

The rapid growth of large language models (LLMs) and their increasing computational requirements have prompted a pressing need for optimized solutions to manage memory usage and inference speed. As models like GPT-3, Llama, and other large-scale architectures push the limits of GPU capacity, efficient hardware utilization becomes crucial. High memory requirements, slow token generation, and limitations in memory bandwidth have all contributed to significant performance bottlenecks. These problems are particularly noticeable when deploying LLMs on NVIDIA Hopper GPUs, as balancing memory usage and computational speed becomes more challenging.
Neural Magic introduces Machete: a new mixed-input GEMM kernel for NVIDIA Hopper GPUs, representing a major advancement in high-performance LLM inference. Machete utilizes w4a16 mixed-input quantization to drastically reduce memory usage while ensuring consistent computational performance. This innovative approach allows Machete to reduce memory requirements by roughly 4x in memory-bound environments. When compared to FP16 precision, Machete matches compute-bound performance while greatly improving efficiency for memory-constrained deployments. As LLMs continue to expand in scope, addressing memory bottlenecks with practical solutions like Machete becomes essential for enabling smoother, faster, and more efficient model inference.

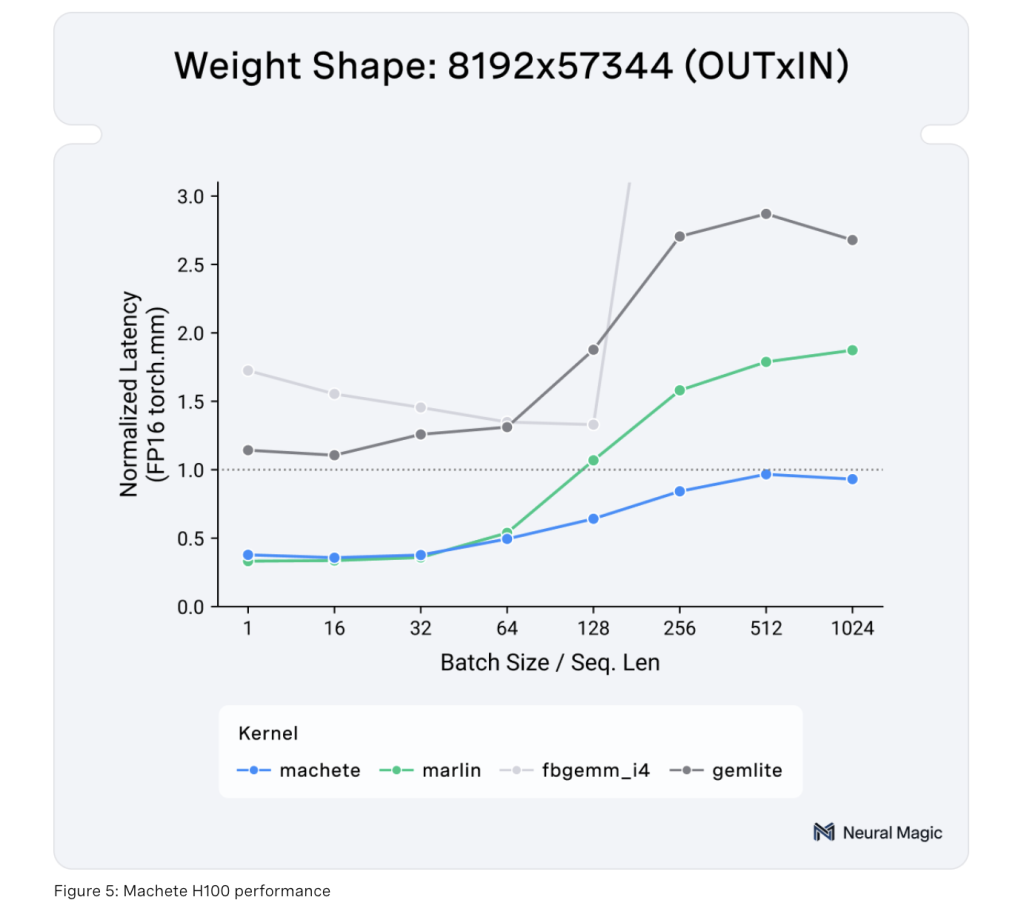
One of Machete’s key innovations lies in its technical implementation. Built on CUTLASS 3.5.1, Machete leverages the wgmma tensor core instructions to overcome compute-bound limitations, resulting in faster model inference. It also incorporates weight pre-shuffling, which allows for faster-shared memory loads, effectively mitigating bottlenecks that typically arise in large-scale LLMs. This weight pre-shuffling mechanism optimizes shared memory by allowing 128-bit loads, increasing throughput and reducing latency. In addition, Machete has improved upconversion routines that facilitate efficient conversion of 4-bit elements to 16-bit, maximizing tensor core utilization. Together, these innovations make Machete an effective solution for improving LLM performance without the overhead typically associated with increased precision or additional computational costs.
The importance of Machete cannot be overstated, particularly in the context of the growing demand for LLM deployments that are both memory and compute-efficient. By reducing memory usage by around fourfold, Machete helps ensure that even the largest LLMs, such as Llama 3.1 70B and Llama 3.1 405B, can be run efficiently on available hardware. In testing, Machete achieved notable results, including a 29% increase in input throughput and a 32% faster output token generation rate for Llama 3.1 70B, with an impressive time-to-first-token (TTFT) of under 250ms on a single H100 GPU. When scaled to a 4xH100 setup, Machete delivered a 42% throughput speedup on Llama 3.1 405B. These results demonstrate not only the significant performance boost provided by Machete but also its capacity to scale efficiently across different hardware configurations. The support for upcoming optimizations, such as w4a8 FP8, AWQ, QQQ, and improved performance for low-batch-size operations, further solidifies Machete’s role in pushing the boundaries of efficient LLM deployment.
In conclusion, Machete represents a meaningful step forward in optimizing LLM inference on NVIDIA Hopper GPUs. By addressing the critical bottlenecks of memory usage and bandwidth, Machete has introduced a new approach to managing the demands of large-scale language models. Its mixed-input quantization, technical optimizations, and scalability make it an invaluable tool for improving model inference efficiency while reducing computational costs. The impressive gains demonstrated on Llama models show that Machete is poised to become a key enabler of efficient LLM deployments, setting a new standard for performance in memory-constrained environments. As LLMs continue to grow in scale and complexity, tools like Machete will be essential in ensuring that these models can be deployed efficiently, providing faster and more reliable outputs without compromising on quality.
Check out the Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post Neural Magic Unveils Machete: A New Mixed-Input GEMM Kernel for NVIDIA Hopper GPUs appeared first on MarkTechPost.
