


Machine learning has made significant advancements, particularly through deep learning techniques. These advancements rely heavily on optimization algorithms to train large-scale models for various tasks, including language processing and image classification. At the core of this process lies the challenge of minimizing complex, non-convex loss functions. Optimization algorithms like Stochastic Gradient Descent (SGD) & its adaptive variants have become critical to this endeavor. Such methods aim to iteratively adjust model parameters to minimize errors during training, ensuring that models can generalize well on unseen data. However, while these optimization techniques have proven useful, there remains significant room for improvement in how they handle long-term gradient information.
A fundamental challenge in training large neural networks is the effective use of gradients, which provide the necessary updates for optimizing model parameters. Traditional optimizers like Adam and AdamW rely heavily on an Exponential Moving Average (EMA) of recent gradients, emphasizing the most current gradient information while discarding older gradients. This approach works well for models where recent changes hold more importance. However, this can be problematic for larger models and long training cycles, as older gradients often still contain valuable information. As a result, the optimization process may be less efficient, requiring longer training periods or failing to reach the best possible solutions.
In current optimization methods, particularly Adam and AdamW, using a single EMA for past gradients can limit the optimizer’s ability to capture a full spectrum of gradient history. These methods can adapt quickly to recent changes but often need more valuable information from older gradients. Researchers have explored several approaches to address this limitation, yet many optimizers still struggle to find the optimal balance between incorporating recent and past gradients effectively. This shortcoming can result in suboptimal convergence rates and poorer model performance, especially in large-scale training scenarios like language models or vision transformers.
Researchers from Apple and EPFL introduced a new approach to this problem with the AdEMAMix optimizer. Their method extends the traditional Adam optimizer by incorporating a mixture of two EMAs, one fast-changing and one slow-changing. This approach allows the optimizer to balance the need to respond to recent updates while retaining valuable older gradients often discarded by existing optimizers. This dual-EMA system, unique to AdEMAMix, enables more efficient training of large-scale models, reducing the total number of tokens needed for training while achieving comparable or better results.
The AdEMAMix optimizer introduces a second EMA to capture older gradients without losing the reactivity provided by the original EMA. Specifically, AdEMAMix maintains a fast-moving EMA that prioritizes recent gradients while tracking a slower-moving EMA that retains information much earlier in the training process. For example, when training a 1.3 billion-parameter language model on the RedPajama dataset, the researchers found that AdEMAMix could match the performance of an AdamW model trained on 197 billion tokens with only 101 billion tokens, a reduction of approximately 95% in token usage. This efficiency gain translates into faster convergence and often better minima, allowing models to reach superior performance with fewer computational resources.

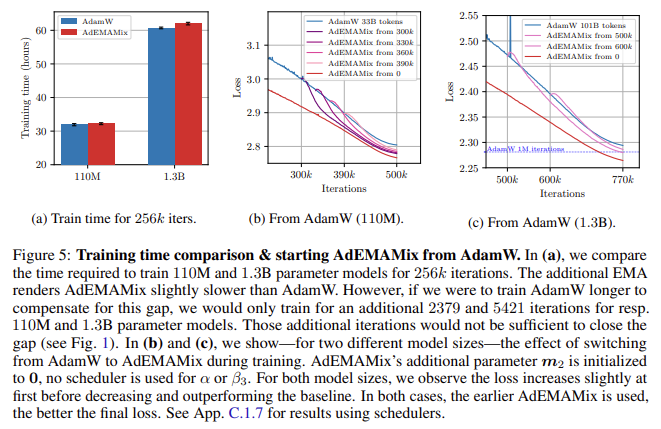
Performance evaluations of AdEMAMix have demonstrated substantial improvements in speed and accuracy over existing optimizers. In one key experiment, a 110 million-parameter model trained with AdEMAMix reached similar loss values as an AdamW model that required nearly twice the number of training iterations. Specifically, the AdEMAMix model, trained for 256,000 iterations, achieved the same results as an AdamW model trained for 500,000 iterations. For even larger models, such as the 1.3 billion-parameter language model, AdEMAMix delivered comparable results to an AdamW model trained for 1.5 million iterations but with 51% fewer tokens. The optimizer also demonstrated a slower rate of forgetting, which is a critical advantage in maintaining model accuracy over long training cycles.
The researchers also addressed some common challenges optimizers face, such as early training instabilities. To overcome these, they introduced warmup steps for the larger of the two EMAs, progressively increasing the value of the slow-changing EMA throughout training. This gradual increase helps stabilize the model during the initial training phase, preventing the optimizer from prematurely relying too heavily on outdated gradients. By carefully scheduling the adjustments for the two EMAs, AdEMAMix ensures that the optimization process remains stable and efficient throughout training, even for models with tens of billions of parameters.

In conclusion, the AdEMAMix optimizer presents a notable advancement in machine learning optimization. Incorporating two EMAs to leverage both recent and older gradients better addresses a key limitation of traditional optimizers like Adam and AdamW. This dual-EMA approach allows models to achieve faster convergence with fewer tokens, reducing the computational burden of training large models; AdEMAMix consistently outperformed A in trialsdamW, demonstrating its potential to improve performance in language modeling and image classification tasks. The method’s ability to reduce model forgetting during training further underscores its value for large-scale, long-term ML projects, making it a powerful tool for researchers and industry.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and LinkedIn. Join our Telegram Channel.
If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
The post This AI Paper from Apple Introduces AdEMAMix: A Novel Optimization Approach Leveraging Dual Exponential Moving Averages to Enhance Gradient Efficiency and Improve Large-Scale Model Training Performance appeared first on MarkTechPost.
