


Large language models (LLMs) have shown exceptional capabilities in understanding and generating human language, making substantial contributions to applications such as conversational AI. Chatbots powered by LLMs can engage in naturalistic dialogues, providing a wide range of services. The effectiveness of these chatbots relies heavily on high-quality instruction-following data used in post-training, enabling them to assist and communicate effectively with humans.
The challenge is the efficient post-training of LLMs using high-quality instruction data. Traditional methods involving human annotations and evaluations for model training are costly and constrained by the availability of human resources. The need for an automated and scalable approach to continuously improve LLMs has become increasingly critical. Researchers address this challenge by proposing a new method that mitigates the limitations of manual processes and leverages AI to enhance the efficiency and effectiveness of post-training.
Existing evaluation and developmental guidance for LLMs utilize platforms like the LMSYS Chatbot Arena, which pits different chatbot models against each other in conversational challenges judged by human evaluators. While this method provides robust and comprehensive evaluations, it is resource-intensive and limits the scalability of model improvements due to its dependency on human involvement. The inherent constraints of manual evaluations necessitate an innovative approach that can handle large-scale data and provide continuous feedback for model enhancement.
Researchers from Microsoft Corporation, Tsinghua University, and SIAT-UCAS introduced Arena Learning, a novel method that simulates iterative battles among various state-of-the-art models on extensive instruction data. This method leverages AI-annotated battle results to enhance target models through continuous supervised fine-tuning and reinforcement learning. The research team, comprising experts from Microsoft Corporation and Tsinghua University, implemented this method to create an efficient data flywheel for LLM post-training.
Arena Learning simulates an offline chatbot arena, which predicts performance rankings among different models using a powerful “judge model” that emulates human annotators. This judge model, specifically trained on diverse conversational data, evaluates model responses’ quality, relevance, and appropriateness. By automating the pair judgment process, Arena Learning significantly reduces human evaluations’ associated costs and limitations, enabling large-scale and efficient data generation for model training. The iterative battle and training process continuously updates and improves the target model, ensuring it remains competitive with the latest top-tier competitors.
Experimental results demonstrated substantial performance improvements in models trained with Arena Learning. The new fully AI-powered training and evaluation pipeline achieved a 40-fold efficiency improvement compared to the LMSYS Chatbot Arena. The researchers introduced WizardArena, an offline test set designed to balance diversity and complexity in evaluation, which produced Elo rankings that closely aligned with those from the LMSYS Chatbot Arena. This validation confirmed the effectiveness of Arena Learning as a reliable and cost-effective alternative to human-based evaluation platforms.
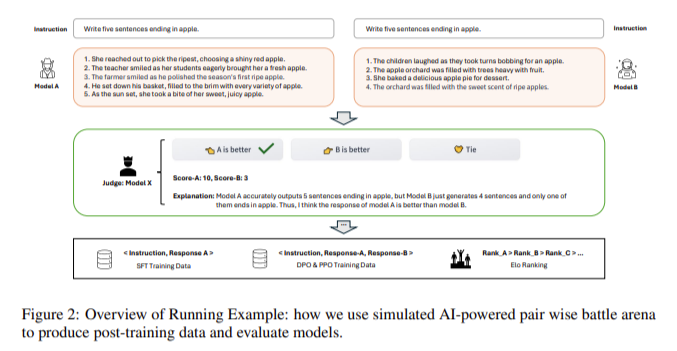
The significant contributions of this research include the introduction of Arena Learning, a novel AI-powered method for building an efficient data flywheel for LLM post-training. This method leverages AI to mitigate the manual and temporal costs associated with traditional training approaches. The researchers also contributed WizardArena, a carefully prepared offline test set, demonstrating its consistency and reliability in predicting Elo rankings among different LLMs. The experimental results highlighted the value and power of Arena Learning in producing large-scale synthetic data to continuously improve LLMs through various training strategies, including supervised fine-tuning, direct preference optimization, and proximal policy optimization.

In conclusion, Arena Learning can be used to post-train LLMs by automating the data selection and model evaluation processes. This approach reduces reliance on human evaluators and ensures continuous and efficient improvement of language models. The method’s ability to generate large-scale training data through simulated battles and iterative training processes has proven highly effective. The research underscores the potential of AI-powered methods in creating scalable and efficient solutions for enhancing LLM performance.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Arena Learning: Transforming Post-Training of Large Language Models with AI-Powered Simulated Battles for Enhanced Efficiency and Performance in Natural Language Processing appeared first on MarkTechPost.
