
Published on May 16, 2025 3:44 AM GMT
Status: Very early days of the research. No major proof of concept yet. The aim of this research update is to solicit feedback and encourage others to experiment with my code.
Main Idea:
Researchers are using SAE latents to steer model behaviors, yet human-designed selection algorithms are unlikely to reach any sort of optimum for steering tasks such as SAE-based unlearning or helpfulness steering. Inspired by the Bitter Lesson, I have decided to research gradient-based optimization of steering vectors. It should be possible to add trained components into SAEs that act on the latents. These trained components could learn optimal values and algorithms, and if we chose their structure carefully, they can retain the interpretable properties of the SAE latent itself. I call these fine-tuning methods Interpretable Sparse Autoencoder Representation Fine Tuning or “ISaeRFT”.
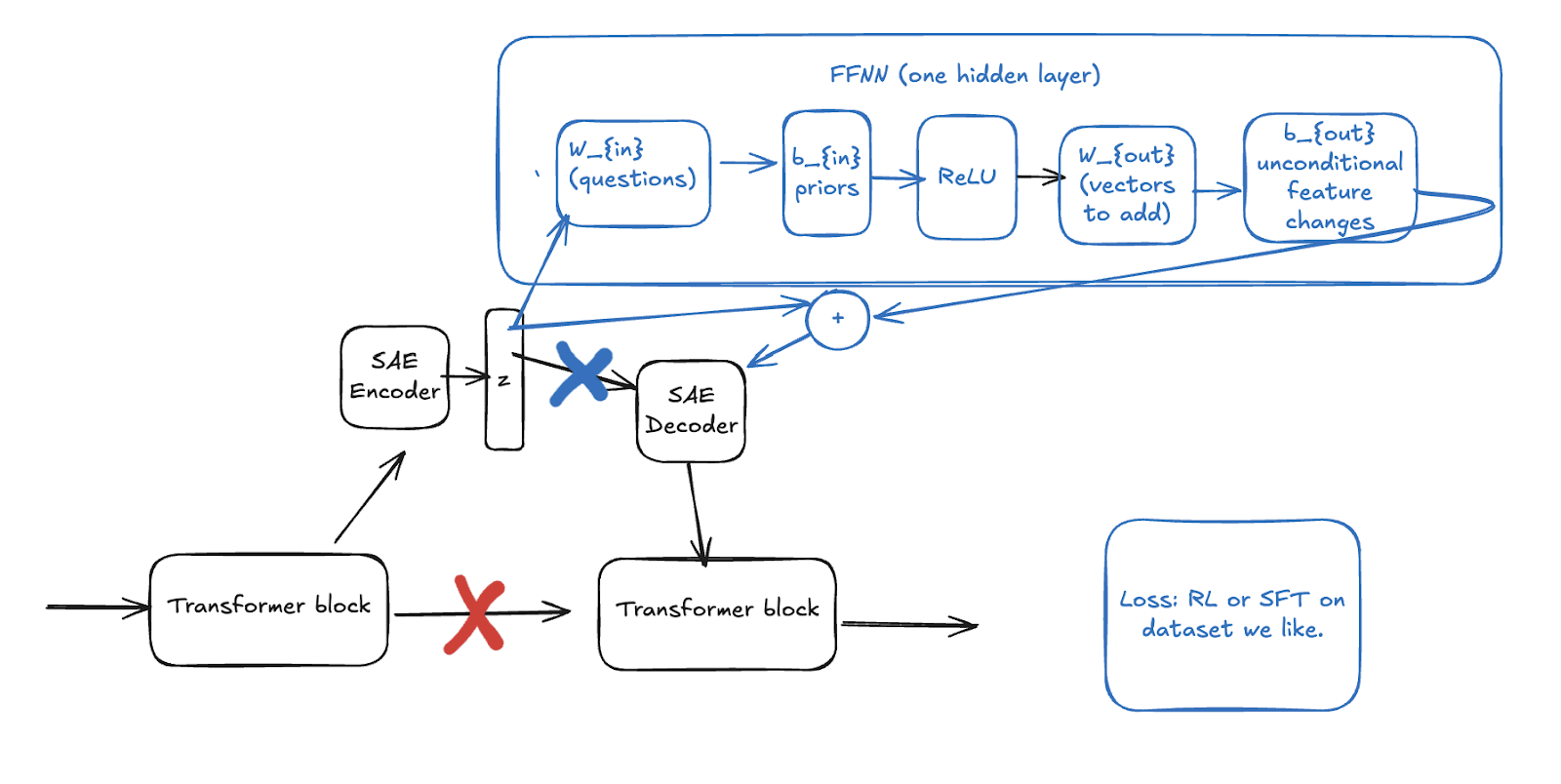
Interpretable components that act on SAE latents contribute to a number of safety-relevant goals:
- Data Auditing
- By seeing which features change during training, it should be possible to check that there aren’t harmful biases in the data or data poisoning. I hope this method can help pin down the cause of Emergent Misalignment and identify when it occurs.
- If current SAE interpretation methods do a good job of reflecting their actual meaning to the model, then that should be reflected in which latents are changed during learning.For example, if you train a model on helpfulness text using ISaeRFT, but when you look at the trained components, features with labels that make them seem irrelevant are changed and features you would expect to be changed are unchanged, then this indicates a problem with the labeling method or the causal relevance of those features.
- ISaeRFT ties nicely to reinforcement-learning based methods for guiding model behaviors, allowing us to understand what these methods taught the model. It can also be used to see what a dataset teaches a model.
Project Update:
The code, though imperfect, works well enough that I encourage others to play around with it and see what you can discover.
The main features are:
- Because I integrated interpretable fine tuning as a Huggingface PeftModel, It is now possible to use Huggingface trainers such as SFTTrainer and DPOTrainer to find optimal steering vectors.
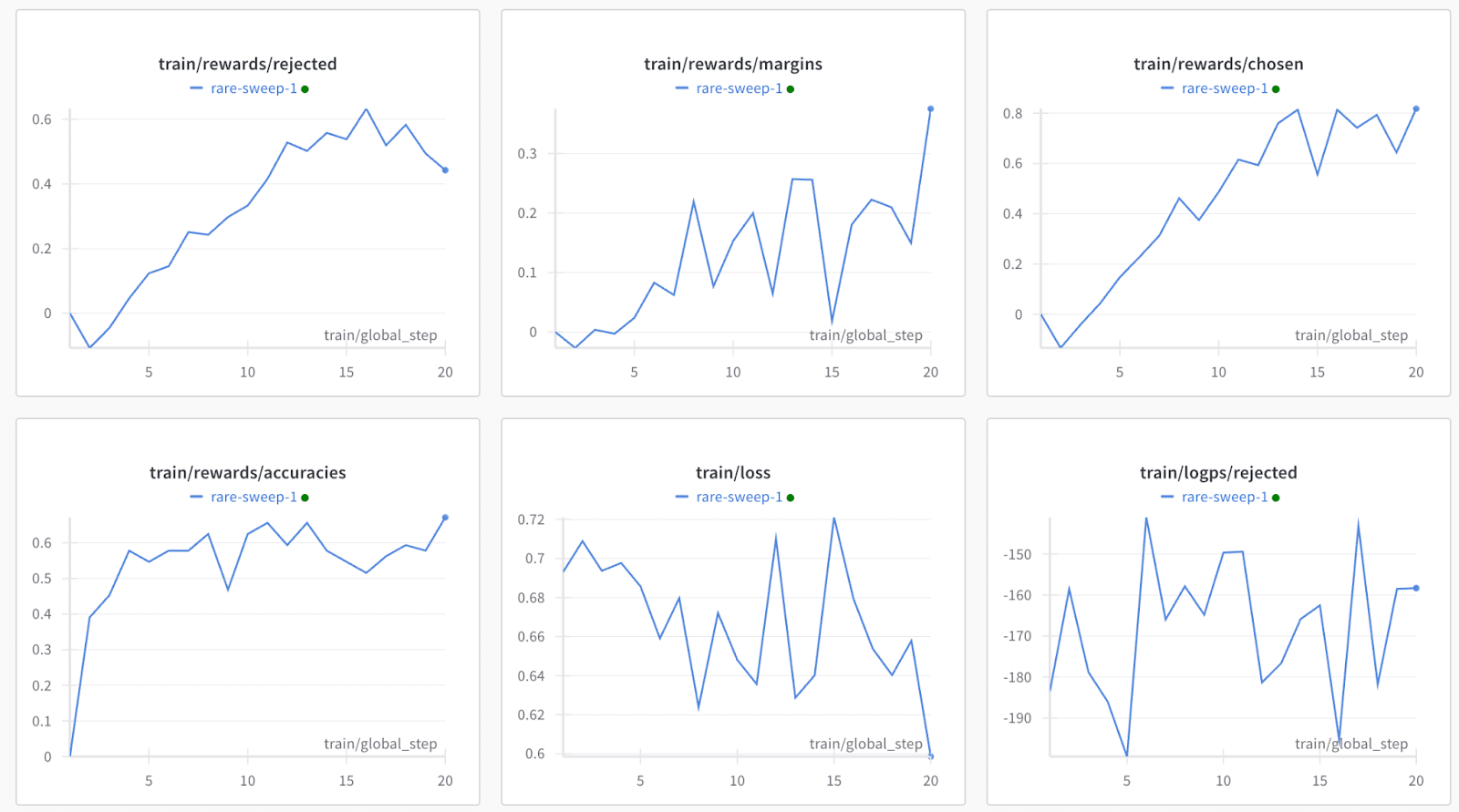
- Inspired by IA3, I implemented the steering type of elementwise multiplication between features and a learned vector. This means that features are scaled up or down. You’d expect good features to be scaled up and bad features to be scaled down.Through custom callbacks, you can track how the interpretable parameters change during training.
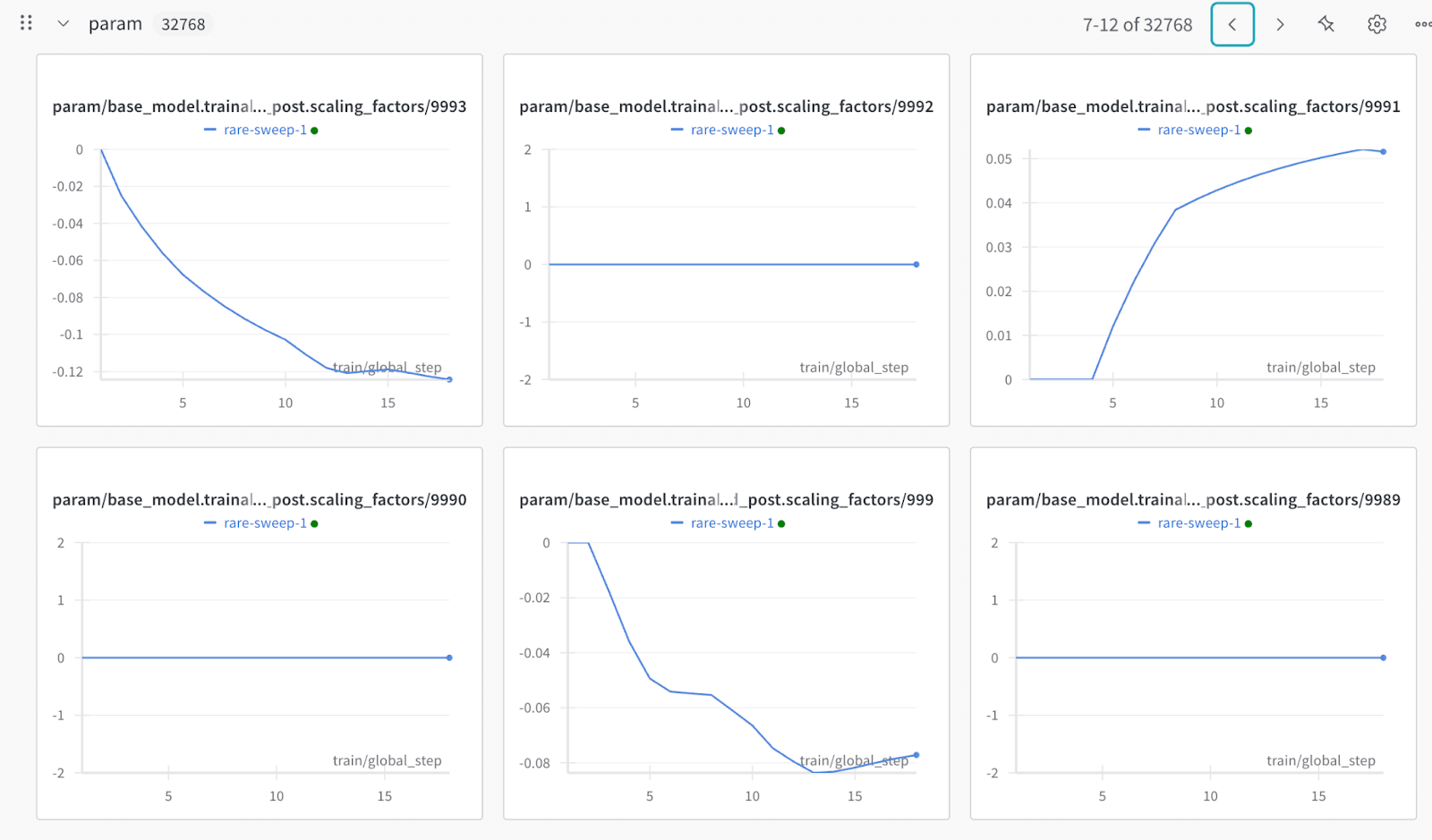
View My Runs:
While I’m writing this, I’m doing a hyperparameter sweep on a Gemma-2-2b Matryoshka SAE.
You can see the features being trained in real time here.
I’ve previously done some runs using non-matryoshka saes, which you can see here. For this sweep, the parameter plots themselves have descriptions, making it convenient to search the panels for features that interest you. You can always refer to Neuronpedia for more information about the features.
How to Use:
I’ll write more detailed documentation soon. If you use my code and have questions, please make a Git issue.
Setup:
Clone the repository.
Pip install the requirements file.
Review ia3_training_isaerft_disable_available.py to see how to optimize steering vectors.
src/export_wandb_data allows you to get data from weights and biases to find which features are scaled up and scaled down the most.
src/model_components contains the torch components which will be placed into the sparse autoencoders to process the latents. At the moment, only IsaerftIA3 is supported.
Also in the model_components folder are IsaerftPeft and IsaerftConfig.
Example usage (from ia3_training_isaerft_disable_available.py)
sae_release = "gemma-2-2b-res-matryoshka-dc"model_sae_id = "blocks.20.hook_resid_post"isaerft_config = IsaerftConfig( target_hooks=[ (sae_release, model_sae_id), # Match the SAE we loaded ], depth=None, ia3=True)peft_model = IsaerftPeft(model, isaerft_config)
After this, peft_model can be used in the same way as a normal huggingface peft_model.[1]
Next Steps:
- Hyperparameter search
- Usually, people use default values for the adam optimizer’s beta1 and beta2 hyperparameters. My method has the strange property where gradients are sparse, because there are only gradients for feature i when feature i is present, and features activate sparsely by design. I suspect that this might mean that we want a larger beta2 to carry gradient information for longer. This may help prevent features from getting boosted up then much later boosted down, when the optimal value is in between.
Conclusion:
If you find this interesting, please get in touch. I’m especially interested in hearing about research I may have missed which would benefit me to know.
- ^
Oddly, having a Huggingface trainer evaluate your model during training is not available for peft models. I hope to find a workaround.
Discuss
