
Published on March 27, 2025 9:47 PM GMT
This eLife paper The value of initiating a pursuit in temporal decision-making by Elissa Sutlief, Charlie Walters, Tanya Marton, and Marshall G Hussain Shuler, seems to dissolve the question of the choice of temporal discount functions by explaining how it results from time-varying reward probabilities. It provides a framework to interpret decision heuristics as (mis)estimates of key parameters in this framework.
Abstract:
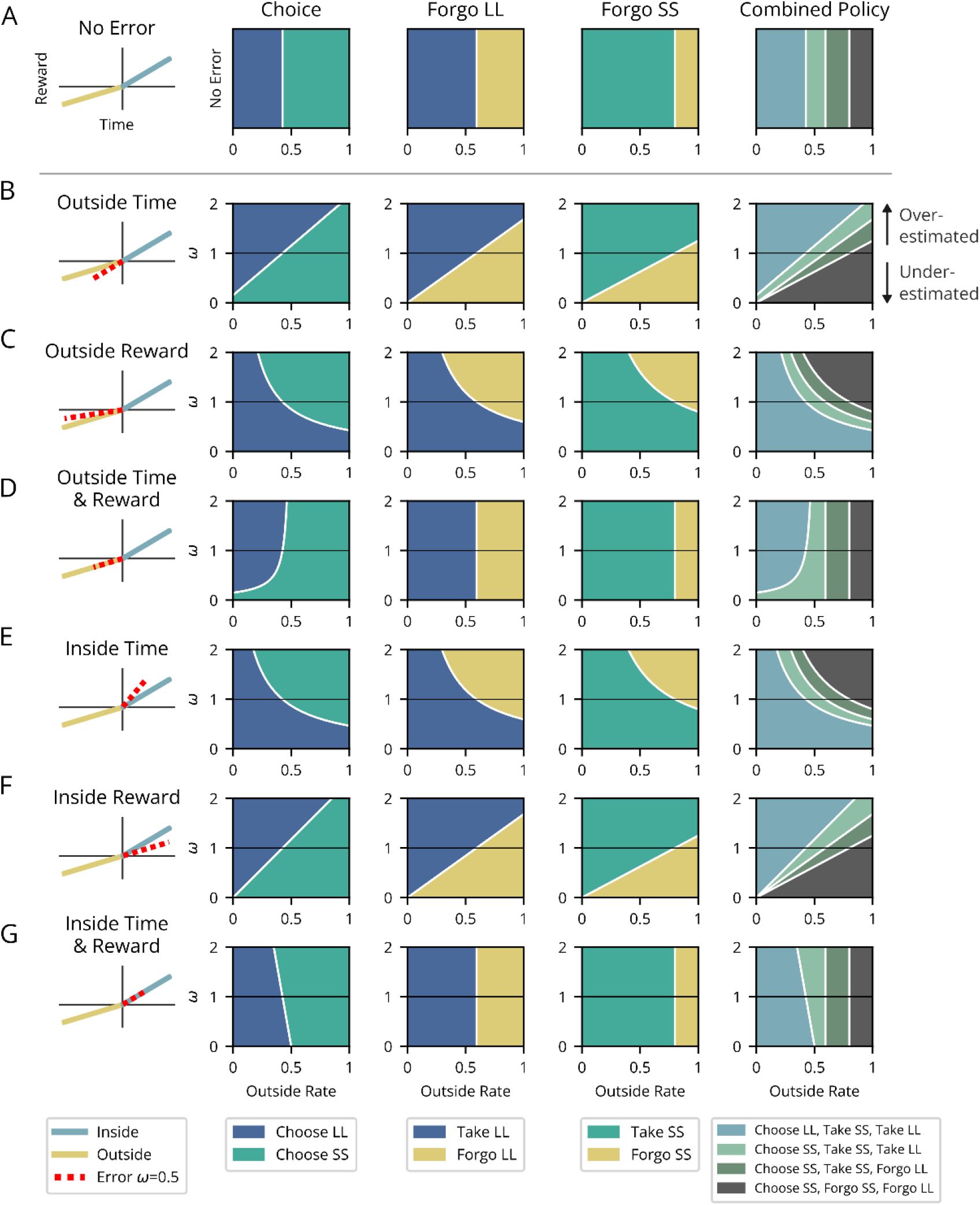
Reward-rate maximization is a prominent normative principle commonly held in behavioral ecology, neuroscience, economics, and artificial intelligence. Here, we identify and compare equations for evaluating the worth of initiating pursuits that an agent could implement to enable reward-rate maximization. We identify two fundamental temporal decision-making categories requiring the valuation of the initiation of a pursuit—forgo and choice decision-making—over which we generalize and analyze the optimal solution for how to evaluate a pursuit in order to maximize reward rate. From this reward-rate-maximizing formulation, we derive expressions for the subjective value of a pursuit, i.e. that pursuit’s equivalent immediate reward magnitude, and reveal that time’s cost is composed of an apportionment, in addition to, an opportunity cost. By re-expressing subjective value as a temporal discounting function, we show precisely how the temporal discounting function of a reward-rate-optimal agent is sensitive not just to the properties of a considered pursuit, but to the time spent and reward acquired outside of the pursuit for every instance spent within it. In doing so, we demonstrate how the apparent discounting function of a reward-rate-optimizing agent depends on the temporal structure of the environment and is a combination of hyperbolic and linear components, whose contributions relate the apportionment and opportunity cost of time, respectively. We further then show how purported signs of suboptimal behavior (hyperbolic discounting, the Delay effect, the Magnitude effect, the Sign effect) are in fact consistent with reward-rate maximization. Having clarified what features are and are not signs of optimal decision-making, we analyze the impact of the misestimation of reward rate-maximizing parameters in order to better account for the pattern of errors actually observed in humans and animals. We find that error in agents’ assessment of the apportionment of time that underweights the time spent outside versus inside a considered pursuit type is the likely driver of suboptimal temporal decision-making observed behaviorally. We term this the Malapportionment Hypothesis. This generalized form for reward-rate maximization and its relation to subjective value and temporal discounting allows the true pattern of errors exhibited by humans and animals to be more deeply understood, identified, and quantified, which is key to deducing the learning algorithms and representational architectures actually used by humans and animals to evaluate the worth of pursuits.
Discuss
