

Meta 创始人兼首席执行官马克·扎克伯格今日在其 Instagram 账号宣布推出全新 Llama 4 系列模型,其中两款——参数高达 400B 亿的 Llama 4 Maverick 和 109B 亿参数的 Llama 4 Scout——即日起可供开发者在 llama.com 及 AI 代码共享社区 Hugging Face 上下载,即刻开始使用或微调。
今天还预览了一款拥有 2 万亿参数的巨无霸模型 Llama 4 Behemoth,不过 Meta 的发布博文称其仍在训练中,并未透露何时可能发布。
按照官推的说法这次发布是对 Llama 系列的一次彻底重新设计
先划重点:
核心变化:Llama 4 全系采用混合专家(MoE)架构,并且是原生多模态训练,不再是 Llama 3 那样的纯文本模型了。这次发布了 Llama 4 Scout 和 Llama 4 Maverick,同时还有最强大的 Llama 4 Behemoth预览
另一个特点是它们拥有超长的上下文窗口——Llama 4 Maverick 支持 100 万 token,Llama 4 Scout 更是高达 1000 万 token,分别相当于约 1500 页和 1.5 万页文本,且模型能在单次输入/输出交互中处理全部内容。这意味着理论上用户可向 Llama 4 Scout 上传或粘贴多达 7500 页的文本,并获取同等体量的反馈,这对医学、科学、工程、数学、文学等知识密集型领域尤为实用。
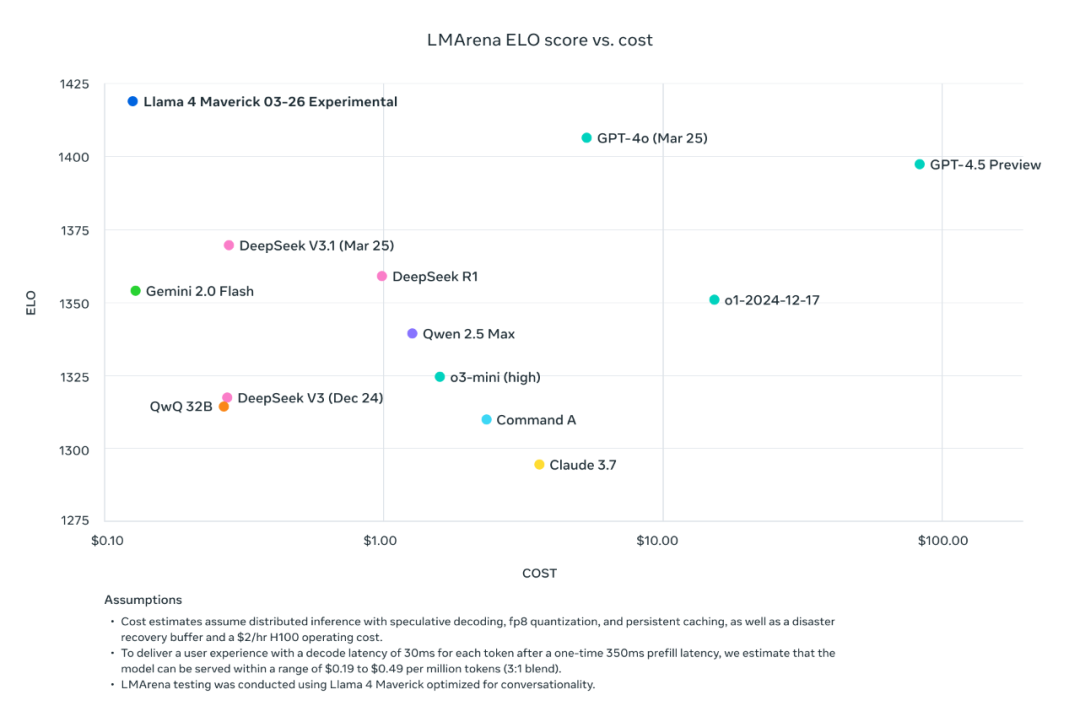
Meta 估计 Llama 4 Maverick 的推理成本为每 100 万 token 0.19 至 0.49 美元(采用输入与输出 3:1 的比例)。这使得它比专有模型如 GPT-4o 便宜得多,根据社区基准,GPT-4o 的成本估计为每百万 token 4.38 美元。
文章部分内容转载自「AI 寒武纪」。

高浓度的主流模型(如 DeepSeek 等)开发交流;
资源对接,与 API、云厂商、模型厂商直接交流反馈的机会;
01
三种参数,MoE 模型
下面给大家第一时间做个梳理,
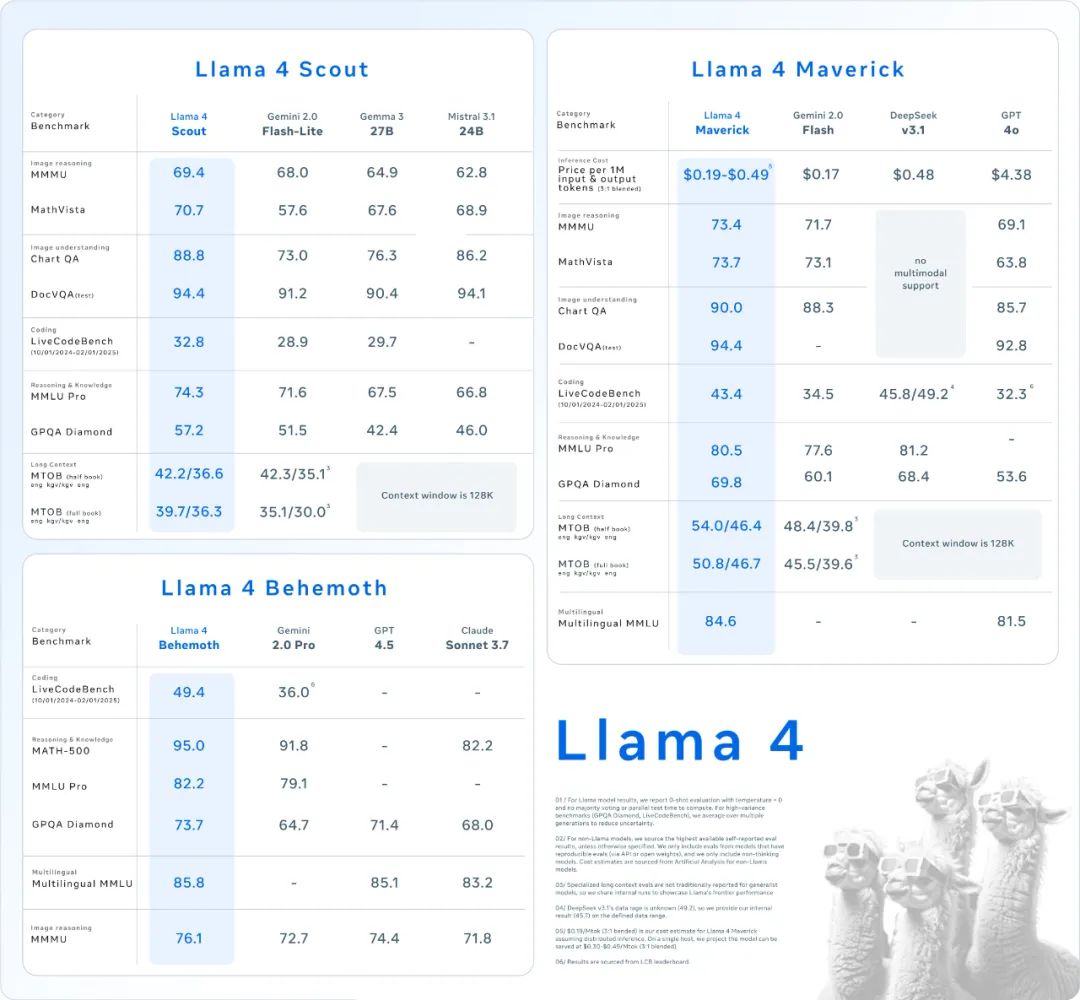
📌 Llama 4 Scout:
定位:性能最强的小尺寸模型
参数:17B 激活参数,16 个专家,总参数量 109B
亮点:速度极快,原生支持多模态,拥有业界领先的 1000 万+ Token 多模态上下文窗口(相当于处理 20 多个小时的视频!),并且能在单张 H100 GPU 上运行(Int4 量化后)
📌 Llama 4 Maverick:
定位:同级别中最佳的多模态模型
性能:在多个主流基准测试中击败了 GPT-4o 和 Gemini 2.0 Flash,推理和编码能力与新发布的 DeepSeek v3 相当,但激活参数量不到后者一半
参数:17B 激活参数,128 个专家,总参数量 400B,上下文窗口 100 万+
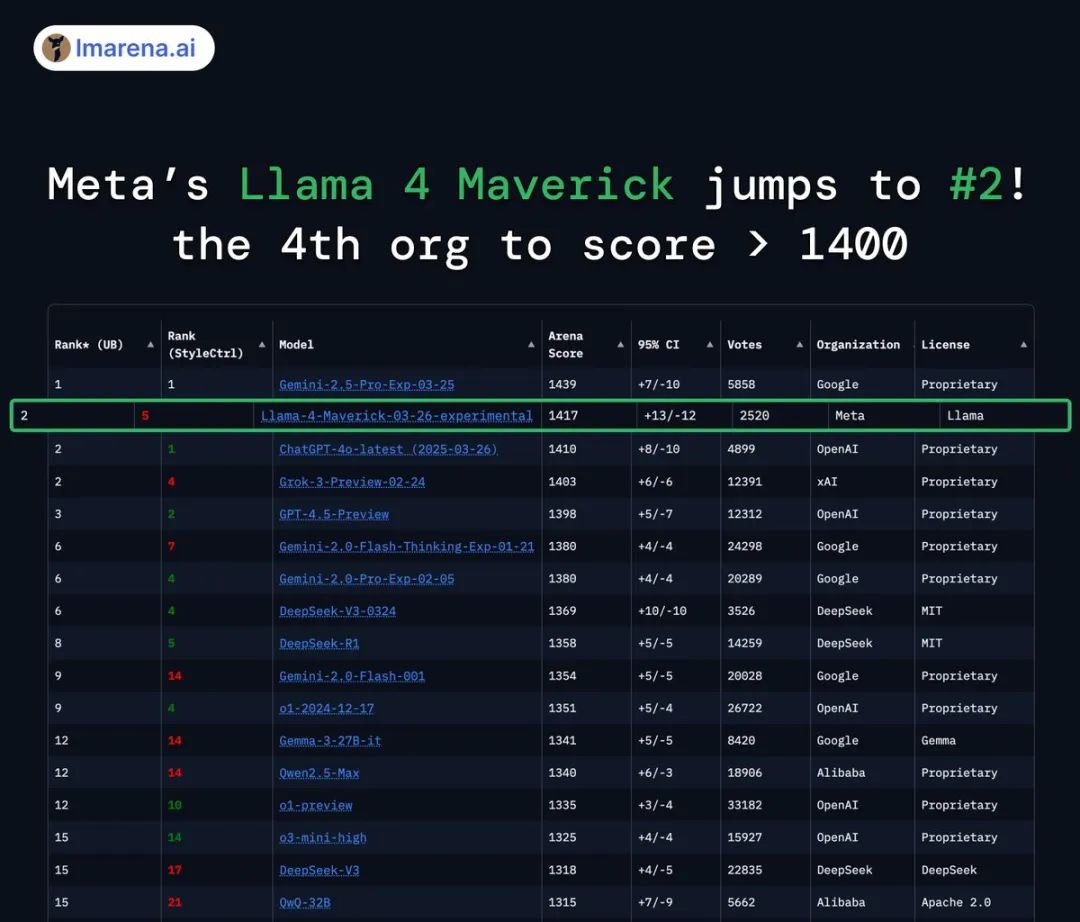
性价比:提供了同类最佳的性能成本比。其实验性聊天版本在 LMArena 上 ELO 评分达到 1417,排名第二
部署:可以在单个主机上运行
📌 Llama 4 Behemoth (预览,训练中):
定位:Meta 迄今最强模型,全球顶级 LLM 之一
性能:在多个 STEM 基准上优于 GPT-4.5、Claude Sonnet 3.7 和 Gemini 2.0 Pro
参数:288B 激活参数,16 个专家,总参数量高达2万亿 (2T)
训练细节:使用 FP8 精度,在 32000 块 GPU 上训练了 30 万亿 多模态 Token
角色:作为 Maverick 模型进行代码蒸馏时的教师模型
原生多模态:所有模型都采用早期融合(early fusion)策略,将文本、图像、视频 Token 无缝整合到统一的模型骨干中
训练流程优化:采用了 轻量级 SFT → 在线 RL → 轻量级 DPO 的后训练流程。开发者强调,过度使用 SFT/DPO 会过度约束模型,限制在线 RL 阶段的探索能力,所以要保持“轻量”
超长上下文的秘密 (10M+):实现这一突破的关键是 iRoPE 架构('i' 代表 interleaved layers, infinite)
核心思想:通过追求无限上下文的目标来指导架构设计,特别是利用长度外推能力——在短序列上训练,泛化到极长序列。最大训练长度是 256K
具体做法:
xq *= 1 + log(floor(i / α) + 1) * β(i 是位置索引)使用最高参数模型基准——Llama 4 Behemoth——并将其与 DeepSeek R1 初始发布时的 R1-32B 和 OpenAI o1 模型图表进行对比,以下是 Llama 4 Behemoth 的表现情况:
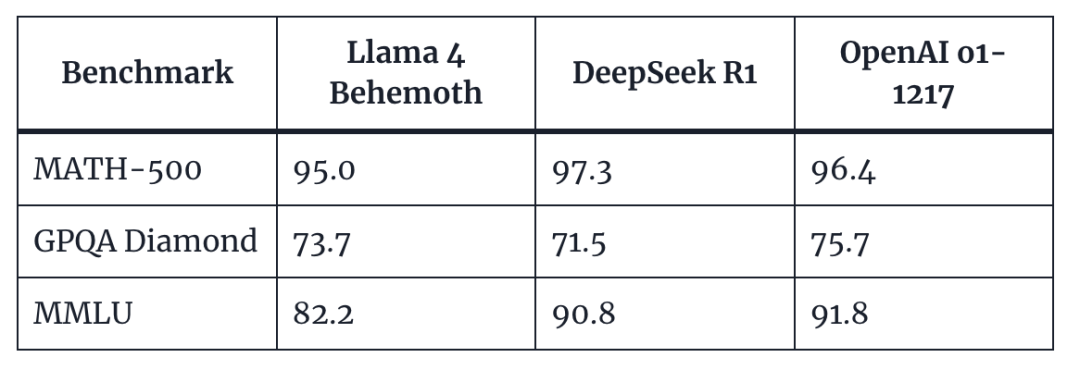
我们能得出什么结论?
MATH-500:Llama 4 Behemoth 略微落后于 DeepSeek R1 和 OpenAI o1。
GPQA Diamond:Behemoth 领先于 DeepSeek R1,但落后于 OpenAI o1。
MMLU:Behemoth虽落后于两者,但仍优于 Gemini 2.0 Pro 和 GPT-4.5。
要点:尽管 DeepSeek R1 和 OpenAI o1 在几项指标上略胜 Behemoth 一筹,Llama 4 Behemoth 仍极具竞争力,在其类别的推理排行榜上表现位居或接近榜首。
这次Llama 4的推理模型还不见踪影,这多少有点说不过去,大家觉得呢?毕竟Meta也是妥妥的大厂啊!不过Meta 表示这只是开始,后续还有更多模型,团队正在全力开发中,特别提到了 Llama 4 Reasoning 模型
另外相比于DeepSeek的MIT开源方式,Llama 4 的新许可证有几个限制:
- 每月活跃用户超过 7 亿的公司必须向 Meta 申请特殊许可,Meta 可自行决定授予或拒绝该许可。
- 必须在网站、界面、文档等处突出显示“使用 Llama 构建”。
- 使用 Llama Materials 创建的任何 AI 模型的名称开头都必须包含“Llama”
- 必须在任何分发的“通知”文本文件中包含具体的归属通知 - 使用必须遵守 Meta 单独的可接受使用政策(参考 http://llama.com/llama4/use-policy...) - 仅出于符合品牌要求的有限许可使用“Llama”名称
参考:
https://ai.meta.com/blog/llama-4-multimodal-intelligence/
https://venturebeat.com/ai/metas-answer-to-deepseek-is-here-llama-4-launches-with-long-context-scout-and-maverick-models-and-2t-parameter-behemoth-on-the-way/

转载原创文章请添加微信:founderparker
