
Published on November 1, 2024 1:05 AM GMT
We've just launched a new experimental feature: "Automated Jargon Glossaries." If it goes well, it may pave the way for things like LaTeX hoverovers and other nice things.
Whenever an author with 100+ karma saves a draft of a post, our database queries a language model to:
- Identify terms that readers might not know.Write a first draft of an explanation of that termMake a guess as to which terms are useful enough to include.
By default, explanations are not shown to readers. Authors get to manually approve term/explanations that they like, or edit them. Authors will see a UI looking like this, allowing them to enable terms so readers see them. They can also edit them (by clicking on the term).
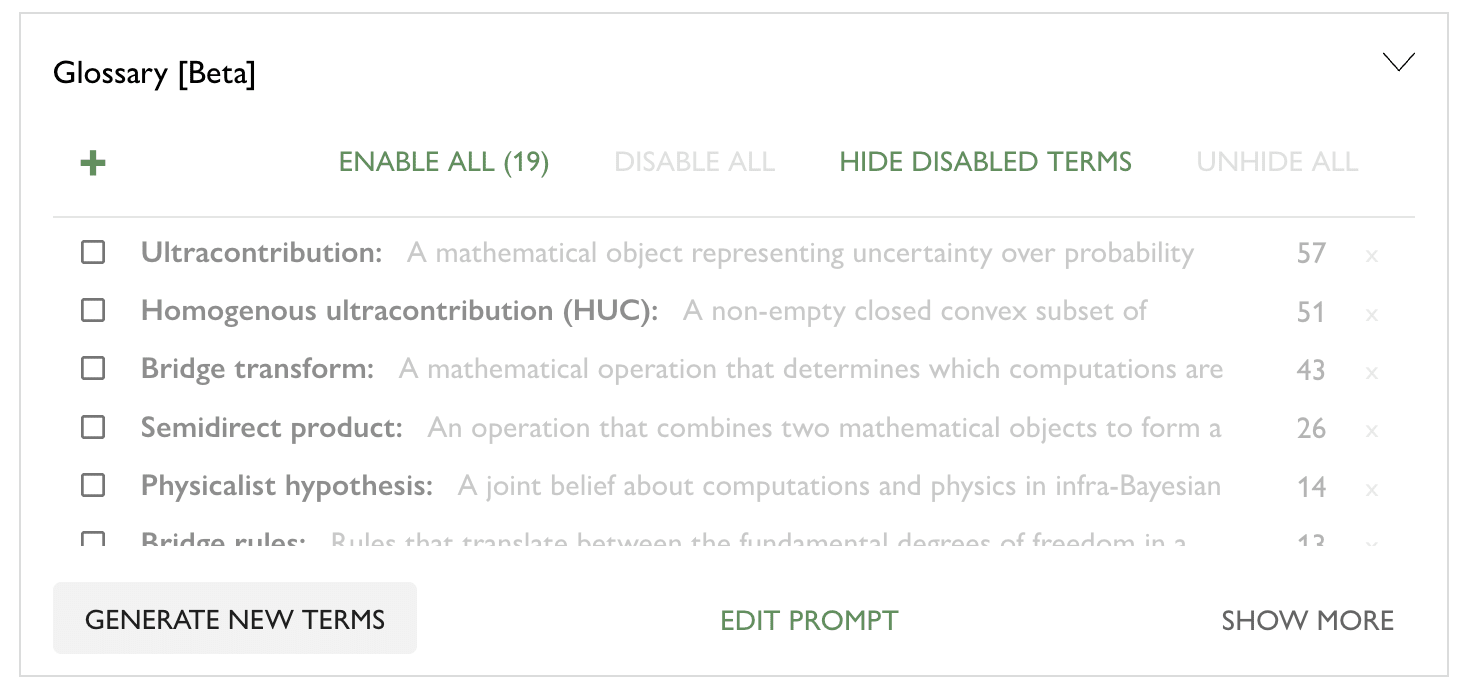
Meanwhile, here's a demo of what readers might see, from the Infra-Bayesian physicalism post.[1]
TLDR: We present a new formal decision theory that realizes naturalized induction. Our agents reason in terms of infra-Bayesian hypotheses, the domain of which is the cartesian product of computations and physical states, where the ontology of "physical states" may vary from one hypothesis to another. The key mathematical building block is the "bridge transform", which, given such a hypothesis, extends its domain to "physically manifest facts about computations". Roughly speaking, the bridge transforms determines which computations are executed by the physical universe. In particular, this allows "locating the agent in the universe" by determining on which inputs its own source is executed.
0. Background
The "standard model" of ideal agency is Bayesian reinforcement learning, and more specifically, AIXI. We challenged this model before due to its problems with non-realizability, suggesting infra-Bayesianism as an alternative. Both formalisms assume the "cartesian cybernetic framework", in which (i) the universe is crisply divided into "agent" and "environment" and (ii) the two parts interact solely via the agent producing actions which influence the environment and the environment producing observations for the agent. This is already somewhat objectionable on the grounds that this division is not a clearly well-defined property of the physical universe. Moreover, once we examine the structure of the hypothesis such an agent is expected to learn (at least naively), we run into some concrete problems.
Managing Slop: Author Approval & Opt In
I take pretty seriously the worry that LessWrong will become filled with AI slop, and that people will learn to tune out UI features built around it. Longterm, as AI gets good enough to not be slop, I'm even more worried, since then it might get things subtly wrong and it'd be really embarrassing if the AI Alignment discourse center plugged AIs into its group cognition and then didn't notice subtle errors.
These problems both seem tractable to me to deal with, but do require a bunch of effort and care.
For now: we've tried to tune the generation to minimize annoying "false positives" (terms which are too basic or sufficiently obvious from context) for authors or readers, while setting things up so it's possible to notice "false negatives" (perfectly good terms that the system rejected).
The current system is that authors have:
- Shortlist of "probably good" terms to review . By the time they're done editing a post, authors should be presented with a short list of terms, that (we hope) are mostly useful and accurate enough to be worth enabling, without much overhead.Hidden-but-accessible "less good" terms. Authors also have access to additional terms that are less likely to be useful, which are hidden by default (even to the authors, unless they click "show hidden" in their glossary editor).Prompt Tuning. Authors can edit the glossary prompt to fit their preferred style. (Currently, this prompt editing isn't saved between page reloads, but longterm we'd likely add some kind of Prompt Library)
Meanwhile, readers experience:
- Default to "author approved." Only see high signal glossary terms.Default to "only highlight each term once." The first time you see a term in a post, it'll show up as slightly-grey, to indicate you can hoverover it. But subsequent instances of that term won't be highlighted or have hoverovers.Default to "one-sentence," click for more. If you click on a term, the hoverover will show a second paragraph explaining how it fits into the context of this post.Know who edited an explanation. See if a term was "AI generated", "Human generated" or "AI and human edited".Opt into "Highlight All." At the top-right of a post, if there are any approved terms, you'll see a glossary. If you click on it, it'll pin the glossary in place, and switch to highlighting each term every time it appears, so you can skim the post and still get a sense of what technical terms mean if you start diving into a section in the middle. (There is also a hotkey for this: opt/alt + shift + J.)Opt into "All Terms." On a given post, you can toggle "show all terms." It'll come with the warning: "Enable AI slop that the author doesn't necessarily endorse." (There is also a hotkey for this: opt/alt + shift + G. This works even if there aren't any approved terms for a post, which is a case where the entire glossary is hidden by default.)
I'm not sure whether it's correct to let most users see the "hidden potential-slop", but I'm somewhat worried that authors won't actually approve enough terms on the margin for more intermediate-level readers. It seems okay to me to let readers opt-in, but, I'm interested in how everyone feels about that.
The longterm vision
The Lightcone team has different visions about whether/how to leverage LLMs on LessWrong. Speaking only for myself, here are some things I'm (cautiously) excited about:
Automated "adjust to reader level."
Readers who are completely new to LessWrong might see more basic terms highlighted. We've tried to tune the system so it doesn't, by default, explain words like 'bayesian' since it'd be annoying to longterm readers, but newcomers might actively want those.
People who are new to the field of Machine Learning might want to know what a ReLU is. Experienced ML people probably don't care.
I think the mature version of this a) makes a reasonable guess about what terms you'll want highlighted by default, b) lets you configure it yourself.
If you're reading a highly technical post in a domain you don't know, eventually we might want to have an optional "explain like I'm 12" button at the top, that takes all the author-approved-terms and assembles them into an introduction, that gives you background context on what this field and author are trying to accomplish, before diving into the cutting-edge details.
The 0-1 second level
Some other LW team members are less into JargonBot, because they were already having a pretty fine time asking LLMs "hey what's this word mean?" while reading dense posts. I'm not satisfied with that, because I think there's a pretty big difference between "actions that take 5-10 seconds" and "actions that take 0-1 second".
Actions in the 0-1 second zone can be a first-class part of my exobrain – if I see something I don't know, I personally want to briefly hover over it, get a sense of it, and then quickly move back to whatever other sentence I was reading.
The 0-1 second level is also, correspondingly, more scary, from the standpoint of 'integrating AI into your thought process.' I don't currently feel worried about it for JargonBot in particular (in particular since it warns when a thing is AI generated).
I do feel much more worried about it for writing rather than reading, since things like "autocomplete" more actively insert themselves into your thinking loop. I'm interested in takes on this (both for JargonBot and potential future tools)
LaTeX
This started with a vision for "hoverovers for LaTeX", such that you could easily remember what each term in an equation means, and what each overall chunk of the equation represents. I'm pretty excited for a LessWrong that actively helps you think through complex, technical concepts.
Curating technical posts
Currently, posts are more likely to get curated if they are easier to read – simply because easier to read things get read more. Periodically a technical post seems particularly important, and I sit down and put in more effort to slog through it and make sure I understand it so I can write a real curation notice, but it's like a 5-10 hour job for me. (Some other LW staff find it easier, but I think even the more technically literate staff curate fewer technical things on the margin)
I'm excited for a world where the LW ecosystem has an easier time rewarding dense, technical work, which turns abstract concepts into engineering powertools. I'm hoping JargonBot both makes it easier for me to read and curate things, as well as easier for readers to read them (we think of ourselves as having some kinda "budget" for curating hard-to-read things, since most of the 30,000 people on the curation mailing list probably wouldn't actually get much out of them).
Higher level distillation
Right now, AIs are good at explaining simple things, and not very good at thinking about how large concepts fit together. It currently feels like o1 is juuuuust on the edge of being able to do a good job with this.
It's plausible than in ~6 months the tools will naturally be good enough (and we'll have figured out how to leverage them into good UI) that in addition to individual terms, AI tools can assist with understanding the higher-level bits of posts and longterm research agendas. ("WTF is Infrabayesianism for, again?")
Remember AI capabilities are probably bad, actually
Despite all that, I do remind myself that although a lot of this is, like, objectively cool, also, man I do really wish the frontier labs would coordinate to slow down and lobby the government to help them do it. I'm really worried about how fast this is changing, and poorly I expect humanity to handle the situation.
As I've thought more about how to leverage AI tools, I've also somewhat upweighted how much I try to prioritize thinking about coordinated AI pause/slowdown, so that my brain doesn't naturally drift towards fewer marginal thoughts about that.
Feedback
With all that in mind, I would like to hear from LW users:
- Is this useful, as a reader?Are you seeing terms that feel too basic to be worth including?Are you not seeing enough terms that the system is skipping, to avoid false-positives?As an author, how do you feel about it? Does it feel more like a burdensome chore to approve glossary terms, or a cool UI opportunity?As an author, how do you feel about users being able to toggle on the "hidden slop" if they want?
Let us know what you think!
- ^
(Note: I have not yet checked with @Vanessa Kosoy if the initial definition here is accurate. On the real post, it won't appear for readers until the author deliberately enabled it. I've enabled it on this particular post, for demonstration purposes. But, warning! It might be wrong!)
Discuss
