


Multimodal large language models (MLLMs) showed impressive results in various vision-language tasks by combining advanced auto-regressive language models with visual encoders. These models generated responses using visual and text inputs, with visual features from an image encoder processed before the text embeddings. However, there remains a big gap in understanding the inner mechanisms behind how such multimodal tasks are dealt with. The lack of understanding of the inner workings of MLLMs limits their interpretability, reduces transparency, and hinders the development of more efficient and reliable models.
Earlier studies looked into the internal workings of MLLMs and how they relate to their external behaviors. They focused on areas like how information is stored in the model, how logit distributions show unwanted content, how object-related visual information is identified and changed, how safety mechanisms are applied, and how unnecessary visual tokens are reduced. Some research analyzed how these models processed information by examining input-output relationships, contributions of different modalities, and tracing predictions to specific inputs, often treating the models as black boxes. Other studies explored high-level concepts, including visual semantics and verb understanding. Still, existing models struggle to combine visual and linguistic information to produce accurate results effectively.
To solve this, researchers from the University of Amsterdam, the University of Amsterdam, and the Technical University of Munich proposed a method that analyzes visual and linguistic information integration within MLLMs. The researchers mainly focused on auto-regressive multimodal large language models, which consist of an image encoder and a decoder-only language model. Researchers investigated the interaction of visual and linguistic information in multimodal large language models (MLLMs) during visual question answering (VQA). The researchers explored how information flowed between the image and the question by selectively blocking attention connections between the two modalities at various model layers. This approach, known as attention knockout, was applied to different MLLMs, including LLaVA-1.5-7b and LLaVA-v1.6-Vicuna-7b, and tested across diverse question types in VQA.
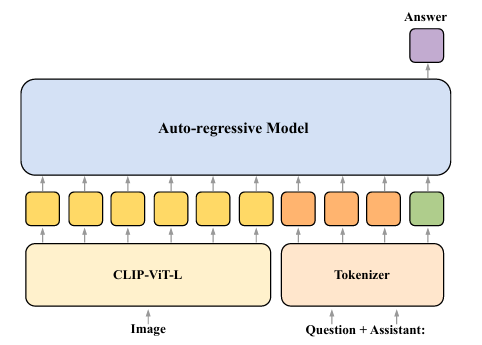
Researchers used data from the GQA dataset to support visual reasoning and compositional question answering and explore how the model processed and integrated visual and textual information. They focused on six question categories and used attention knockout to analyze how blocking connections between modalities affected the model’s ability to predict answers.
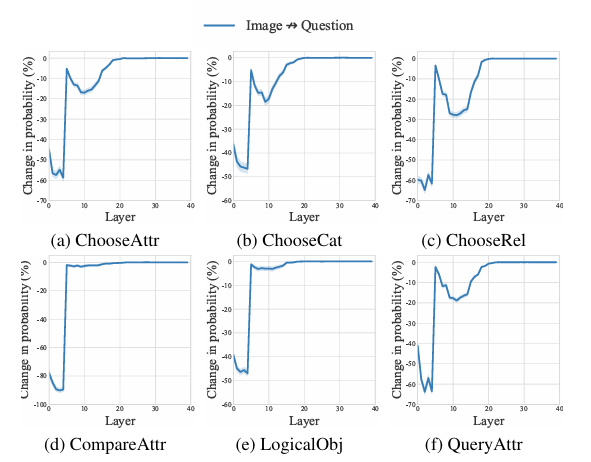
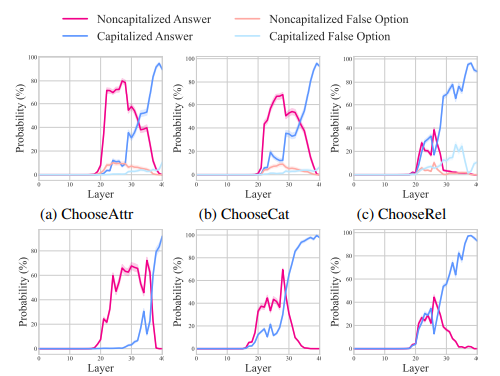
The results show that the question information played a direct role in the final prediction, while the image information had a more indirect influence. The study also showed that the model integrated information from the image in a two-stage process, with significant changes observed in the early and later layers of the model.
In summary, the proposed method reveals that different multimodal tasks exhibit similar processing patterns within the model. The model combines image and question information in early layers and then uses it for the final prediction in later layers. Answers are generated in lowercase and then capitalized in higher layers. These findings enhance the transparency of such models, offering new research directions for better understanding the interaction of the two modalities in MLLMs and can lead to improved model designs!
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.

 ‘
‘The post Unraveling Multimodal Dynamics: Insights into Cross-Modal Information Flow in Large Language Models appeared first on MarkTechPost.
