


Multimodal artificial intelligence focuses on developing models capable of processing and integrating diverse data types, such as text and images. These models are essential for answering visual questions and generating descriptive text for images, highlighting AI’s ability to understand and interact with a multifaceted world. Blending information from different modalities allows AI to perform complex tasks more effectively, demonstrating significant promise in research and practical applications.
One of the primary challenges in multimodal AI is optimizing model efficiency. Traditional methods fusing modality-specific encoders or decoders often limit the model’s ability to integrate information across different data types effectively. This limitation results in increased computational demands and reduced performance efficiency. Researchers have been striving to develop new architectures that seamlessly integrate text and image data from the outset, aiming to enhance the model’s performance and efficiency in handling multimodal inputs.
Existing methods for handling mixed-modal data include architectures that preprocess and encode text and image data separately before integrating them. These approaches, while functional, can be computationally intensive and may only partially exploit the potential of early data fusion. The separation of modalities often leads to inefficiencies and an inability to adequately capture the complex relationships between different data types. Therefore, innovative solutions are required to overcome these challenges and achieve better performance.
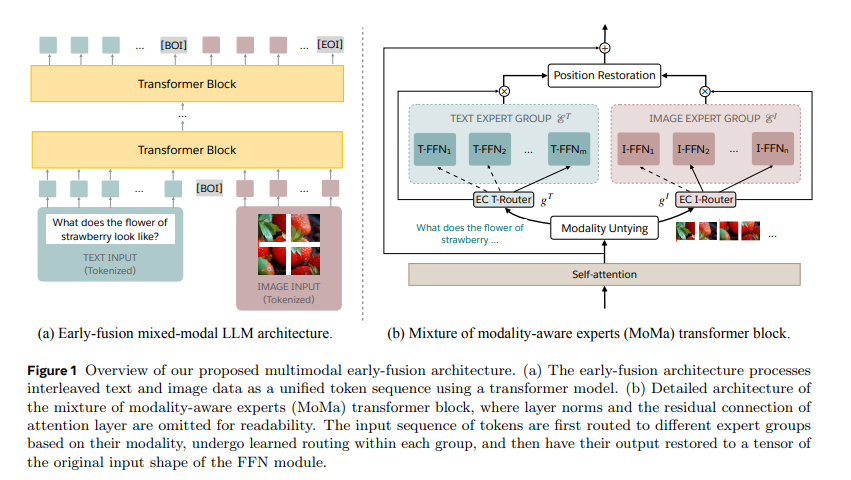
To address these challenges, researchers at Meta introduced MoMa, a novel modality-aware mixture-of-experts (MoE) architecture designed to pre-train mixed-modal, early-fusion language models. MoMa processes text and images in arbitrary sequences by dividing expert modules into modality-specific groups. Each group exclusively handles designated tokens, employing learned routing within each group to maintain semantically informed adaptivity. This architecture significantly improves pre-training efficiency, with empirical results showing substantial gains. The research, conducted by a team at Meta, showcases the potential of MoMa to advance mixed-modal language models.
The technology behind MoMa involves a combination of mixture-of-experts (MoE) and mixture-of-depths (MoD) techniques. In MoE, tokens are routed across a set of feed-forward blocks (experts) at each layer. These experts are divided into text-specific and image-specific groups, allowing for specialized processing pathways. This approach, termed modality-aware sparsity, enhances the model’s ability to capture features specific to each modality while maintaining cross-modality integration through shared self-attention mechanisms. Furthermore, MoD allows tokens to selectively skip computations at certain layers, further optimizing the processing efficiency.
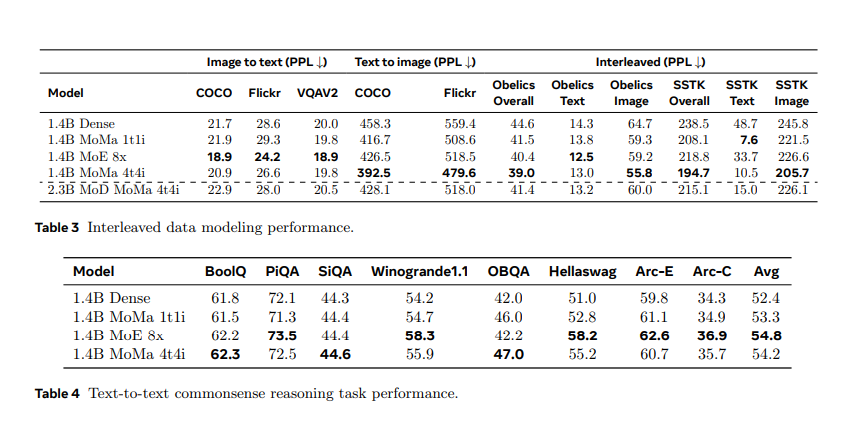
The performance of MoMa was evaluated extensively, showing substantial improvements in efficiency and effectiveness. Under a 1-trillion-token training budget, the MoMa 1.4B model, which includes 4 text experts and 4 image experts, achieved a 3.7× overall reduction in floating-point operations per second (FLOPs) compared to a dense baseline. Specifically, it achieved a 2.6× reduction for text and a 5.2× reduction for image processing. When combined with MoD, the overall FLOPs savings increased to 4.2×, with text processing improving by 3.4× and image processing by 5.3×. These results highlight MoMa’s potential to significantly enhance the efficiency of mixed-modal, early-fusion language model pre-training.
MoMa’s innovative architecture represents a significant advancement in multimodal AI. By integrating modality-specific experts and advanced routing techniques, the researchers have developed a more resource-efficient AI model that maintains high performance across diverse tasks. This innovation addresses critical computational efficiency issues, paving the way for developing more capable and resource-effective multimodal AI systems. The team’s work demonstrates the potential for future research to build upon these foundations, exploring more sophisticated routing mechanisms and extending the approach to additional modalities and tasks.
In summary, the MoMa architecture, developed by Meta researchers, offers a promising solution to the computational challenges in multimodal AI. The approach leverages modality-aware mixture-of-experts and mixture-of-depths techniques to achieve significant efficiency gains while maintaining robust performance. This breakthrough paves the way for the next generation of multimodal AI models, which can process and integrate diverse data types more effectively and efficiently, enhancing AI’s capability to understand and interact with the complex, multimodal world we live in.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post This AI Paper by Meta FAIR Introduces MoMa: A Modality-Aware Mixture-of-Experts Architecture for Efficient Multimodal Pre-training appeared first on MarkTechPost.
