
Published on August 24, 2024 7:39 AM GMT
Summary
300 million GPT2-small activations are cached on s3, we pull these very quickly onto a g4dn.8xlarge ec2 instance in the same region and use them to train a 24,576 dimensional Switch Sparse Autocoder in 26 minutes (excluding generation time). We achieve similar L0/reconstruction loss to Gao et al. and a low dead feature proportion. Typically this process takes in the realm of 3-4 hours and far more GPU power, for instance here and here. Code to replicate is made public and so are the weights and biases logs.
Background
There are many excellent resources explaining Sparse Autoencoders and how to train them. The ones linked below do a far better job of laying the groundwork than I ever could.
- The seminal publication on training small SAEs by AnthropicThe publication on scaling SAEs by AnthropicJoseph Bloom's blog post on how to train SAEs
For the rest of this article we will assume the reader knows roughly how to train a SAE.
Objective
One interesting aspect of SAE training is that the base LM is often much larger than the autoencoder. In theory you could save a lot of time and compute if you already had all the activations cached somewhere. In fact, according to some rough profiling, the problem of training a SAE from cached LM activations quickly becomes IO-bound as opposed to compute bound (see the throughput profiling script).
This article is an overview of how we implemented this idea.
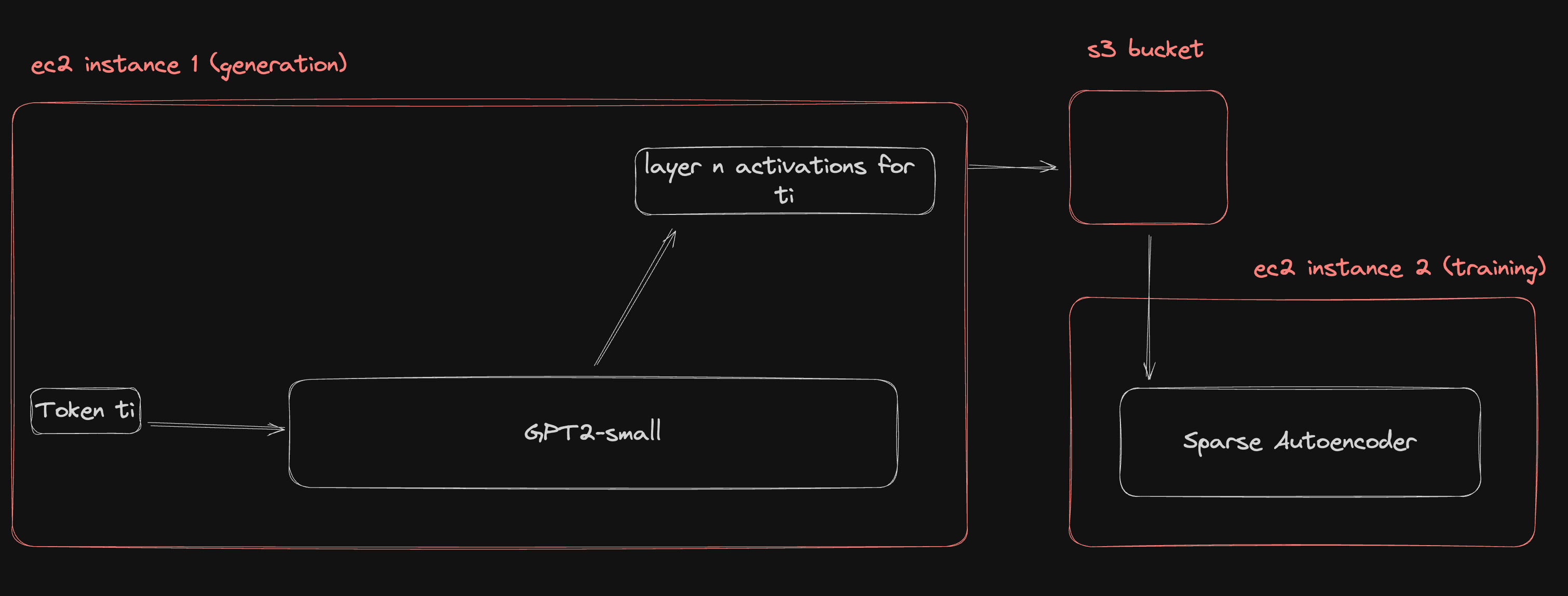
Generating Activations
We generated activations coming from the end (i.e. the "hidden states") of 10th layer of gpt2-small over 678,428,672 tokens from Skylion007/openwebtext and saved them to a public s3 bucket along with some metadata. This was pretty straightforward. Uploading activation tensors from a g4dn.2xlarge instance to an s3 bucket in the same region is quicker than generating them with gpt2-small on the same instance. All that was required to avoid any compute bottlenecking was a little multithreading. See the generation code for implementation details.
Reading Activations
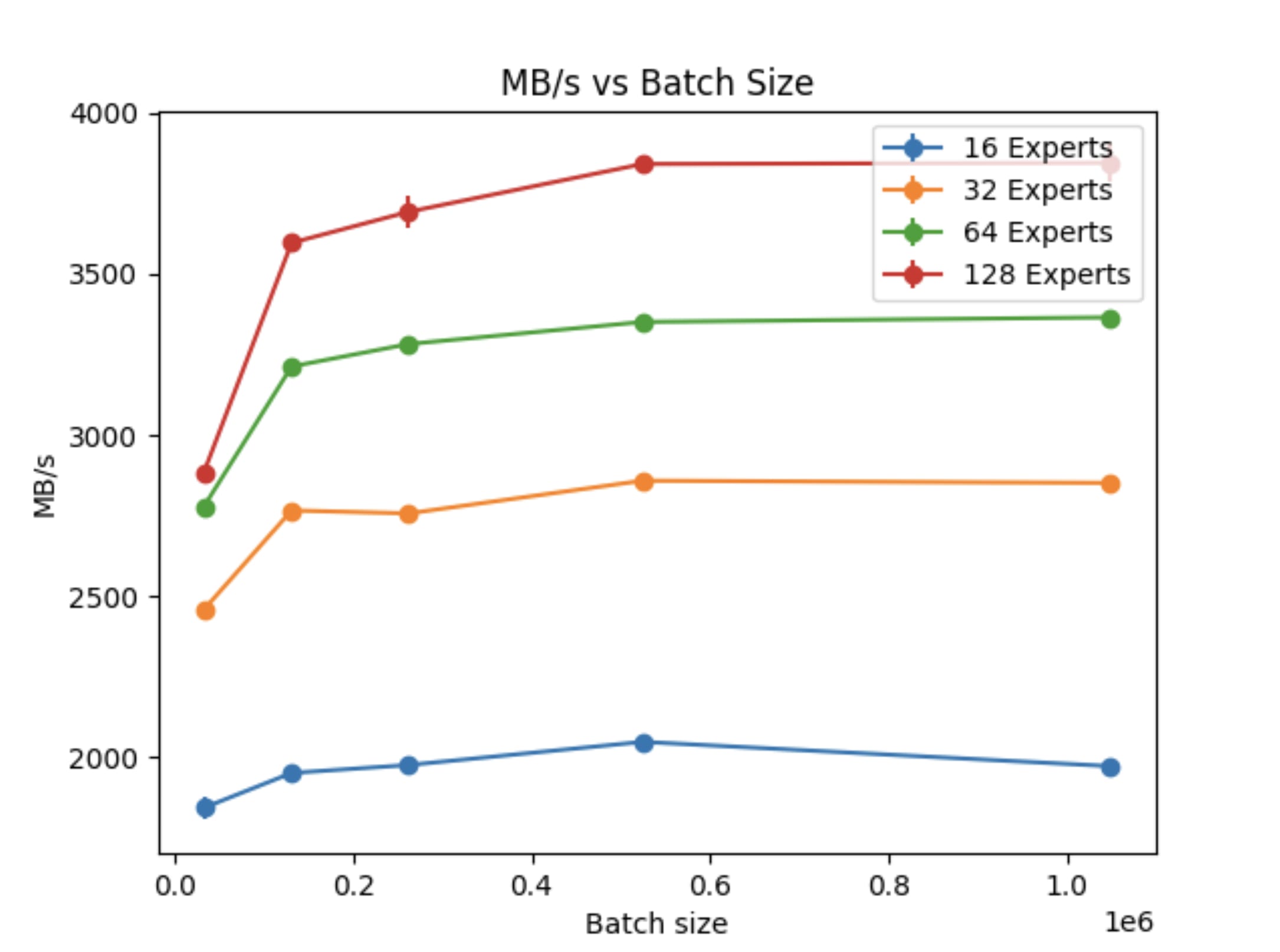
Reading the same data back fast enough is not straightforward. Preliminary profiling on a g4dn.2xlarge instance with 16GB VRAM indicated that the throughput of a 24,576 Switch SAE with 32 experts during training would not exceed 800MB/s, so we would need close to 800MB/s to saturate the process. For reference, in the way we have saved them, ~350 tokens worth of activations take up 1 MB of storage, so 800MB/s is ~280,000 tokens/s. At this rate one could train over 300 million tokens in < 20 minutes.
As well as fast, we would like our storage medium to be sharable. It would be nice if other researchers could train SAEs on small instances without ever needing to load a LM into memory.
Why s3?
Firstly, it has the required throughput. Empirically we were able to achieve an s3 download speed on a g4dn.8xlarge instance of >1000 MB/s with the following high level configuration:
- An instance in the same aws region as the bucketTransfer via http instead of https (this rendered ~40% speed increase)Use of the s3 REST API, as opposed to boto3 or aws cli. There are many threads across the internet delving into the mysteries of the boto3 s3 client and the aws cli s3 client but ultimately we were unable to achieve consistent throughput of more than 250MB/s for an extended period using either.Use of concurrency and recruitment of multiple CPU cores. The s3 REST api is fabulously reliable but requesting chunks of data sequentially is too slow. In order to reach 1000 MB/s we used
aiohttp to achieve concurrency and the vanilla python multiprocessing library to make the task parallel. See s3 downloading code.Even higher throughput can be achieved with more care and more multiprocessing. In theory a g4dn.8xlarge instance should saturate at no less 10,000 MB/s throughput. In addition, s3 limits outgoing data per prefix ("file") rather than per bucket, so as long as you keep your requests spread over a large number of prefixes the bottleneck should always be instance throughput, rather than s3 throughput. Further profiling on this matter would be super interesting, but is out of scope. See the terraform config for more details on the ec2 instance used.
Secondly the s3 api is meticulously documented and built specifically for making data highly accessible, so it achieves our other goal of sharing activtions with others.
Lastly, as long as the data remains in the same AWS region there is no egress cost, just storage, which comes to ~$0.79 per TB per day at time of writing.
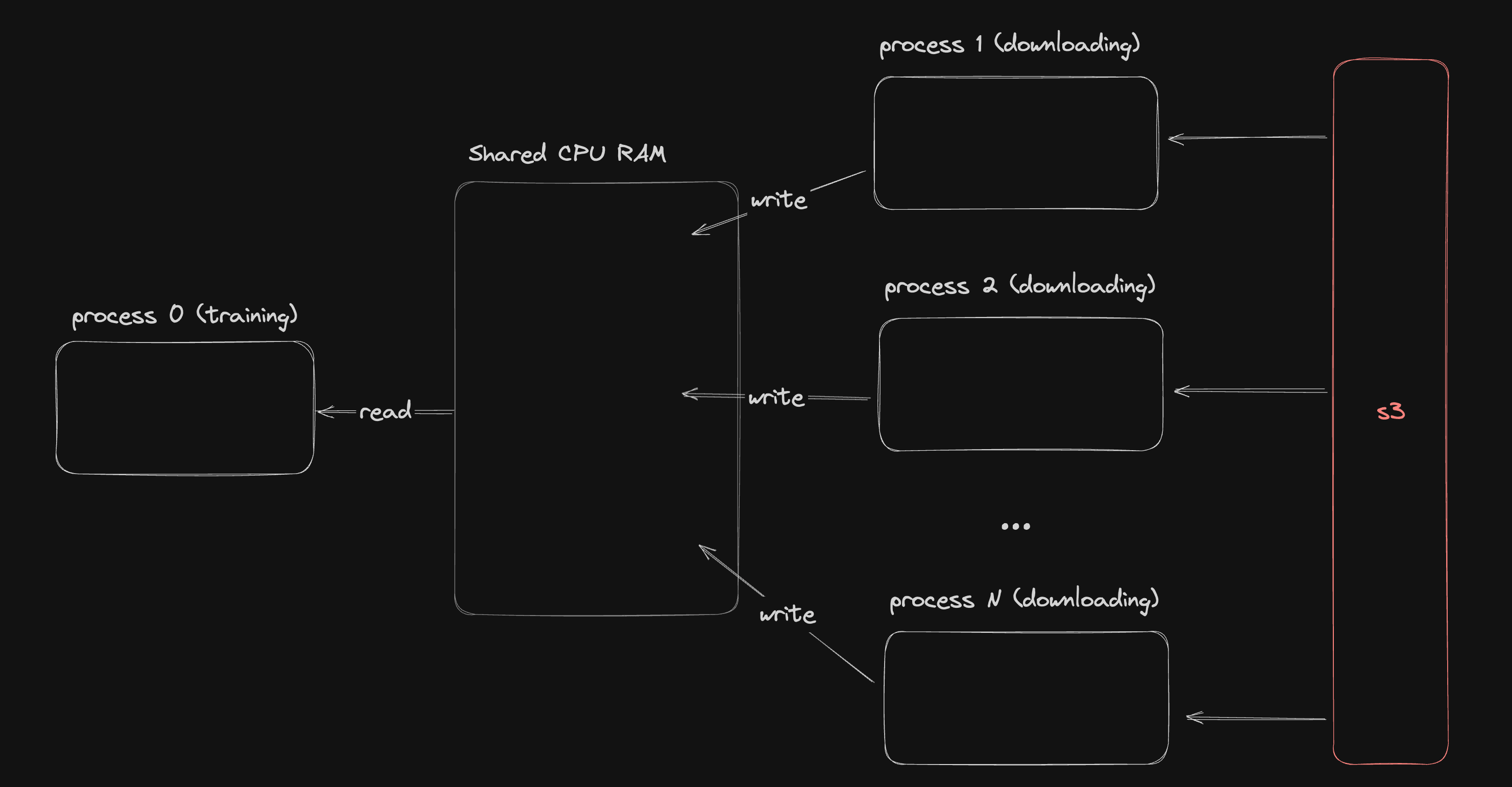
Sharing Memory Between Processes
The multiprocessing requirement is unfortunate because by default different python processes do not share the same memory and ultimately all the tensors we are loading need to end up in the active memory of a single process so that they can be used for training.
We overcame this using pytorch .sharememory() to assign a large buffer of memory as accessible to all processes. The downloading processes assign incoming tensors to large contiguous chunks of this tensor memory which is then be read in by the training process.
Why not EBS?
AWS Elastic Block Store is an alternative means of storing data in AWS which behaves a lot more like disk storage. When using an ec2 instance, the "disk" you read from and write to is actually an EBS volume provisioned for your instance. You can also save these volumes as "snapshots" which persist after your instance is terminated. Snapshots can be shared with other AWS users who can then connect them to new instances. However there are 2 downsides to using EBS for this project:
- Sharing data between ec2 instances through EBS is far less common than through s3 so we are likely to encounter unknown unknowns if we go down this route. For instance, there is no clear documentation stating how long exactly it takes to create a snapshot from an EBS volume.To get 1000 MB/s throughput using EBS is more expensive than s3. AWS charges ~$1.71 per TB per day for snapshot storage, plus an additional ~$11.00 per day for a provisioned EBS gp3 SSD with 1000 MB/s throughput (which includes storage, IO and throughput provisioning). Other EBS storage types are more expensive still, or have lower throughput.
Training the SAE
Unfortunately training a vanilla TopK SAE with a 24,576 latent in 16 GB of GPU ram is very slow. The throughput on a g4dn.8xlarge or smaller g4dn instance is ~50MB/s or 17,500 tokens per second and very much GPU bound.
Switch SAE
Luckily Anish Mudide recently published some excellent research on Switch Sparse Autoencoders which are essentially a "Mixture of Experts" version of a SAE, where you break the latent up into N experts each with a latent dimension of and route each forward pass through just one of these experts. Using this we were able to achieve a ~10x speed increase to around 550MB/s.
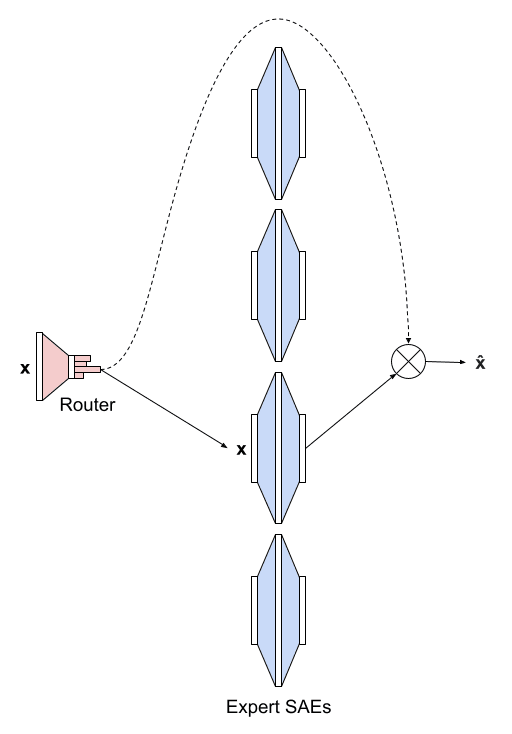
As an aside we observed 30%+ dead latents with the Switch SAE until we added a loss term, described by Anish to discourage the router from ignoring most experts most of the time.
As even more of an aside the code released in this article is the first public implementation of a Switch SAE to our knowledge.
Conclusion
We have shown that it is possible to train SAE's quickly on a small GPUs using cached LM activations stored on S3. We have open sourced the code for doing so as well as 678,428,672 tokens worth of gpt2-small activations and the training logs.
Next Steps
An obvious extension is to increase speed by another 2-4x using a larger GPU, or using a larger GPU to train a SAE on a larger LM like LLama3.1:8B. If anyone would like to collaborate on something similar or has any advice I am very interested in chatting.
Vendor Lock in
One issue with this I/O optimized SAE training project is that it comes with some fairly gritty details of AWS cloud architecture baked in. In a way it isn't even open-source, since anyone wanting to replicate it right now can only do so using servers inside the us-east-1 AWS region. This is quite sad, but as a dear family member once told me: "with great scale comes great vendor lock-in".
References
We use sae_lens to generate the activations and rely heavily on Anish Mudide's research on Switch Sparse Autoencoders. I also stole a lot of ideas and indeed whole whopping chunks of code from ElutherAI's sae implementation and OPENAI's SAE implementation. Lastly a lot of the inspiration for this project came from discussions with Joseph Bloom.
Discuss
