


Recent advancements in RL for LLMs, such as DeepSeek R1, have demonstrated that even simple question-answering tasks can significantly enhance reasoning capabilities. Traditional RL approaches for LLMs often rely on single-turn tasks, where a model is rewarded based on the correctness of a single response. However, these methods suffer from sparse rewards and fail to train models to refine their responses based on user feedback. To address these limitations, multi-turn RL approaches have been explored, allowing LLMs to make multiple attempts at solving a problem, thus improving their reasoning and self-correction abilities.
Several prior studies have investigated planning and self-correction mechanisms in RL for LLMs. Inspired by the Thinker algorithm, which enables agents to explore alternatives before taking action, some approaches enhance LLM reasoning by allowing multiple attempts rather than learning a world model. Methods such as SCoRe train LLMs on multi-attempt tasks but lack verification of prior responses using ground-truth rewards, necessitating complex calibration. Other works focus on self-correction using external tools, such as Reflexion for self-reflection and CRITIC for real-time feedback. Unlike these approaches, the proposed method extends DeepSeek R1’s single-turn question-answering task into a multi-attempt framework, leveraging historical errors to refine responses and enhance reasoning.
DualityRL and Shanghai AI Lab researchers introduce a multi-attempt RL approach to enhance reasoning in LLMs. Unlike single-turn tasks, this method allows models to refine responses through multiple attempts with feedback. Experimental results show a 45.6% to 52.5% accuracy improvement with two attempts on math benchmarks, compared to a marginal gain in single-turn models. The model learns self-correction using Proximal Policy Optimization (PPO), leading to emergent reasoning capabilities. This multi-attempt setting facilitates iterative refinement, promoting deeper learning and problem-solving skills, making it a promising alternative to conventional RLHF and supervised fine-tuning techniques.
In a single-turn task, an LLM generates a response to a question sampled from a dataset, optimising its policy to maximise rewards based on answer correctness. In contrast, the multi-turn approach allows iterative refinement, where responses influence subsequent prompts. The proposed multi-attempt task introduces a fixed number of attempts, prompting retries if the initial response is incorrect. The model gets a reward of +1 for correct answers, -0.5 for incorrect but well-formatted responses, and -1 otherwise. This approach encourages exploration in early attempts without penalties, leveraging PPO for optimisation, enhancing reasoning through reinforcement learning.
The study fine-tunes the Qwen 2.5 Math 1.5B model on 8K math questions using PPO with γ = 1, λ = 0.99, and a KL divergence coefficient of 0.01. Training spans 160 episodes, generating 1.28M samples. In the multi-attempt setting, attempts are sampled from {1, …, 5}, while the baseline follows a single-turn approach. Results show the multi-attempt model achieves higher rewards and slightly better evaluation accuracy. Notably, it refines responses effectively, improving accuracy from 45.58% to 53.82% over multiple attempts. This adaptive reasoning capability could enhance performance in code generation and problem-solving fields.
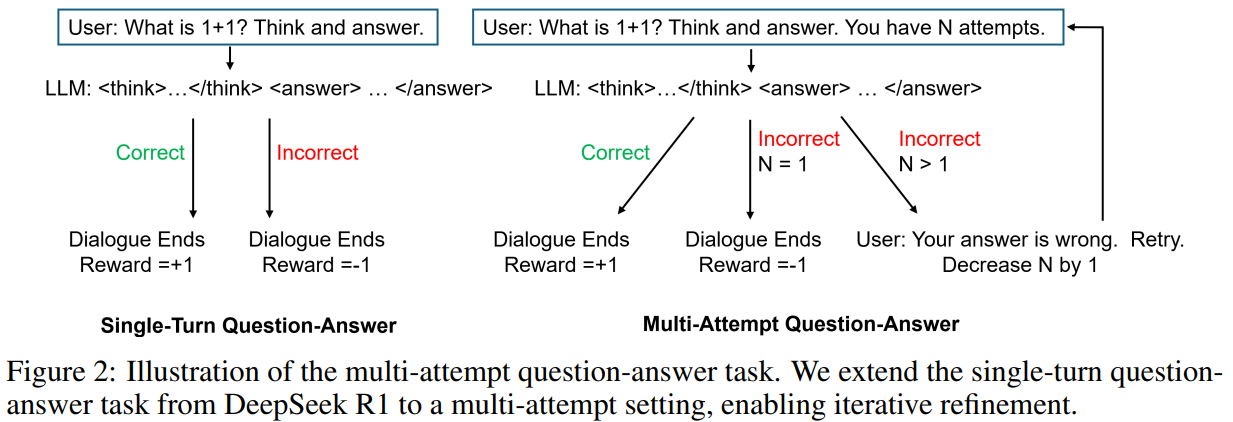
In conclusion, the study builds on DeepSeek R1’s question-answering task by introducing a multi-attempt mechanism. While performance gains on math benchmarks are modest, the approach significantly improves the model’s ability to refine responses based on feedback. The model, trained to iterate on incorrect answers, enhances search efficiency and self-correction. Experimental results show that accuracy improves from 45.6% to 52.5% with two attempts, whereas a single-turn model only slightly increases. Future work could further explore incorporating detailed feedback or auxiliary tasks to enhance LLM capabilities, making this approach valuable for adaptive reasoning and complex problem-solving tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.


 It’s operated using an easy-to-use CLI
It’s operated using an easy-to-use CLI  and native client SDKs in Python and TypeScript
and native client SDKs in Python and TypeScript  .
.The post Enhancing LLM Reasoning with Multi-Attempt Reinforcement Learning appeared first on MarkTechPost.
