
Published on August 1, 2024 9:08 PM GMT
- Click here to open a live research preview where you can try interventions using this SAE.

This is a follow-up to a previous post on finding interpretable and steerable features in CLIP.
Introduction
CLIP is a neural network commonly used to guide image diffusion. A Sparse Autoencoder was trained on the dense image embeddings CLIP produces to transform it into a sparse representation of active features. These features seem to represent individual units of meaning. They can also be manipulated in groups — combinations of multiple active features — that represent intuitive concepts. These groups can be understood entirely visually, and often encode surprisingly rich and interesting conceptual detail.
By directly manipulating these groups as single units, image generation can be edited and guided without using prompting or language input. Concepts that were difficult to specify or edit by text prompting become easy and intuitive to manipulate in this new visual representation.
Since many models use the same CLIP joint representation space that this work analyzed, this technique works to control many popular image models out of the box.
Summary of Results
- Any arbitrary image can be decomposed into its constituent concepts. Many concepts (groups of features) that we find seem to slice images up into a fairly natural ontology of their human interpretable components. We find grouping them together is an effective approach to yield a more interpretable and useful grain of control.These concepts can be used like knobs to steer generation in leading models like Stable Cascade. Many concepts have an obvious visual meaning yet are hard to precisely label in language, which suggests that studying CLIP’s internal representations can be used as a lens into the variety of the visual domain. Tweaking the activations of these concepts can be used to expressively steer and guide generation in multiple image diffusion models that we tried.We released the weights and a live demo of controlling image generation in feature space. By analyzing a SAE trained on CLIP, we get a much more vivid picture of the rich understanding that CLIP learns. We hope this is just the beginning of more effective and useful interventions in the internal representations of neural networks like CLIP.
Training Sparse Autoencoders on CLIP
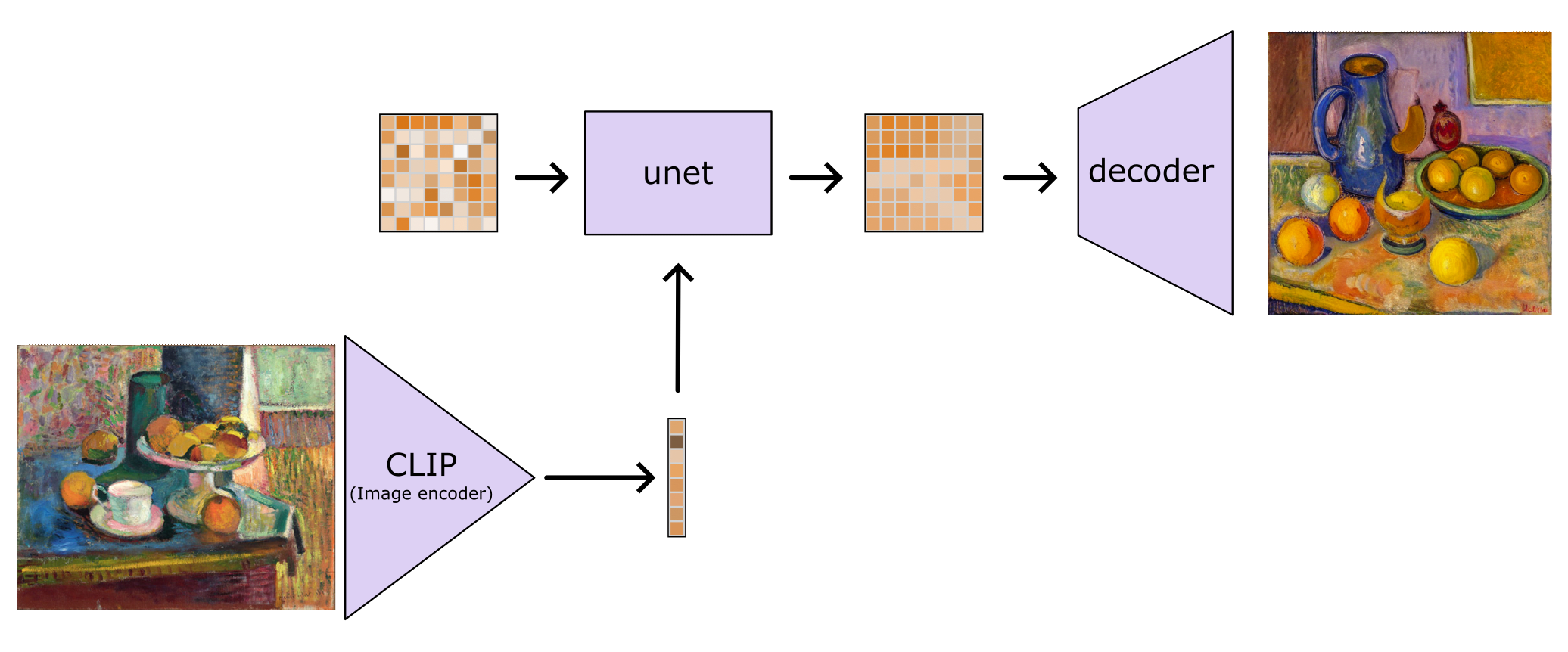
CLIP is a joint image and text embedding model trained using contrastive learning. It consists of two neural networks trained jointly - an image encoder and a text encoder. CLIP is popular in diffusion models (above) as a component to condition the diffusion process based on a text or image input.
We analyzed the outputs of the image encoder model by embedding images from a large dataset. In the previous post[1], we trained a Sparse Autoencoder on CLIP image embeddings and found that the features seemed to map onto monosemantic visual concepts, which we labelled with machine autointerpretation[2].
In this post, the SAE training was improved to try to better steer CLIP embeddings directly. Because there aren’t great metrics for what counts as human interpretable, we chose between runs in the sweep by sampling the feature visualizations from each trained SAE.
We chose a vanilla SAE with a 64x expansion on the 1280-dimensional image embeddings. This results in 81,920 learned features.
This run was trained on a larger variety of 5 million image embeddings from LAION-2B, a dataset about ~3x larger than the run in the previous post.
Training Performance
Some specific details on our training performance:
- Trained on 5 million images from LAION-2B, which is the dataset that
laion/CLIP-ViT-g-14-laion2B-s12B-b42K itself was trained onWe chose a 64x expansion to yield 81,920 learned features- Of these 82k features, ~26% are dead (i.e. never fire)This leaves us with 60,620 alive features
- This is lower than the previous run on ImageNet, probably because the LAION-2B images are more varied and difficult to compress
Weights
The trained weights of the sparse autoencoder are open source here.
Inspecting Images by Feature Activations
SAEs trained on CLIP can find hundreds of active features in an image. While these features seem interpretable, manipulating and steering them becomes a challenging endeavor. There are many active features, and multiple features seem to represent the same thing, i.e. multiple similar features for cats or for patterns.
These features, though plentiful, are not actually redundant. We find that the SAE learns to encode specific nuances of a subject as distinct features, something it does less well in a higher sparsity regime. Sparser SAEs tend to have features that more generically encode for the subject matter, combining fewer features for a single concept. This makes them suffer a higher reconstruction error, which makes it more difficult to analyze a particular subject matter in all of its visual detail.
If each feature is indeed actually important to expressing the overall concept, as we claim, then we'll need new ways to work with larger conceptual units to make it easier for humans to use and interpret these features.
Performing Iterated Grouping
Our approach to improving control for image generation is to find groupings of features.
When grouping features, our first aim is to slice them along their natural boundaries in ways that are natural and intuitive to humans. As part of this aim, we also desire a grouping in which each group contributes meaningfully, i.e. to be clearly important to the end result, without small groups that have little to no perceived effect.
Conveniently, we find that activation mass is a reasonable proxy for importance. Features that have a low activation value tend to be less salient than those that have a high value. For instance, features that correspond to fog produce less prominent fog effects as the activation value decreases. Decreasing the value of features about subjects (e.g. an animal in the picture) makes the subject smaller until it disappears.
We can exploit this property by aiming for groupings where each group has a reasonable share of the activation mass. Inspired by previous work on the surprising effectiveness of k-means[3], we also employ k-means to cluster the linear directions of active features.
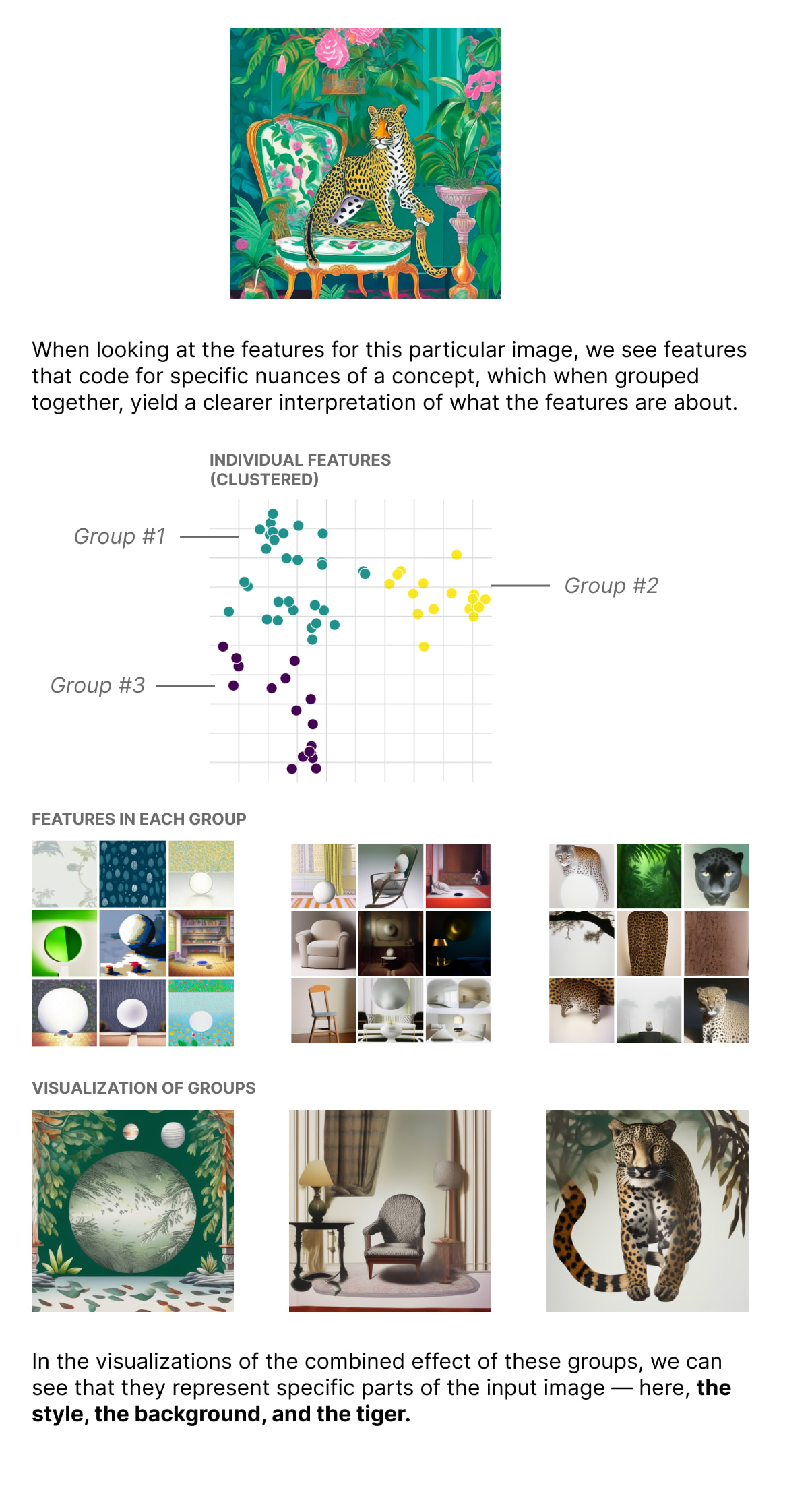
But how do we choose the value of k — the number of clusters? Some images are more complex than others, and so should be grouped into more clusters in order to form a coherent set of groups. But we also don’t want groups that are too small, which contain information that is relatively unimportant and contributes little to understanding the concepts in the embedding.
Our current approach is to do so by trying a range of values of k, and choosing the clustering where all clusters meet some specific threshold of activation mass. Because activation mass is a reasonable proxy for importance, this helps at least ensure that all groups contribute meaningfully to the overall concept, even if activation mass isn’t distributed evenly across the clusters.
More specifically, this process can be formalized as:
- Encode an input image to obtain sparse feature directions and activations .Normalize the feature directions to unit length: for each feature i.Apply spherical k-means to cluster into k clusters weighted by their activations . This is done for a range of k values to try multiple different number of clusters.Select the largest k for which all clusters meet a minimum activation mass requirement: where , are the clusters resulting from k-means, and is a user-selectable threshold from a predefined set of values.
In our dataset, we found = 20 and = 5 to be most useful, but this depends on the specific SAE trained.
Feature Visualization
Previous work on other image models (Olah et. al. 2017)[4] focused on feature visualization via optimization.
In this work, because the features we find represent linear directions in CLIP embedding space, we can apply a simpler approach and use pre-trained models that are conditioned on CLIP to visualize the effect of features. We intervene on a sparse representation with a set of features, and to diffuse an image from the resulting embedding, to form an icon.

Doing this visualization requires some tuning in order to optimize for different facets of what we care about when interpreting features:
- We care about visualizations that, when put side-by-side, are easy to glance over and understand to get an impression of what the feature is about. We do this by scaling the values of the feature directions to a predefined constant. For the particular diffusion model we used, Kadinsky 2.2, values anywhere from 20-150 work well.We also care about isolating the effect of the feature from the contexts it coincidentally appears in. This is achieved by starting from a standard template which weakly specifies a standard context, i.e. a neutral base image. We find that it helps to scale the features of the template down to a fraction, in this case, 1/5th of their original activations, so that they are more easily “overridden” by the features we are actually trying to represent.
These specific values were found by iteratively trying and exploring many different visualization approaches. They’re also specific to the diffusion model we chose, and we found the optimal values are slightly different for other diffusion models we tried, like Stable Cascade.
Applications
Many open source generative image models use CLIP as conditioning for the diffusing images. Notably, though the prototype uses Kadinsky 2.2, steering works equally well for leading open source models like Stable Cascade.
Limitations
- Our methodology prioritizes examining specific samples we intuitively believe contain interesting information, rather than analyzing features across multiple samples. While this approach allows us to better understand potentially insightful cases, it has limitations. We may overlook entirely unexpected behaviors—the 'unknown unknowns'—that aren't immediately apparent or don't align with our initial assumptions about what's important to investigate.This work focused on interpreting the pooled sequence embedding (the "CLS" or "EOS" token) of CLIP.Modern diffusion models use the residual stream from a language model to guide their generation. Interpreting and steering on the residual stream will help us apply this technique to models like SDXL or SDXL-Turbo.
Related Work
Some related work on Sparse Autoencoders trained on CLIP:
- Rao et. al. show that SAEs trained on CLIP can be used to train linear probes instead of using the text encoder.[5]See also Hugo Fry’s work on interpreting ViT. [6]
Conclusion
We find that any arbitrary image can be decomposed into its constituent concepts, and these concepts can be used to effectively steer generative image models. Concepts, which are groups of features, can be grouped via k means and manipulated as a unit to yield more interpretable and useful user affordances. This suggests that grouping activating features together could be more widely useful to SAEs in other domains.
Thanks to friends who reviewed a draft of this post, including Linus Lee, David McSharry, Mehran Jalali, Noa Nabeshima, and others.
Discuss
