


Large language models (LLMs) have become fundamental tools for tasks such as question-answering (QA) and text summarization. These models excel at processing long and complex texts, with capacities reaching over 100,000 tokens. As LLMs are popular for handling large-context tasks, ensuring their reliability and accuracy becomes more pressing. Users rely on LLMs to sift through vast information and provide concise, correct answers. However, many models suffer from the problem of “hallucination,” where they generate information that is unsupported by the provided text. This limitation significantly affects user trust in these models, as the absence of specific, verifiable citations makes it difficult to confirm the correctness of the answers.
A significant challenge in long-context LLMs is their inability to provide fine-grained citations directly linked to specific text parts. Users often face difficulty trusting LLM-generated answers because the models either fail to provide citations altogether or offer citations that refer broadly to entire text sections rather than pinpointing the exact pieces of information supporting the response. This lack of specificity means that even if the answer is accurate, the user must manually search through large chunks of text to verify the correctness. The need for a system that can offer precise, sentence-level citations is crucial for improving the verifiability and trustworthiness of long-context LLMs.
Existing citation methods, though somewhat effective, still have limitations. Some models employ chunk-level citation techniques, where broad text sections are referenced. While useful for reducing the amount of searching required by users, these chunk-based methods do not go far enough in providing the level of detail needed for accurate verification. Other methods include retrieval-augmented generation (RAG) and post-processing systems, where citations are added after the response is generated. However, due to their multi-step processes, these techniques often need to improve answer quality and slow response times. Moreover, the citations provided by these systems are frequently too broad, making them ineffective for users seeking to locate specific supporting information within large documents.
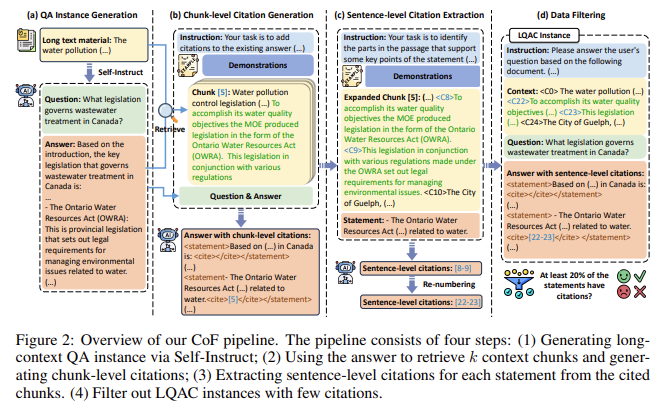
Tsinghua University and Zhipu AI researchers introduced a novel approach to address these limitations through a method called CoF (Coarse to Fine). CoF is designed to generate highly detailed, sentence-level citations, improving the precision and usability of LLM-generated answers. The research team proposed this system as a solution to the problem of broad, imprecise citations, offering a refined approach that provides users with citations linked to specific sentences rather than large text sections. To assess the performance of LLMs in long-context question answering (LQAC), they also developed LongBench-Cite. This automatic benchmark evaluates LLMs’ performance when generating citations from large text corpora. LongBench-Cite revealed significant room for improvement in current models, as many of the citations generated by LLMs were irrelevant or too broadly applied. To test the effectiveness of the new approach, the team built LongCite-45k, a dataset consisting of 44,600 QA pairs with detailed, fine-grained citations. This dataset allows LLMs to train on tasks that require accurate and precise citations, addressing a critical gap in current long-context QA models.

The CoF system functions through steps designed to refine citation accuracy. The process begins with the LLM generating the query and the corresponding answer based on the provided long text. This initial step ensures that the model works with a fully contextualized understanding of the document. Next, the CoF system retrieves relevant chunks of text from the original document, each consisting of 128 tokens. These chunks are then linked to the model’s answer through coarse-grained citations. Finally, the system refines these citations by identifying and extracting the specific sentences within the chunks that directly support the answer. Any answers that lack sufficient citation support are filtered out. This multi-stage approach allows the CoF system to produce responses with precise, sentence-level citations, significantly improving user trust and citation accuracy.
This research demonstrates that CoF-trained models, LongCite-8B and LongCite-9B, outperform existing proprietary models, such as GPT-4, regarding citation quality and granularity. Specifically, LongCite-8B and LongCite-9B achieved a 6.4% and 3.6% improvement over GPT-4 in terms of citation F1 score, a metric used to measure citation accuracy. The average citation length for the LongCite models was also notably shorter than that of proprietary models, further highlighting the precision of the CoF approach. LongCite-8B, for example, generated citations with an average length of 86 tokens, compared to GPT-4’s average of 169 tokens. This level of granularity allows users to locate the specific text supporting the model’s answers more easily. The CoF system reduces the occurrence of hallucinations, as it enables models to more uniformly use all the context available, ensuring that responses are more grounded in the original text.

In conclusion, this research provides a critical advancement in the field of long-context LLMs by addressing a long-standing issue with citation precision. The introduction of LongBench-Cite to assess LLMs’ citation performance, combined with the CoF system and the LongCite-45k dataset, represents a significant step forward in improving the trustworthiness and verifiability of LLM-generated responses. The researchers have enabled LLMs to produce more accurate, reliable answers by focusing on sentence-level citations rather than broad text chunks. The improvements seen in the LongCite-8B and LongCite-9B models demonstrate the effectiveness of this approach, with these models surpassing even the most advanced proprietary systems in citation accuracy. This advancement enhances the performance of long-context QA systems and contributes to the broader goal of making LLMs more dependable tools for information retrieval and question-answering tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and LinkedIn. Join our Telegram Channel.
If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
The post LongBench-Cite and LongCite-45k: Leveraging CoF (Coarse to Fine) Pipeline to Enhance Long-Context LLMs with Fine-Grained Sentence-Level Citations for Improved QA Accuracy and Trustworthiness appeared first on MarkTechPost.
