


Optimizing large-scale language models demands advanced training techniques that reduce computational costs while maintaining high performance. Optimization algorithms are crucial in determining training efficiency, particularly in large models with extensive parameter counts. While optimizers like AdamW have been widely adopted, they often require meticulous hyperparameter tuning and high computational resources. Finding a more efficient alternative that ensures training stability while reducing compute requirements is essential for advancing large-scale model development.
The challenge of training large-scale models stems from increased computational demands and the necessity for effective parameter updates. Many existing optimizers exhibit inefficiencies when scaling to larger models, requiring frequent adjustments that prolong training time. Stability issues, such as inconsistent model updates, can further degrade performance. A viable solution must address these challenges by enhancing efficiency and ensuring robust training dynamics without demanding excessive computational power or tuning efforts.
Existing optimizers like Adam and AdamW rely on adaptive learning rates and weight decay to refine model performance. While these methods have demonstrated strong results in various applications, they become less effective as models scale. Their computational demands increase significantly, making them inefficient for large-scale training. Researchers have been investigating alternative optimizers that offer improved performance and efficiency, eliminating the need for extensive hyperparameter tuning while achieving stable and scalable results.
Researchers at Moonshot AI and UCLA introduced Muon, an optimizer developed to overcome the limitations of existing methods in large-scale training. Initially proven effective in small-scale models, Muon faced challenges in scaling up. To address this, researchers implemented two core techniques: weight decay for enhanced stability and consistent root mean square (RMS) updates to ensure uniform adjustments across different parameters. These enhancements allow Muon to operate efficiently without requiring extensive hyperparameter tuning, making it a powerful choice for training large-scale models out of the box.
Building upon these advancements, researchers introduced Moonlight, a Mixture-of-Experts (MoE) model in 3B and 16B parameter configurations. Trained with 5.7 trillion tokens, Moonlight leveraged Muon to optimize performance while reducing computational costs. A distributed version of Muon was also developed using ZeRO-1 style optimization, improving memory efficiency and minimizing communication overhead. These refinements resulted in a stable training process, allowing Moonlight to achieve high performance with significantly lower computational expenditure than previous models.
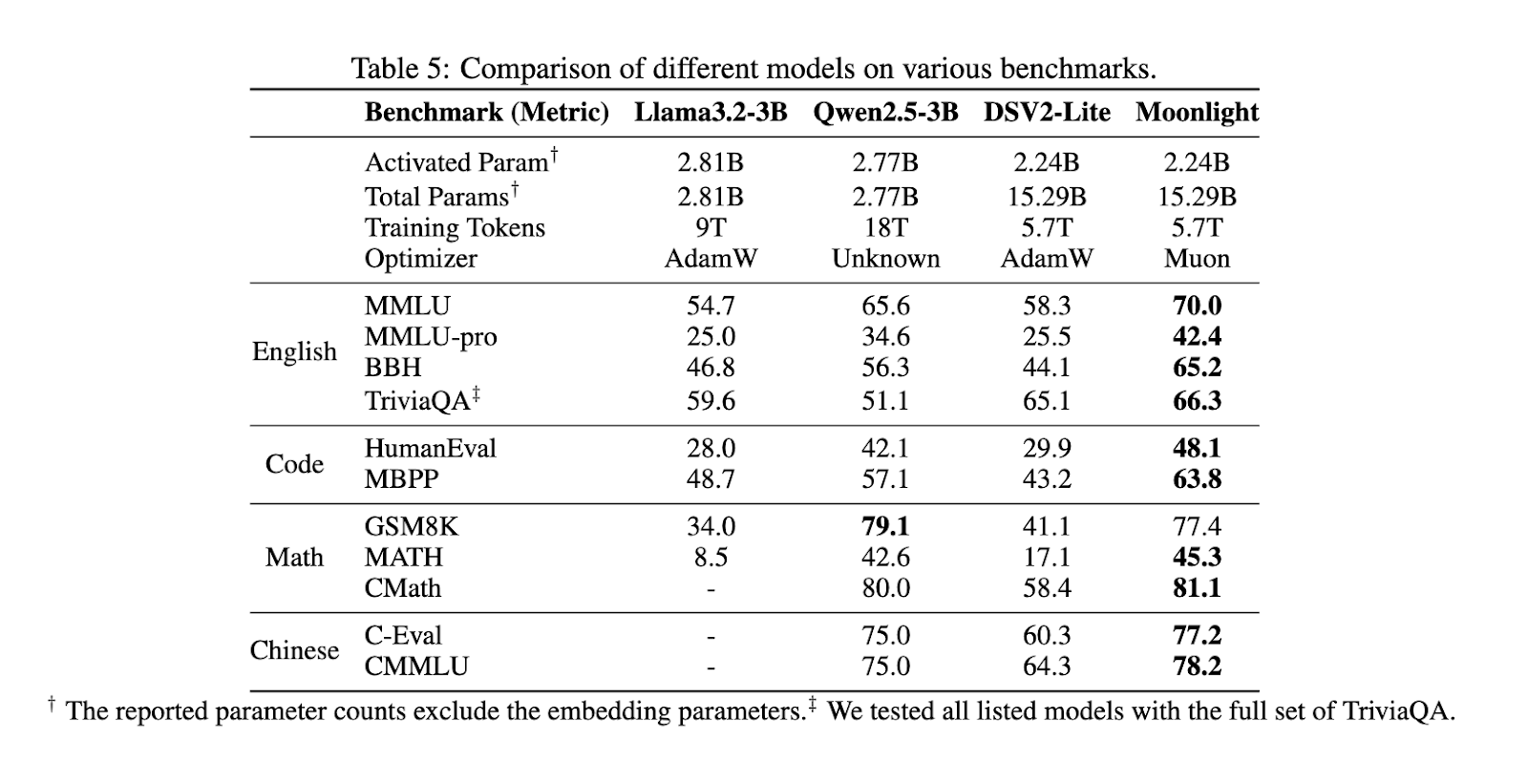
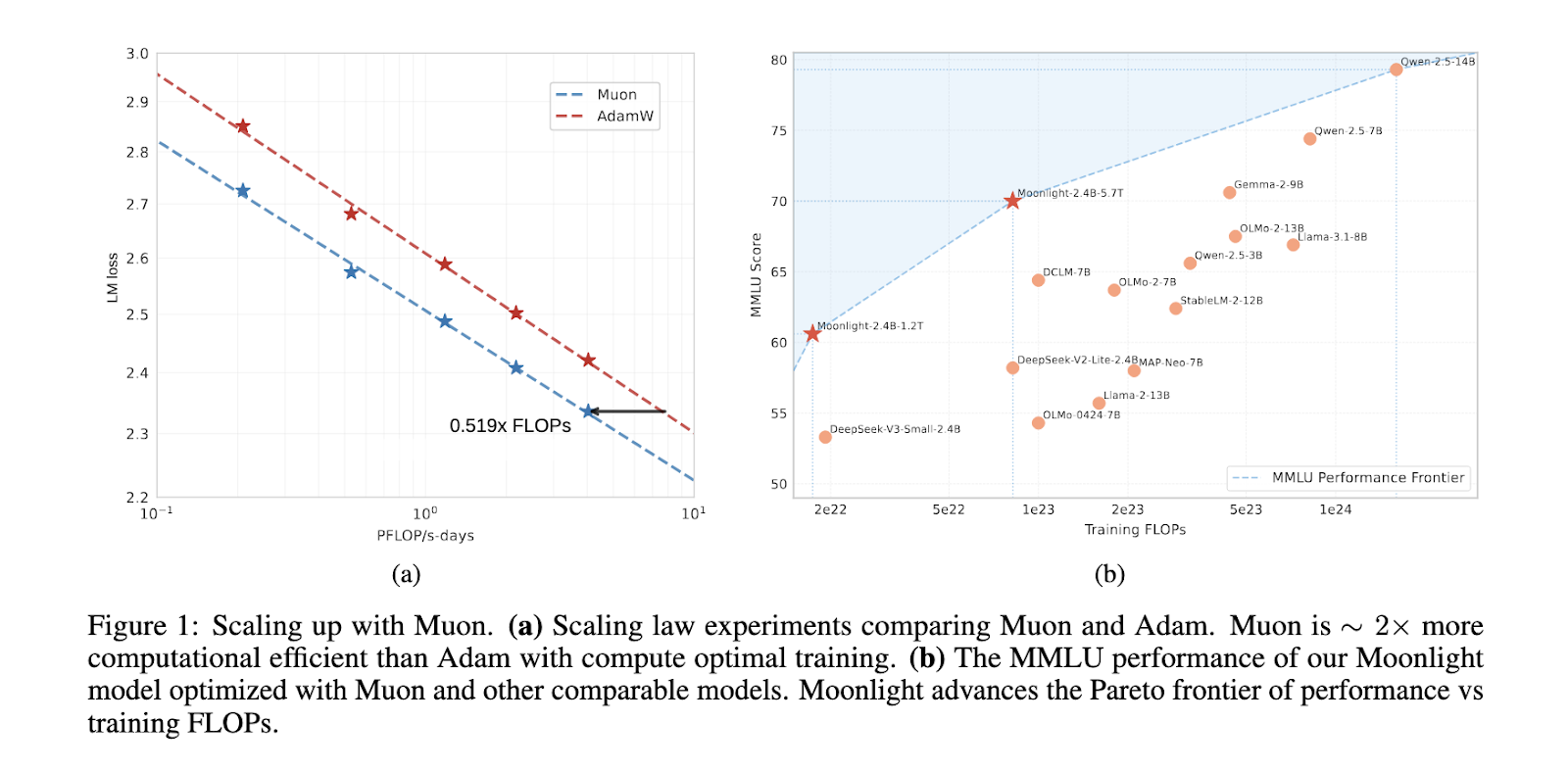
Performance evaluations demonstrate that Moonlight outperforms existing state-of-the-art models of comparable scale, including LLAMA3-3B and Qwen2.5-3B. Scaling law experiments revealed that Muon is approximately twice as sample-efficient as Adam, enabling significant reductions in training FLOPs while maintaining competitive results. Moonlight excelled across multiple benchmarks, achieving a score of 70.0 in MMLU, surpassing LLAMA3-3B at 54.75 and Qwen2.5-3B at 65.6. Moonlight obtained 42.4 in MMLU-pro and 65.2 in BBH in more specialized benchmarks, highlighting its enhanced performance. The model also demonstrated strong results in TriviaQA with a score of 66.3, surpassing all comparable models.
Moonlight achieved 48.1 in HumanEval and 63.8 in MBPP in code-related tasks, outperforming other models at similar parameter scales. In mathematical reasoning, it scored 77.4 in GSM8K and 45.3 in MATH, demonstrating superior problem-solving capabilities. Moonlight also performed well in Chinese language tasks, obtaining 77.2 in C-Eval and 78.2 in CMMLU, further establishing its effectiveness in multilingual processing. The model’s strong performance across diverse benchmarks indicates its robust generalization ability while significantly lowering computational costs.
Muon’s innovations address critical scalability challenges in training large models. By incorporating weight decay and consistent RMS updates, researchers enhanced stability and efficiency, enabling Moonlight to push the boundaries of performance while reducing training costs. These advancements solidify Muon as a compelling alternative to Adam-based optimizers, offering superior sample efficiency without requiring extensive tuning. The open-sourcing of Muon and Moonlight further supports the research community, fostering further exploration of efficient training methods for large-scale models.
Check out the Models here. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

The post Researchers from Moonshot AI Introduce Muon and Moonlight: Optimizing Large-Scale Language Models with Efficient Training Techniques appeared first on MarkTechPost.
