


关键词:开放词汇操作; 物体交互基元; 机器人操作

导 读
本文是对发表于计算机人工智能领域顶级会议 CVPR 2025 的论文 OmniManip: Towards General Robotic Manipulation via Object-Centric Interaction Primitives as Spatial Constraints 的解读。该论文由北京大学董豪课题组完成,共同第一作者为北京大学计算机学院博士生潘铭杰和张继耀。
本文提出了一种基于多模态大模型的开放词汇操作方法,通过以物体为中心的 3D 交互基元,赋能 VLM(视觉语言模型)3D 理解与推理能力,使机器人能够免训练、零样本地执行多项操作任务。与先前基于关键点、线、面等交互基元的工作不同,OmniManip 能够通过物体 3D 渲染和姿态跟踪达成规划-执行层面的双闭环,实现了操作性能的显著突破。文章在 CVPR 2025 中作为 Highlight 发表。
项目主页:
https://omnimanip.github.io
论文地址:
https://arxiv.org/abs/2501.03841
文章代码:
https://github.com/pmj110119/OmniManip
01
研究背景
近年来视觉语言基础模型(Vision Language Models, VLMs)在多模态理解和高层次常识推理上⼤放异彩,如何将其应用于机器⼈以实现通用操作是具身智能领域的⼀个核心问题。这⼀目标的实现受两⼤关键挑战制约:
VLM 缺少精确的 3D 理解能力:通过对比学习范式训练、仅以 2D 图像 / 文本作为输⼊的 VLM 的天然局限;
无法输出低层次动作:将 VLM 在机器⼈数据上进行微调以得到视觉 - 语言 - 动作(VLA)模型是⼀种有前景的解决方案,但目前仍受到数据收集成本和泛化能力的限制。
针对上述难题,OmniManip 基于以对象为中心的 3D 交互基元,赋能 VLM 3D 理解与规划能力,并通过创新性的规划-执行双闭环设计实现了操作性能的显著突破。
实验结果表明,OmniManip 作为⼀种免训练的开放词汇操作方法,在各种机器人操作任务中具备强大的零样本泛化能⼒。
02
技术方案解析
方法概述
OmniManip 的关键设计包括:
基于 VLM 的任务解析:利用 VLM 强⼤的常识推理能力,将任务分解为多个结构化阶段(Stages),每个阶段明确指定了主动物体(Active)、被动物体(Passive)和动作类型(Action)。
以物体为中心的交互基元作为空间约束:通过 3D 基座模型生成任务相关物体的 3D 模型和规范化空间(canonical space),使 VLM 能够直接在该空间中采样 3D 交互基元,作为 Action 的空间约束,从而优化求解出 Active 物体在 Passive 物体规范坐标系下的目标交互姿态。
闭环 VLM 规划:将目标交互姿态下的 Active/Passive 物体渲染成图像,由 VLM 评估与重采样,实现 VLM 对自身规划结果的闭环调整。
闭环机器人执行:通过物体 6D 姿态跟踪器实时更新 Active/Passive 物体的位姿,转换为机械臂末端执行器的操作轨迹,实现闭环执行。
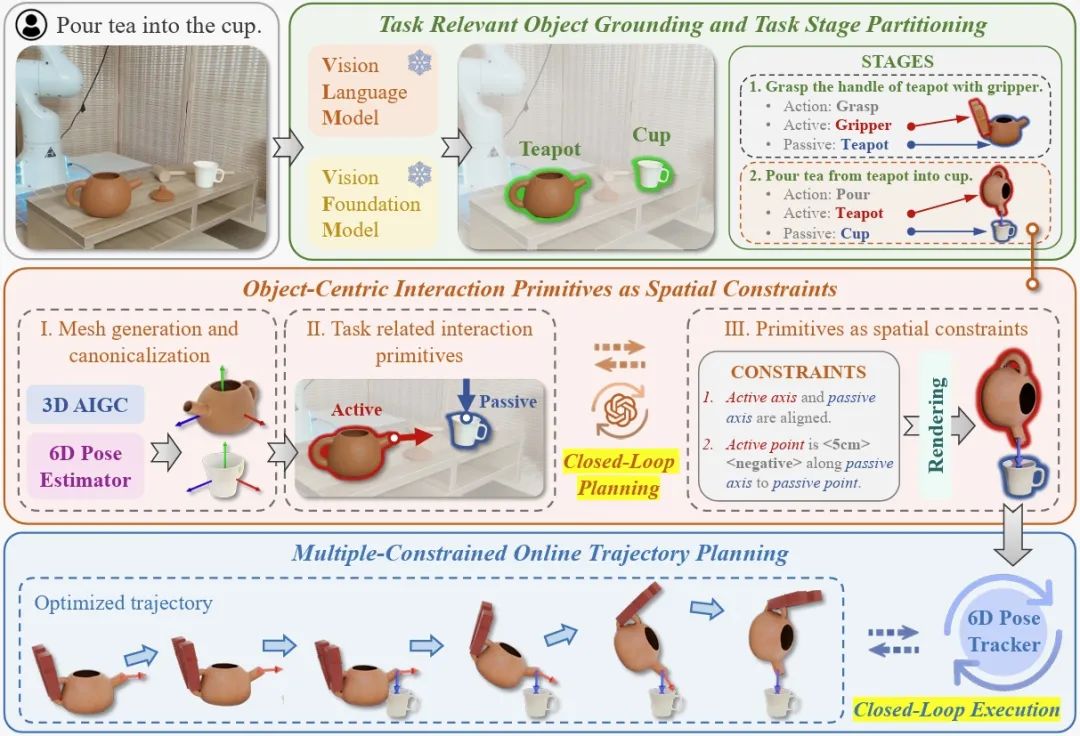
以物体为中心的交互基元
物体的交互基元通过其在标准空间中的交互点和方向来表征。交互点 p∈R3 表示物体上关键的交互位置,而交互方向 v∈R3 代表与任务相关的主要轴。这两者共同构成交互基元 O={p,v},封装了满足任务约束所需的基本几何和功能属性。这些标准交互基元相对于其标准空间定义,能够在不同场景中保持⼀致,实现更通用和可重用的操作策略。
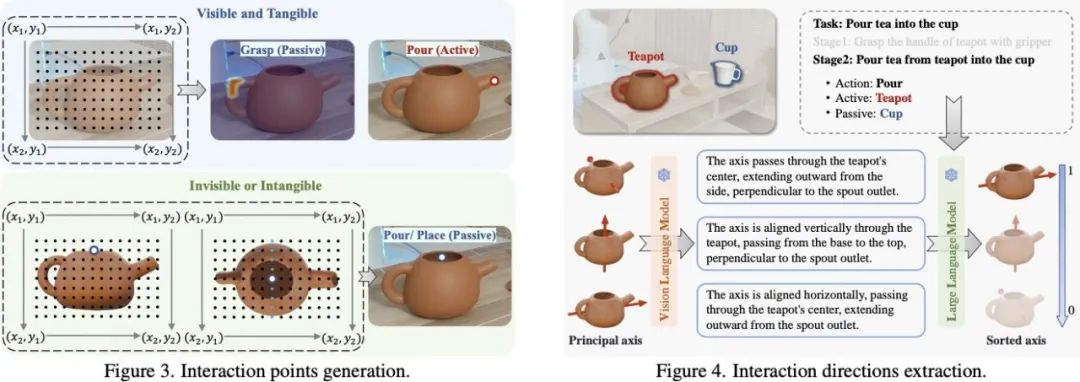
对于通用物体的交互点提取,OmniManip 利用视觉语⾔模型(VLM)在原图(当部件可见且实体存在时)或在正交视图中渲染的 3D 网格(当部件不可见或实体不存在时)上进行定位。
与 CoPa 和 ReKep 等方法不同,OmniManip 直接让 VLM 进行 grounding,不会受限于不稳定的 part 分割或聚类结果。
在交互方向的采样方面,由于物体的规范化空间通过 Omni6DPose 锚定,轴的方向与语义对齐,该团队让 VLM 直接对物体标准空间的轴进行语义描述,并根据操作任务进行匹配度排序,以获得交互方向的候选。
双闭环系统设计
作为最新的 SOTA 工作,李飞飞团队的 ReKep 通过关键点跟踪巧妙地实现了机械臂的闭环执行,但其 VLM 规划过程是开环的。OmniManip 则更进⼀步,得益于以物体为中心的设计理念,首次在 VLM 规划和机械臂执⾏层⾯实现了双闭环系统:
闭环规划:在实验中,VLM 推理很容易出现幻觉,导致错误的规划结果(尤其是在涉及 3D 旋转的任务中,如倒水、插笔)。OmniManip 赋予 VLM 闭环规划能⼒,通过渲染物体的三维模型,帮助 VLM 「脑补」出规划结果后的物体样貌,再判断其合理性。
这⼀功能赋予了 VLM 空间反思能力,使其能够在测试时进行推理,类似于 OpenAI 的 O1,大大提高了操作成功率。为了保持框架的简洁性,研究团队没有设计复杂的测试时推理流程,仅作⼀轮校验就已明显提高了 VLM 的规划准确率。
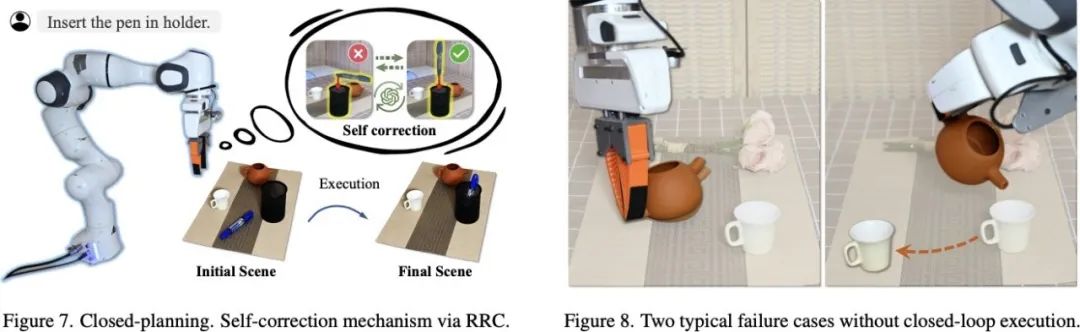
闭环执行:OmniManip 提取的交互基元位于物体的规范空间中,只需引入⼀个 6D 位姿跟踪器即可轻松实现闭环操作。与 ReKep 使用的关键点跟踪器相比,基于物体的 6D 位姿跟踪方式更为稳定,并对遮挡具有更强的鲁棒性。(缺点则是不如关键点灵活、无法建模柔性物体操作。)
03
实验结果
强大的开放词汇操作性能
在12个真机短程任务上,OmniManip 均展现出卓越的性能。
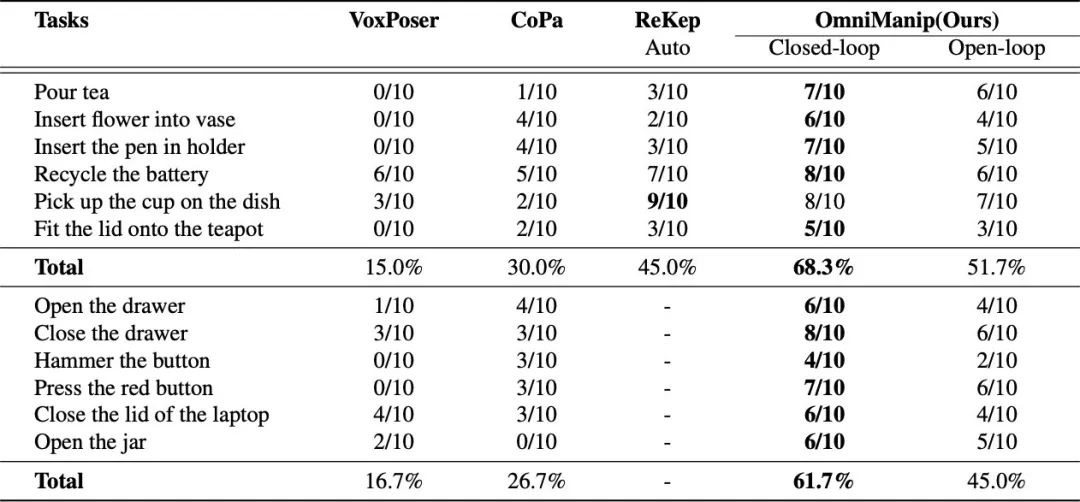
双闭环系统设计为 OmniManip 带来了约 17% 的性能提升,这证明了 RRC 在有效减少⼤模型幻觉影响⽅⾯的作用。
交互基元的鲁棒性
VLM 需要基于交互基元对机器⼈操作进行规划,如果交互基元本身存在问题,VLM 就会陷入「巧妇难为无米之炊」的困境。因此,可靠的交互基元至关重要。以往的方法通常是让 VLM 直接在相机拍摄的 2D 图像上采样交互基元,然后通过相机的内外参数转换到 3D 空间。
然而,由于 2D 图像存在空间歧义,采样效果对相机视⻆、图像纹理和部件形状等因素极为敏感(例如,当相机平视杯子时,之前的方法只能对准杯子的侧壁、而不是开口)。而 OmniManip 则是在物体的 3D 规范空间中进行采样,能够轻松克服 2D 图像的局限性,实现可靠的 3D 交互基元提取。

强大的拓展性与潜力
OmniManip 能够与 high-level 任务规划器结合,实现长程任务操作。
作为⼀种以物体为中心的算法,OmniManip 与机械臂本体解耦,能够零成本迁移至不同形态的本体(例如双臂⼈形机器⼈)。
OmniManip 具有强⼤的通用泛化能力,不受特定场景和物体限制,可用作数字资产⾃动标注 / 合成管道。作为核心的数据生成引擎,OmniManip 已被应用于最近开源的 AgibotDigitalWorld 数据集[1],实现大规模的机器人轨迹自动采集。
04
总 结
本文提出了一种基于多模态大模型的开放词汇操作方法 OmniManip,通过以物体为中心的 3D 交互基元,创新性的规划-执行双闭环设计,使机器人能够免训练、零样本地执行多项操作任务。
OmniManip 在多个任务上超越了现有方法,展现出了强大的泛化性和稳定性,为未来的机器人自主操作提供了一种强大的工具。
[1] AgibotDigitalWorld 数据集:
https://huggingface.co/datasets/agibot-world/AgiBotDigitalWorld
PKU-Agibot Lab
PKU-Agibot Lab 由北京大学前沿计算研究中心董豪助理教授领导,该科研团队专注于机器人视觉,物体操作,语义导航和具身自主决策等领域的前沿技术,致力于为工业应用和家用场景创建具有成本效益的人形机器人。
实验室 PI 简介:董豪 助理教授
董豪课题组相关新闻:#PKU-Agibot Lab

扫码浏览实验室主页
https://zsdonghao.github.io/

图文 | 潘铭杰
PKU-Agibot Lab
PKU-Agibot Lab 近期科研动态


— 版权声明 —
本微信公众号所有内容,由北京大学前沿计算研究中心微信自身创作、收集的文字、图片和音视频资料,版权属北京大学前沿计算研究中心微信所有;从公开渠道收集、整理及授权转载的文字、图片和音视频资料,版权属原作者。本公众号内容原作者如不愿意在本号刊登内容,请及时通知本号,予以删除。

点击“阅读原文”转论文链接
内容中包含的图片若涉及版权问题,请及时与我们联系删除
