
Building AI Apps on Postgres? Start with pgai (Sponsored)

pgai is a PostgreSQL extension that brings more AI workflows to PostgreSQL, like embedding creation and model completion. pgai empowers developers with AI superpowers, making it easier to build search and retrieval-augmented generation (RAG) applications. Automates embedding creation with pgai Vectorizer, keeping your embeddings up to date as your data changes—no manual syncing required. Available free on GitHub or fully managed in Timescale Cloud.
Disclaimer: The details in this post have been derived from the Tinder Technical Blog. All credit for the technical details goes to the Tinder engineering team. The links to the original articles are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Tinder is a dating app that handles billions of swipes daily, matching over 75 million users worldwide.
Their recommendation engine must deliver matches with speed and precision. However, managing a global user base and ensuring seamless performance isn’t easy, especially when searches involve massive amounts of data spread across different regions.
To overcome the challenge, Tinder adopted Geosharding: a method of dividing user data into geographically bound "shards."
This approach enabled the recommendation engine to focus searches only on relevant data, dramatically improving performance and scalability. The system now handles 20 times more computations than before while maintaining low latency and delivering matches faster than ever.
In this post, we’ll explore how Geosharding works, the architecture behind it, and the techniques Tinder uses to ensure data consistency.
The Initial Single-Index Approach
When Tinder started using Elasticsearch to manage its recommendation system, it stored all user data in a single "index".
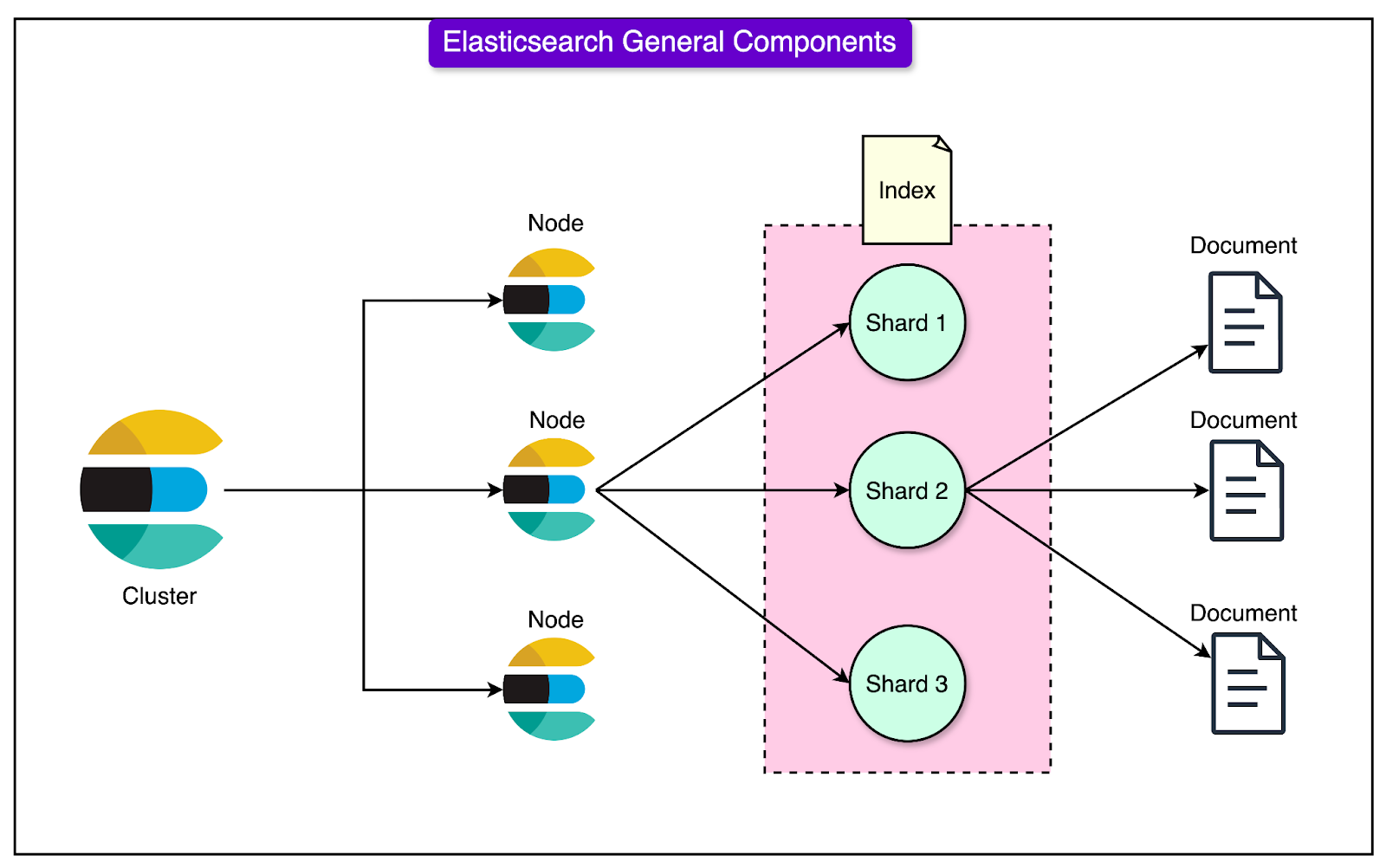
Think of this index as one massive database holding information about every Tinder user worldwide. While this worked fine when the platform was smaller, it caused significant problems as Tinder grew.
Some major problems were as follows:
The Index Became Too Big: As millions of users joined Tinder, the index grew into an enormous collection of data. Every time someone used the app to find potential matches, the system had to sift through this gigantic index, even though most of the data wasn’t relevant to that search. For example, a user in Los Angeles didn’t have to see people from London, but the system still had to deal with all the unnecessary data, making the process slow and inefficient.
High Latency (Search Slowness): Latency refers to the delay or time it takes to complete a task. In this case, the task was to find appropriate matches. Since the index was so large, it took a lot of time and computing power to search through everything. This delay degraded the user experience.
Rising Costs: To handle the ever-growing workload, Tinder had to add more powerful servers and replicas (backup systems) to maintain speed and reliability. These additions drove up infrastructure costs, making the system expensive to maintain.
The MOST Hands-On Training on AI Tools you’ll ever attend, for free (Sponsored)
The biggest MYTH about AI is that it is for people in tech. Or people who can code.
In reality, AI can be game-changing for you whether you are a curious 11 year old kid wanting to research or a 50 year old professional who is willing to stay relevant in 2024.
Join the 3 hour AI Tools Training (usually $399) but free for the first 100 readers.

By the way, here’s sneak peek into what’s inside the workshop:
Making money using AI ?
The latest AI developments, like GPT o1 ?
Creating an AI clone of yourself, that functions exactly like YOU ?
10 BRAND new AI tools to automate your work & cut work time by 50% ⏱️
And a lot more that you’re not ready for, just 3 hours! ?
1.5 Million people are already RAVING about this hands-on Training on AI Tools. Don’t take our word for it? Attend for yourself and see.
(first 100 people get it for free + $500 bonus) ?
The Geosharding Solution
Geosharding was the method Tinder adopted to address the inefficiencies of using a single large index for its recommendation system.
The idea was to divide the global user base into smaller, localized groups, or "shards," based on location. Each shard contains data for users in a specific region, allowing the system to focus its searches only on the most relevant data for a particular query.
How Geosharding Works?
Imagine Tinder’s user base as a map of the world.
Instead of putting all user data into one massive database (like a single, global shelf), the map is divided into smaller sections or shards. Each shard corresponds to a geographic region.
For example:
One shard might include all users within a 50-mile radius of Los Angeles.
Another shard might include users in London.
By organizing users this way, the system can search only the shard that matches a user’s location, avoiding the need to sift through irrelevant data. And all of this was made possible through Geosharding.
Geosharding improves query performance in the following ways:
Focus on Relevant Data: When a user searches for matches, Tinder only interacts with the shards containing users within their specified distance range (e.g., 100 miles). This drastically reduces the amount of data the system needs to process for each query, making searches much faster and more efficient.
Smaller Shard Sizes: Breaking the index into smaller shards results in lighter, more manageable datasets. Smaller datasets mean the system can process queries faster and with less strain on infrastructure.
Better Resource Utilization: By narrowing the search area to a localized shard, computing power is used more effectively. Resources aren’t wasted on processing irrelevant data.
Optimizing Shard Size
Despite the obvious benefits of sharding, finding the "right" size for a shard was crucial for maintaining system efficiency.
Several factors were considered in determining this balance:
Query Efficiency: Shards must be large enough to contain sufficient user data for meaningful matches. Too small a shard size could require the system to query multiple shards, increasing latency.
Shard Migration Overhead: Users don’t stay in one place—they travel, commute, or use features like "Passport" to swipe in different locations. When a user moves to a new geographical area, their data must be migrated to the corresponding shard. If shards are too small, migrations happen more frequently, creating temporary inconsistencies and operational complexity.
User Density Variations: Some areas, like New York City, have high concentrations of users in a small space, while others, like rural areas, have lower densities. Shards need to account for these differences. In densely populated areas, shards may represent smaller geographic regions, whereas in sparsely populated areas, shards might cover larger regions.
Algorithm and Tools Used For Geosharding
To implement Geosharding effectively, Tinder needed tools and algorithms that could efficiently divide the world into geographic shards while ensuring these shards were balanced in terms of user activity.
Two key components made this possible: Google’s S2 Library and a container-based load balancing method. Let’s look at them both in more detail.
The S2 Library: Mapping the Globe Into Cells
The S2 Library is a powerful tool developed by Google for spatial mapping. It divides the Earth’s surface into a hierarchical system of cells, which are smaller regions used for geographic calculations.
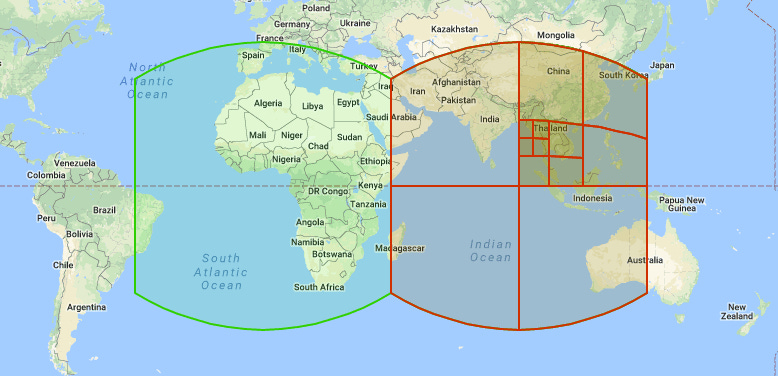
Here’s how it works and why it’s ideal for Geosharding:
Quadtree Structure: The S2 Library organizes cells in a "quadtree" structure, where each cell can be divided into four smaller cells. This allows for a flexible representation of geographic areas, from very large regions to precise, tiny locations.
Spatial Locality with Hilbert Curves: It uses a mathematical concept called a Hilbert curve, which ensures that geographically close points on the Earth’s surface remain close in the cell hierarchy. For example, users in Los Angeles and San Diego, being physically near each other, are also close in the S2 hierarchy. This helps group them logically within the same shard.
The main advantages of S2 for Tinder’s use case were as follows:
Consistent Cell Sizes: S2 ensured that cells at the same level in the hierarchy cover roughly equal areas, avoiding distortions near the poles that other systems (like Geohashes) often face.
Multi-level Granularity: Tinder could choose different cell sizes depending on user density. For instance:
Level 7 cells (~45 miles wide) were ideal for sparsely populated areas.
Level 8 cells (~22.5 miles wide) worked better for dense regions like New York City.
Efficient Geo-queries: Built-in S2 functions allow for quick mapping of a location (latitude/longitude) to a cell or a group of cells that cover a specific area.
Load Balancing: Evenly Distributing Users Across Geoshards
Once the world was divided into S2 cells, the next challenge was to balance the "load" across these cells.
Load refers to the activity or number of users within each shard. Without proper balancing, some shards could become "hot" (overloaded with users), while others remained underutilized.
To solve this, Tinder used a container-based load-balancing approach which involved the following aspects:
Quantifying the Load: Each S2 cell was assigned a load score based on factors like active user count and the number of queries originating from that cell. Higher activity meant a higher load score.
Balancing the Load: Imagine each S2 cell represents a neighborhood, and the “load” score” reflects the number of active Tinder users in that area. For example, a cell with a load score of 10 represents a neighborhood of 10 active users. Tinder used a "container" (a conceptual district) to group nearby neighborhoods into a district. When the container filled up to a certain threshold, it was treated as one Geoshard. This approach ensured that shards were formed based on activity, keeping their total load roughly equal.
Preserving Geographic Locality: Because S2 cells and Hilbert curves maintain spatial locality, the process naturally grouped adjacent cells into the same shard, ensuring each shard represented a contiguous geographic area.
The Abstraction Layer
After finalizing the Geosharding algorithm, Tinder designed a scalable and efficient architecture that relies on an abstraction layer to handle user data seamlessly across Geoshards.
This layer simplifies interactions between the application, the recommendation system, and the geosharded Elasticsearch cluster.
See the diagram below:
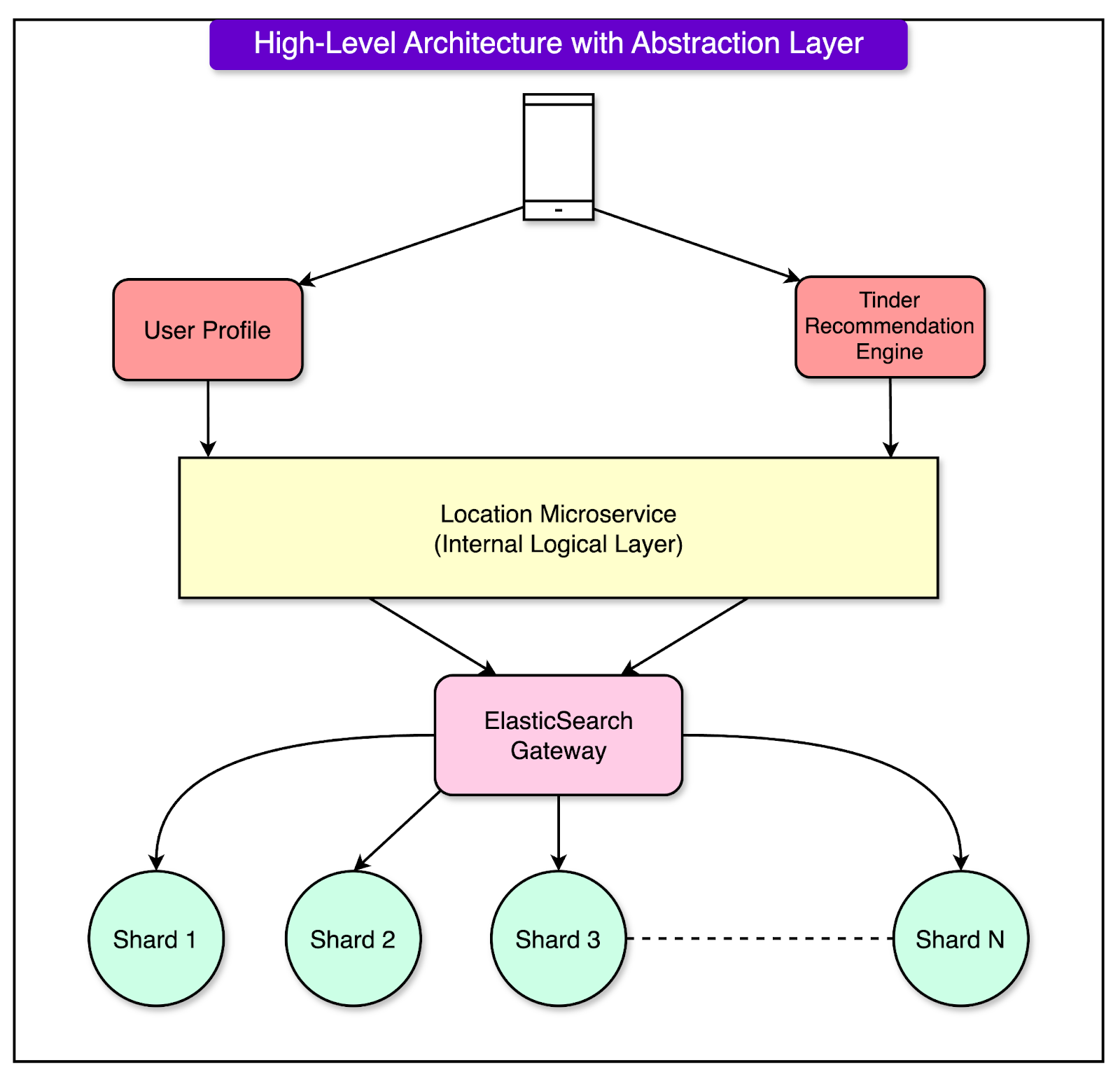
Here’s how the setup works:
Abstraction Layer: The abstraction layer is an internal microservice that acts as a bridge between Tinder’s application logic and the geosharded Elasticsearch system. It hides the complexity of Geosharding from the application layer, allowing the recommendation engine to interact with the cluster without worrying about the underlying shard configurations or user data migration.
Location Updates and Shard Movement: When a user’s location changes (for example, when traveling to a new city), the abstraction layer determines if this change requires the user’s data to be moved to a different Geoshard. It accesses Tinder’s location services to evaluate the user’s new position and initiates a shard move if necessary. The abstraction layer ensures the data is removed from the old shard and correctly added to the new one.
Query Handling: When a user searches for matches, the recommendation engine sends a request to the abstraction layer. The abstraction layer calculates which Geoshards need to be queried based on the user’s current location and their distance filter (e.g., a 50-mile radius). It distributes the query to the appropriate shards in the Elasticsearch cluster, collects the results, and aggregates them before sending them back to the client.
Geosharded Indices: The actual data is stored in Geosharded indices within the Elasticsearch cluster. These indices represent logical shards, divided based on geographic regions, and are accessed through the abstraction layer. The abstraction layer maintains a mapping of users to their respective Geoshards, ensuring that all operations (like searches or data migrations) are directed to the correct shard.
Dynamic Adaptation: The abstraction layer simplifies operations like shard rebalancing and re-sharding. For example, if user density in a specific area grows or shrinks significantly, the abstraction layer helps reconfigure shards to accommodate the changes without disrupting the system.
Multi-Index vs Multi-Cluster
When building the Geosharded recommendation system, Tinder had to decide how to organize its data infrastructure to manage the geographically separated shards efficiently.
This led to a choice between two approaches: multi-index and multi-cluster.
Each approach had pros and cons, but Tinder ultimately chose the multi-index approach. Let’s break it down in simple terms.
What is the Multi-Index Approach?
In the multi-index setup:
All the shards (Geoshards) are stored as separate indices within a single Elasticsearch cluster.
Each index corresponds to a logical Geoshard, containing user data for a specific geographic area.
The alternative was a multi-cluster setup that involved creating separate Elasticsearch clusters for each geoshard. While this approach has some advantages, it wasn’t the right fit for Tinder due to a lack of native support for cross-cluster queries and higher maintenance overhead.
To overcome the limitations of the multi-index setup, particularly the risk of uneven load distribution, Tinder implemented appropriate load balancing techniques. Some of the details about these techniques are as follows:
Dynamic Scaling Through Replica Adjustments:
A replica is a copy of an index shard. Adding more replicas distributes the workload across multiple servers, reducing the burden on any single shard.
Tinder adjusted the number of replicas dynamically based on the activity levels in each Geoshard:
High-traffic Geoshards (e.g., urban areas with many users) were given more replicas to handle the extra load.
Low-traffic Geoshards (e.g., rural areas) required fewer replicas, saving resources.
Handling Load Imbalances:
If a particular Geoshard became a "hotspot" due to a surge in user activity, its replicas could be increased temporarily to balance the load.
This ensured consistent performance across all regions, even during unexpected spikes in usage.
Fault Tolerance and Scalability:
By spreading replicas across multiple nodes in the cluster, Tinder ensured that the system could handle server failures without interrupting service.
This setup also allowed Tinder to scale horizontally by adding more servers to the cluster as needed.
Handling Time Zones: Balancing Traffic Across Geoshards
One of the key challenges Tinder faced with Geosharding was the variation in traffic patterns across Geoshards due to time zones.
See the diagram below that shows the traffic pattern of two Geoshards during a 24-hour time span:
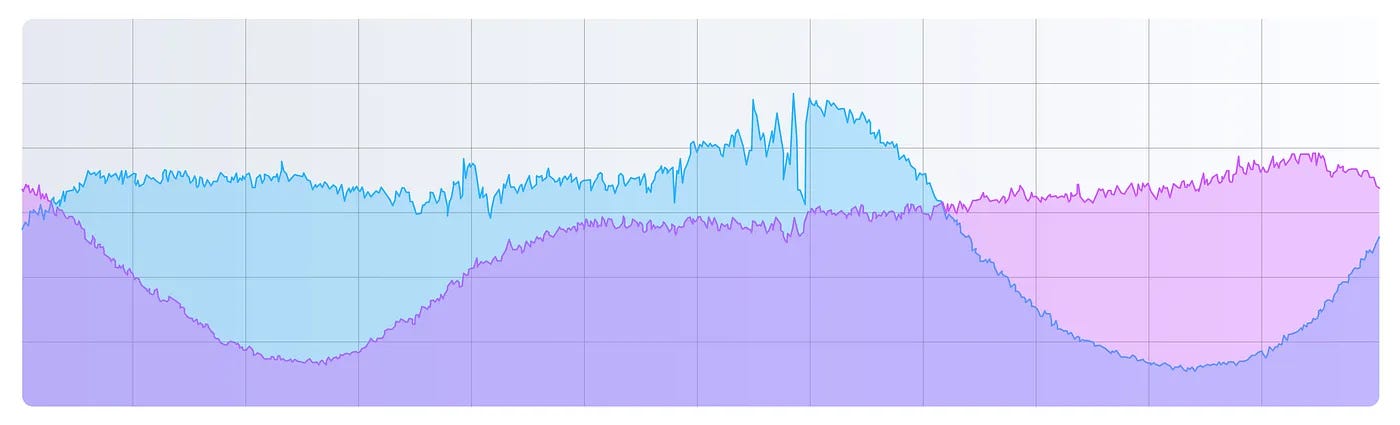
Users within the same geoshard are typically in the same or adjacent time zones, meaning their active hours tend to overlap. For example:
A shard covering New York experiences peak traffic during the evening in the Eastern Time Zone.
A shard covering Tokyo might see peak traffic several hours later, during the evening in Japan.
If shards were assigned directly to physical servers without considering time zone effects, some servers would be overloaded during peak hours for one shard, while others would remain idle.
To solve this problem, Tinder implemented a randomized distribution of shards and replicas across physical nodes in the Elasticsearch cluster.
Here’s how it works and why it helps:
Random Allocation of Shards: Each physical server (or "node") hosts multiple Geoshards. These shards are randomly distributed across the available nodes. For example, a single server might hold:
A primary shard for New York.
A replica shard for Tokyo.
Another replica shard for London.
Load Balancing Through Time-Zone Offsets: Since Geoshards covering different time zones have their peaks at different times of the day, random distribution ensures that the load on each node is more evenly spread throughout a 24-hour period. A server hosting New York’s shard (with peak traffic in the evening) will also host Tokyo’s shard (with peak traffic at a different time), balancing the load spikes.
Resilience to Changes: The random distribution of shards also helps in case of unexpected traffic surges. If one Geoshard suddenly experiences higher activity, the other shards on the same node are less likely to be at their peaks, preventing server overload.
The Overall Cluster Design
Tinder’s Geosharded recommendation system was built using a carefully designed cluster architecture to handle billions of daily swipes while maintaining speed, reliability, and scalability.
The cluster architecture divides the responsibilities among different types of nodes, each playing a specific role in ensuring the system’s performance and fault tolerance.
See the diagram below:
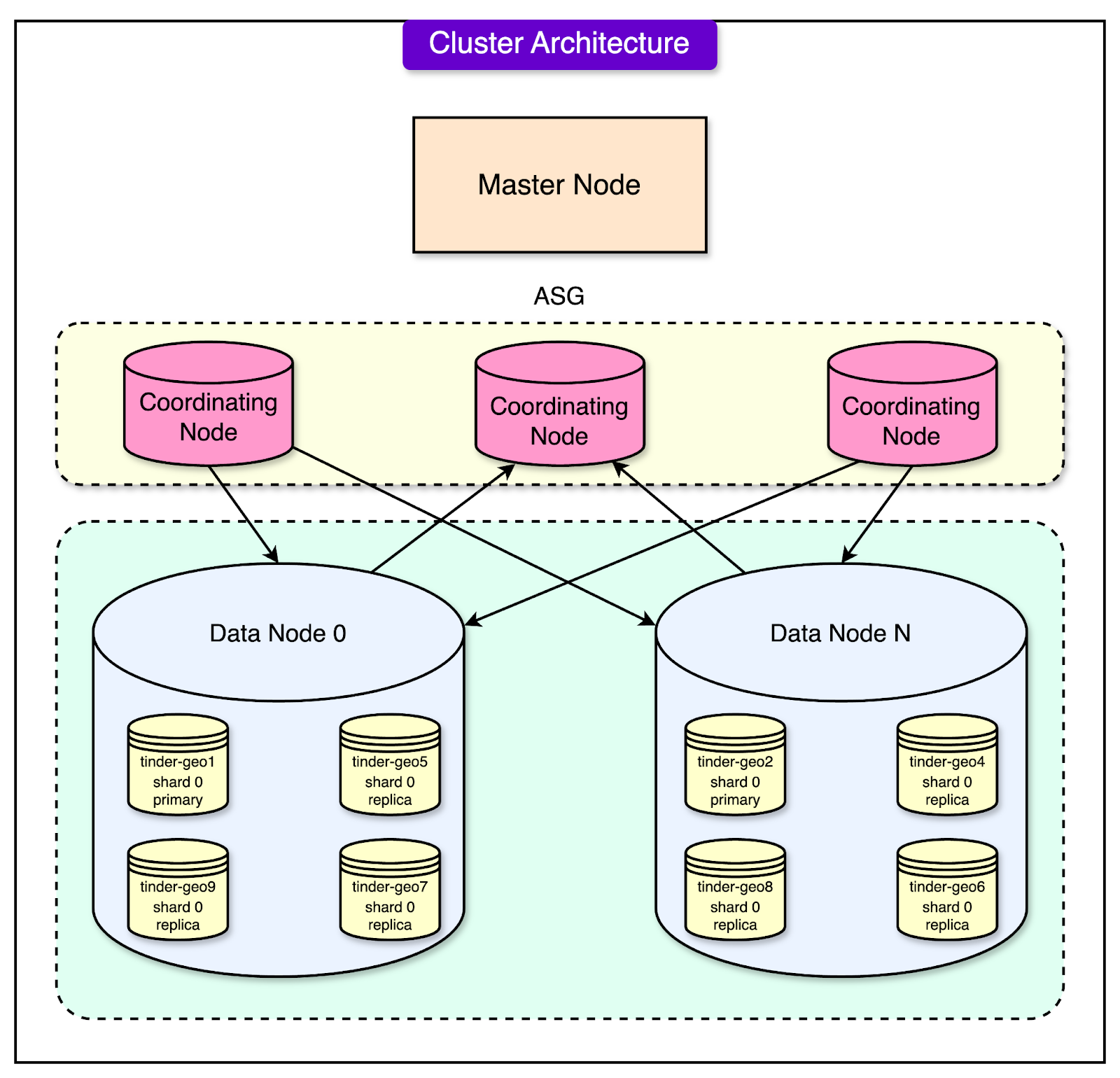
The key components of the cluster are as follows:
Master Nodes
These are the managers of the cluster, responsible for overall health and coordination.
They keep track of which shards are stored on which data nodes. They also monitor the status of the nodes and redistribute shards if a node fails.
Master nodes don’t handle user queries directly. Their role is to manage the system and ensure everything runs smoothly.
Coordinating Nodes
The coordinating nodes act as the traffic controllers of the system.
When a user performs a search or swipe, their request goes to a coordinating node. This node determines:
Which Geoshards need to be queried based on the user’s location and filters?
Which data nodes hold the relevant shards to process the request?
Once the results are collected from the data nodes, the coordinating node aggregates them and sends the final response back to the user.
Data Nodes
These are the workers of the cluster, responsible for storing the actual data and processing queries. Data nodes execute the search queries sent by coordinating nodes and return the results.
Each data node holds multiple Geoshards and their replicas as follows:
Primary Shards: The main copies of data.
Replica Shards: Backup copies that improve fault tolerance and help balance the workload.
Consistency Challenges
Maintaining data consistency was another significant challenge in Tinder’s Geosharded system.
This complexity arises because users frequently move between locations, and their data must be dynamically shifted between Geoshards. Without proper handling, these transitions could lead to inconsistencies, such as failed writes, outdated information, or mismatches between data locations.
The key challenges are as follows:
Concurrent Updates: In Tinder’s real-time environment, multiple updates to the same user data can happen within milliseconds of each other. For example, a user could use Tinder’s Passport feature to switch their location to another city and then quickly return to their original location. If updates are not processed in the correct order, the system could end up storing outdated or incorrect information.
Failed Writes: During the migration of user data between Geoshards, network issues or system overloads could cause write operations to fail, leaving the data incomplete or missing.
Stale Data: A delay in updating Geoshard mappings could result in queries pointing to the wrong shard, leading to the retrieval of outdated information.
Mapping Mismatches: The mapping datastore, which keeps track of which shard a user belongs to, could fall out of sync with the actual location of the user’s data, causing future updates or queries to fail.
Tinder implemented a combination of strategies to address these issues and ensure consistent, reliable data handling across Geoshards. Let’s look at a few of those techniques in detail.
1 - Guaranteed Write Ordering with Apache Kafka
When multiple updates occur for the same user data, ensuring they are processed in the correct order is critical to avoid inconsistencies.
Apache Kafka was used as the backbone for managing data updates because it guarantees that messages within a partition are delivered in the same order they were sent.
Tinder assigns each user a unique key (for example, their user ID) and uses consistent hashing to map updates for that user to a specific Kafka partition. This means all updates for a particular user are sent to the same partition, ensuring they are processed in the order they are produced.
See the diagram below:
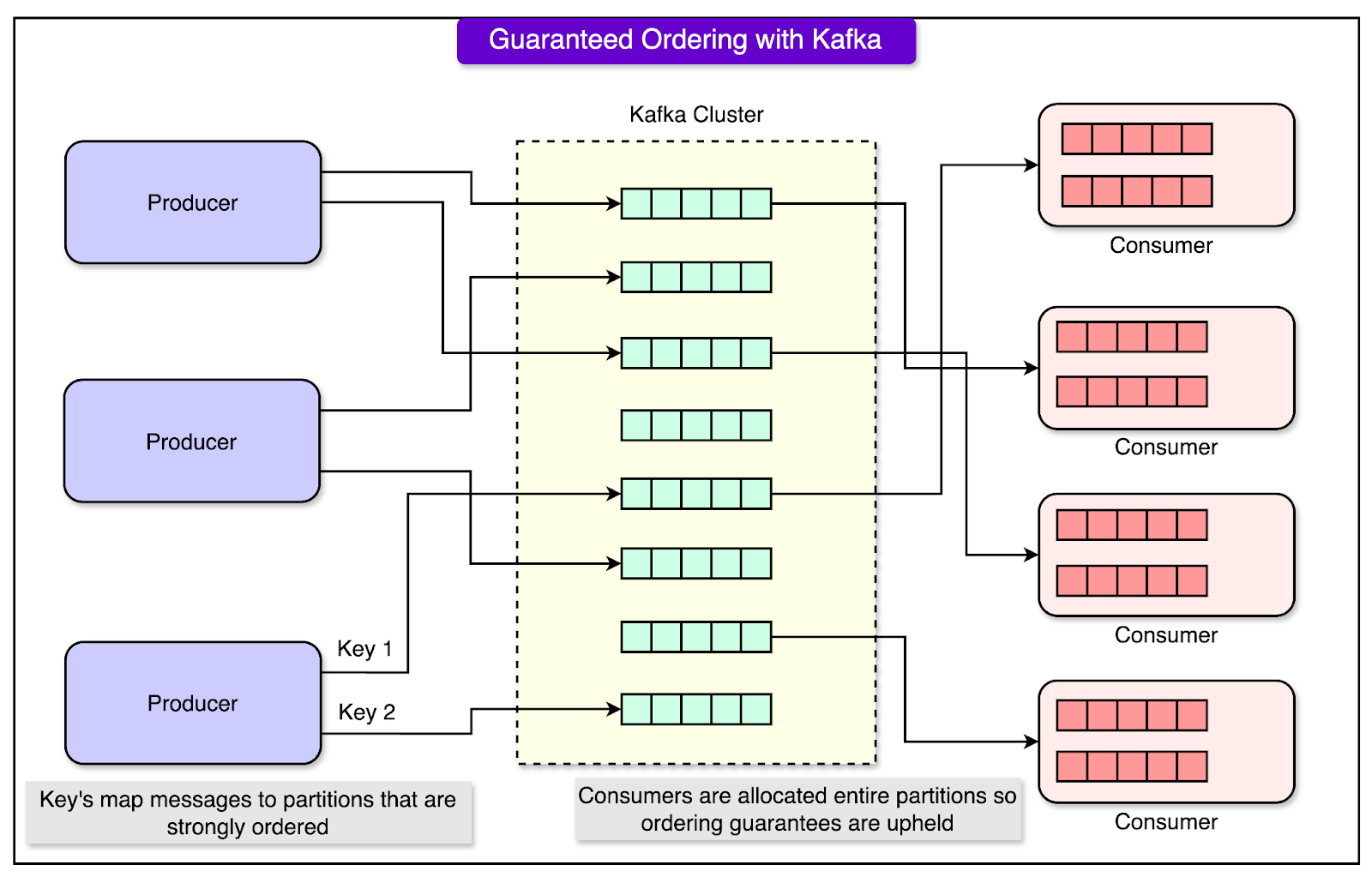
The consumers (parts of the system that read and process messages) read updates sequentially from the partitions, ensuring that no updates are skipped or processed out of order.
This guarantees that the latest update always reflects the most recent user activity.
2 - Strongly Consistent Reads with the Elasticsearch Get API
Elasticsearch is a "near real-time" search engine, meaning recently written data may not be immediately available for queries. This delay can lead to inconsistencies when trying to retrieve or update data.
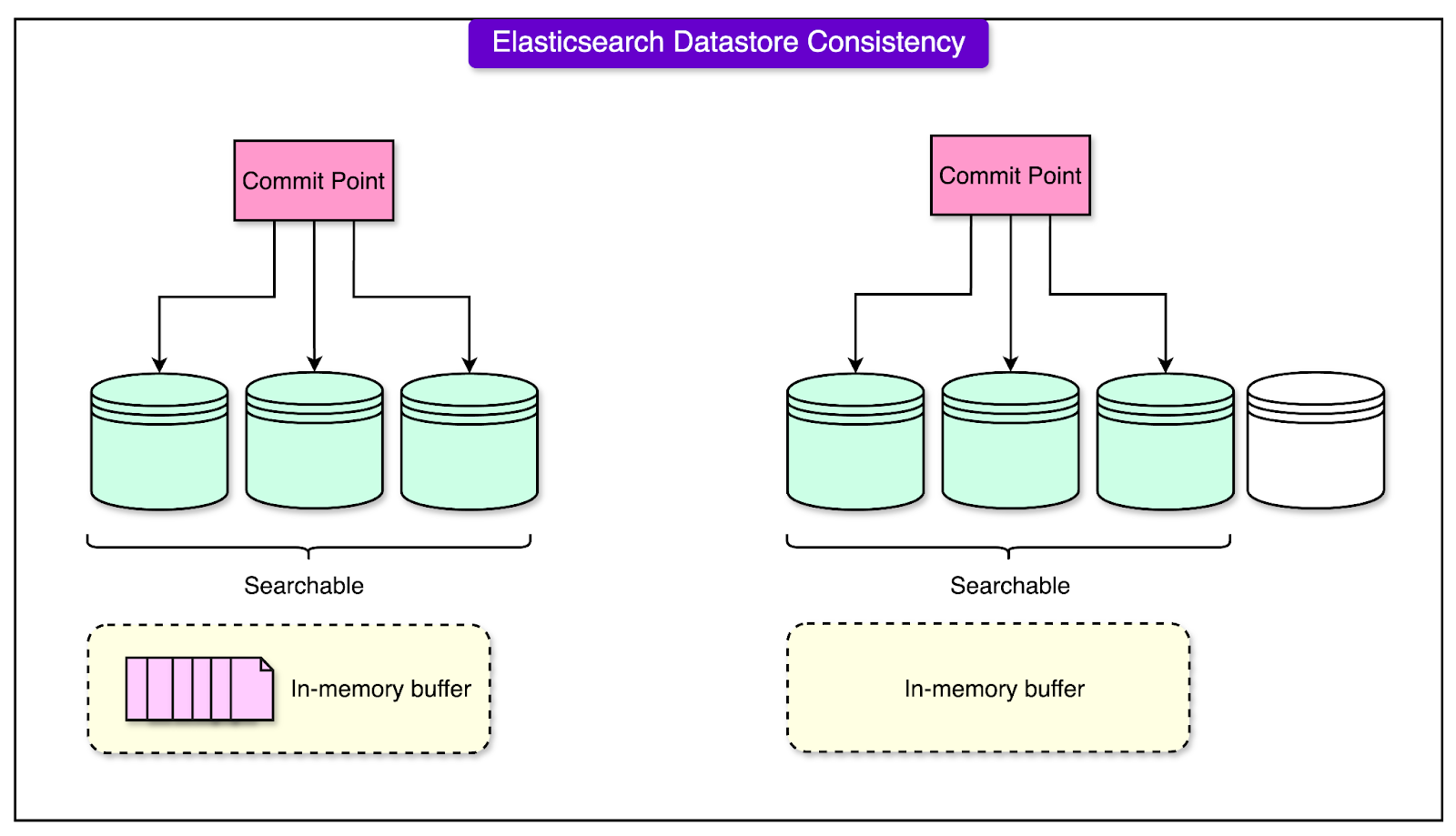
Tinder, however, leveraged Elasticsearch’s Get API, which forces the index to refresh before retrieving data. This ensures that any pending updates are applied before the data is accessed.
Reindexing and Refeeding:
In cases where data inconsistencies occurred due to upstream failures or mismatches between shards, a mechanism was needed to realign the datastore with the source of truth.
Data from the source shard was copied to the target shard when a user moved between Geoshards.
If inconsistencies were detected (e.g., missing data in a shard), the system periodically re-synced the search datastore with the source datastore using a background process.
This ensured that even if temporary errors occurred, the system would self-correct over time.
Conclusion
Tinder’s implementation of Geosharding demonstrates the complexities of scalability, performance, and data consistency in a global application.
By dividing its user base into geographically bound shards, Tinder optimized its recommendation engine to handle billions of daily swipes while maintaining lightning-fast response times. Leveraging tools like the S2 Library and Apache Kafka, along with algorithms for load balancing and consistency, the platform transformed its infrastructure to support a seamless user experience across the globe.
This architecture improved performance by handling 20 times more computations than the previous system. It also addressed challenges like traffic imbalances across time zones and potential data inconsistencies during shard migrations. With randomized shard distribution, dynamic replica adjustments, and intelligent reindexing, Tinder ensured reliability, fault tolerance, and scalability.
References:
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
