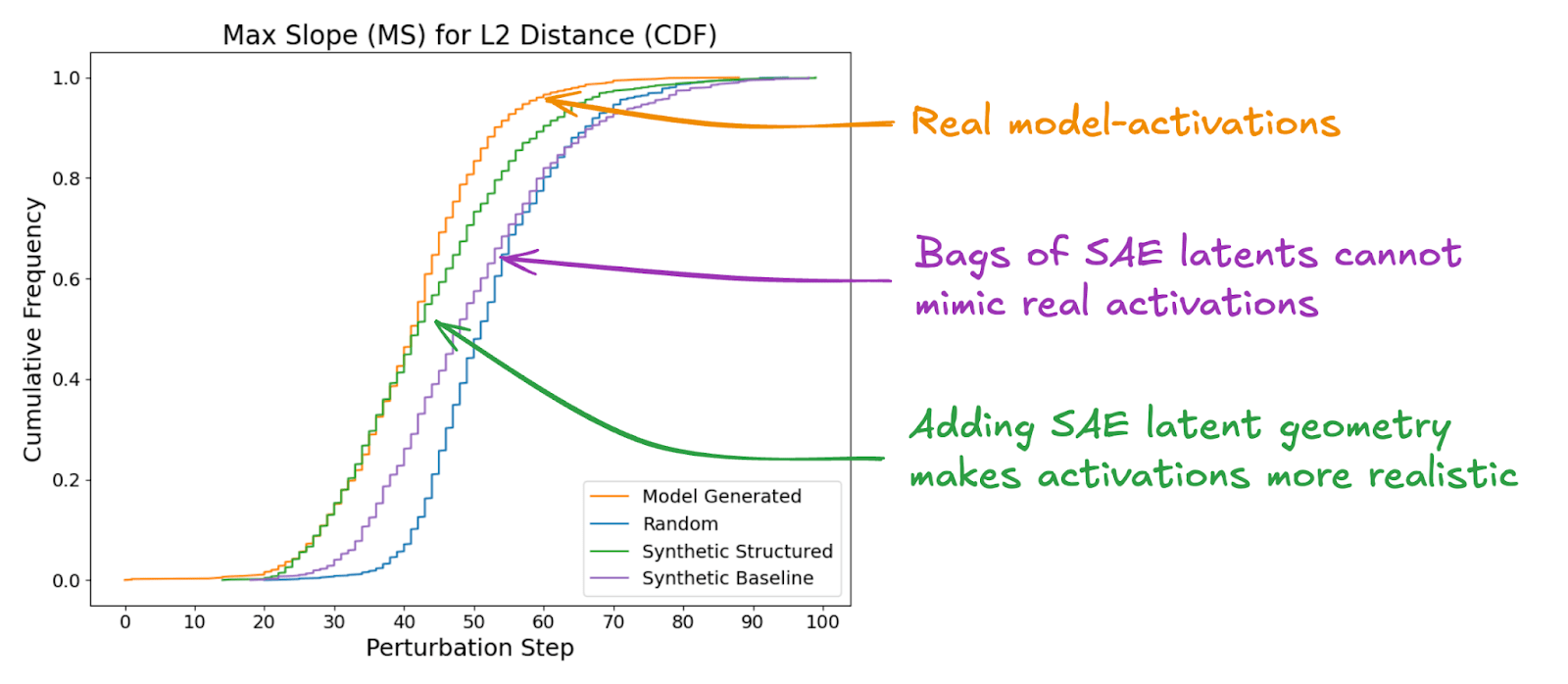
We find that real activations cannot be mimicked using a “bag of SAE latents” with no internal structure, and that geometric and statistical properties of SAE latents play an important role in the composition of a realistic activation (Figure 1).
Paper Overview
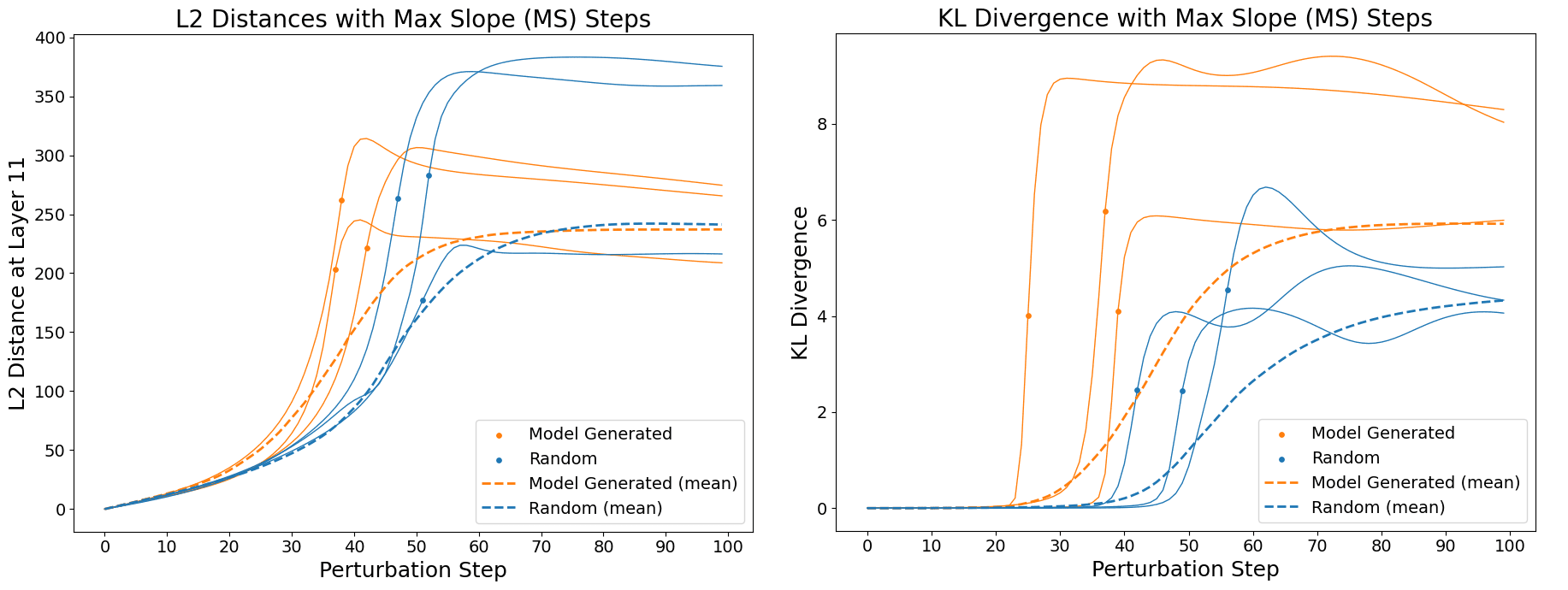
Sparse Auto-Encoders (SAEs) are an increasingly popular method in mechanistic interpretability used to decompose a model’s residual stream into monosemantic and interpretable latents. As the community’s reliance on SAEs grows, it is crucial to verify that they accurately capture abstractions that the model uses in its computation. Recent work has shown that linearly perturbing a language model's activations at an early layer can result in step-function-like changes (“blowups”) in the model's final layer activations (Heimersheim and Mendel, 2024). Importantly, it has been found that perturbing in the direction of model-generated (“real”) activations caused blowups sooner than perturbing in random directions (Figure 2), i.e. the model is more sensitive to perturbations towards real activations than perturbations in random directions. This behavior distinguishes real activations from random directions, and we use it to evaluate synthetic activations made out of SAE latents.
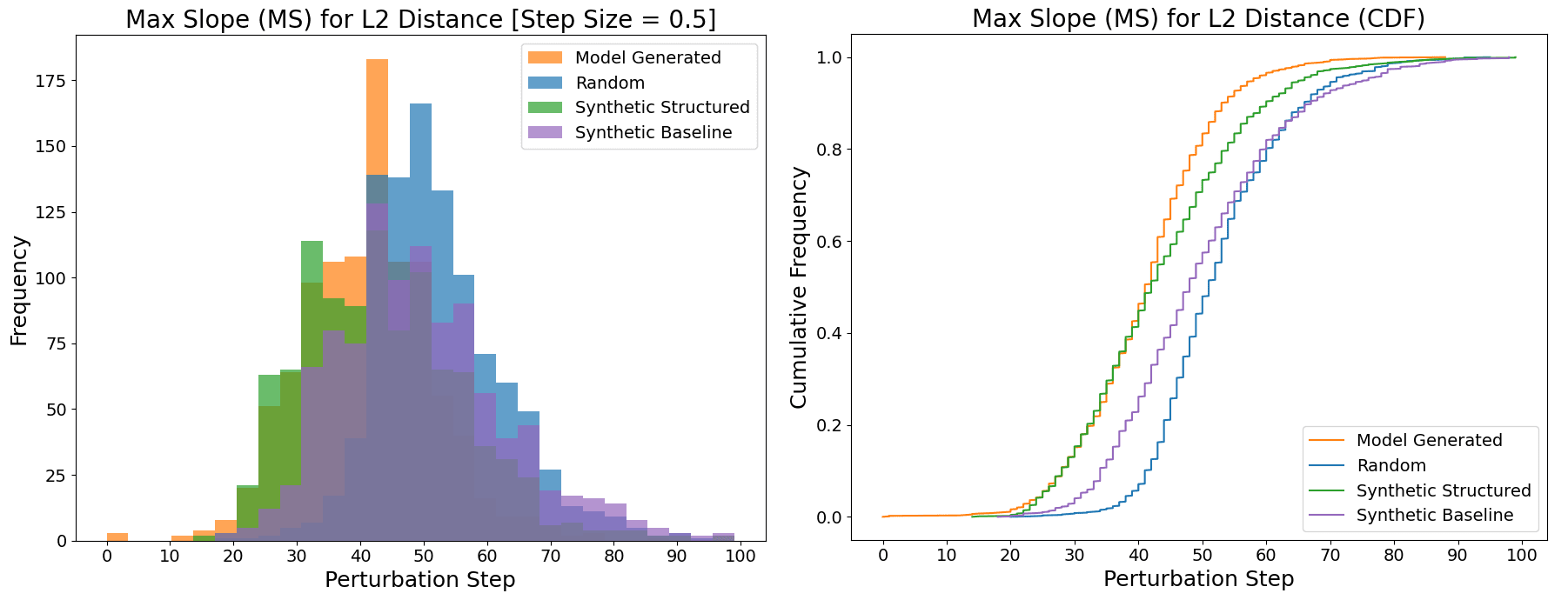
In order to test the model’s sensitivity to different directions, we perturb 1000 real activations towards different types of activations and present the results in Figure 3. Here is a summary of the different types of activations we compare:
- Model-generated: An activation directly taken from Layer 1 for a random prompt given to the model.Random: A randomly sampled point from a normal distribution with the same mean and covariance as model-generated activations.Synthetic Baseline: An activation composed of SAE latents with similar sparsity and latent activations as active latents found in real activations (“bag of SAE latents”).Synthetic Structured: An activation composed of SAE latents where we take into account the pairwise cosine similarities of active latents found in real activations.
We find that the model is more sensitive to perturbations towards synthetic-baseline activations than random activations, which suggests that SAE latents encode more information about model computation than random directions do. However, there is still a large gap between synthetic-baseline activations and model-generated activations, which suggests that real activations cannot be explained using a “bag of SAE latents”. This gap implies that the internal structure of SAE latents that make up an activation matters, in addition to their sparsity and latent activation.
We noticed that the pairwise cosine similarities of active SAE latents with the top active latent follow a specific distribution. We attempt to emulate this distribution with the “synthetic-structured” activations and find that they look a lot more similar to real activations than synthetic-baseline activations do (Figure 3). This similarity provides more evidence that geometric and statistical properties of SAE latents are significant factors in how the model processes information and that just the presence or absence of a latent does not fully describe its semantic meaning.
To test if these findings generalize to activation plateaus (also discussed in Heimersheim and Mendel, 2024), we run a different version of the experiment above, starting from different types of activations and perturbing in random directions. Here, we find that model-generated activations exhibit plateaus that are a lot more pronounced than even our synthetic-structured activations, which means that our synthetic activations are not as robust to noise as real activations. This suggests that there are additional properties of model-generated activations that our current methods do not fully capture, opening up the field for future research.
To read more about this work, including more details about our method and its limitations and a lot more information about different exploratory studies we ran, head to the full paper. Any feedback and comments on our research are highly appreciated!
Discuss
