


Autoregressive language models (ALMs) have proven their capability in machine translation, text generation, etc. However, these models pose challenges, including computational complexity and GPU memory usage. Despite great success in various applications, there is an urgent need to find a cost-effective way to serve these models. Moreover, the generative inference of large language models (LLMs) utilizes the KV Cache mechanism to enhance the generation speed. Still, an increase in model size and generation length leads to an increase in memory usage of the KV cache. When memory usage exceeds GPU capacity, the generative inference of LLMs resorts to offloading.
Many works have been carried out to enhance the model efficiency for LLMs, e.g., one such method is to skip multiple tokens at a particular time stamp. Recently, a technique that adds a token selection task to the original BERT model learns to select performance-crucial tokens and detect unimportant tokens to prune using a designed learnable threshold. However, these models are only applied to non-autoregressive models and require an extra re-training phrase, making them less suitable for auto-regressive LLMs like ChatGPT and Llama. It is important to consider pruning tokens’ potential within the KV cache of auto-regressive LLMs to fill this gap.
Researchers from the University of Illinois Urbana-Champaign and Microsoft proposed FastGen, a highly effective technique to enhance the inference efficiency of LLMs without any loss in visible quality, using lightweight model profiling and adaptive key-value caching. FastGen evicts long-range contexts on attention heads by the KV cache construction in an adaptive manner. Moreover, it is deployed using lightweight attention profiling, which has been used to guide the construction of the adaptive KV cache without resource-intensive fine-tuning or re-training. FastGen is capable of reducing GPU memory usage with negligible generation quality loss.
The adaptive KV Cache compression introduced by the researchers reduces the memory footprint of generative inference for LLMs. In this method, there are two steps for a generative model inference which are involved:
- Prompt Encoding: The attention module needs to collect contextual information from all the preceding i-1 tokens for the i-th token generated by autoregressive transformer-based LLM.Token Generation: When prompt encoding is completed, LLM generates the output token by token, and for each step, the new token(s) generated in the previous step are encoded using the LLM.
For 30B models, FastGen outperforms all non-adaptive KV compression methods and achieves a higher KV cache reduction ratio with an increase in model size, keeping the model’s quality unaffected. For example, FastGen gets a 44.9% pruned ratio on Llama 1-65B, compared to a 16.9% pruned ratio on Llama 1-7B, achieving a 45% win rate. Further, sensitivity analysis was performed on FastGen by choosing different hyper-parameters. Since the model maintains a win rate of 45%, the study shows no visible impact on generation quality after changing the hyper-parameter.
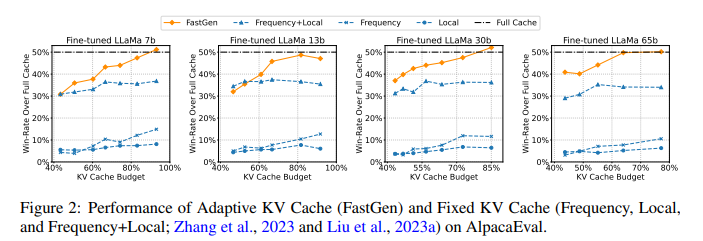
In conclusion, researchers from the University of Illinois Urbana-Champaign and Microsoft proposed FastGen, a new technique to enhance LLMs inference efficiency with no loss in visible quality, using lightweight model profiling and adaptive key-value caching. Also, the adaptive KV Cache compression introduced by researchers is constructed using FastGen to reduce the memory footprint of generative inference for LLMs. Future work includes integrating FastGen with other model compression approaches, e.g., quantization and distillation, grouped-query attention, etc.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
The post FastGen: Cutting GPU Memory Costs Without Compromising on LLM Quality appeared first on MarkTechPost.
