


Cognitive neuroscience studies how the brain processes complex information, particularly language. Researchers are interested in understanding how the brain transforms low-level stimuli, like sounds or words, into higher-order concepts and ideas. One important area of this research is comparing the brain’s language processing mechanisms to those of artificial neural networks, especially large language models (LLMs). By examining how LLMs handle language, researchers aim to uncover deeper insights into human cognition and machine learning systems, improving both fields.
One of the critical challenges in this field is understanding why certain layers of LLMs are more effective at replicating brain activity than others. While LLMs are primarily trained to predict text, the ability of intermediate layers to accurately represent human-like language comprehension has emerged as an intriguing puzzle. Researchers focus on why these intermediate layers align more closely with brain activity than the output layers designed for prediction tasks. Identifying what makes these layers superior for brain-model similarity is crucial for advancing neuroscience and AI research.
Traditionally, scientists have used tools like functional magnetic resonance imaging (fMRI) to map the brain’s response to language. They have also relied on linear projections to measure the similarity between brain activity and LLMs’ hidden states. These methods show that intermediate layers of LLMs tend to outperform output layers in reflecting brain data. Various studies have confirmed this trend, yet the specific reasons for the success of these intermediate layers remain poorly understood. Further research is needed to fully comprehend the underlying processes that make LLMs mimic human brain function so effectively.
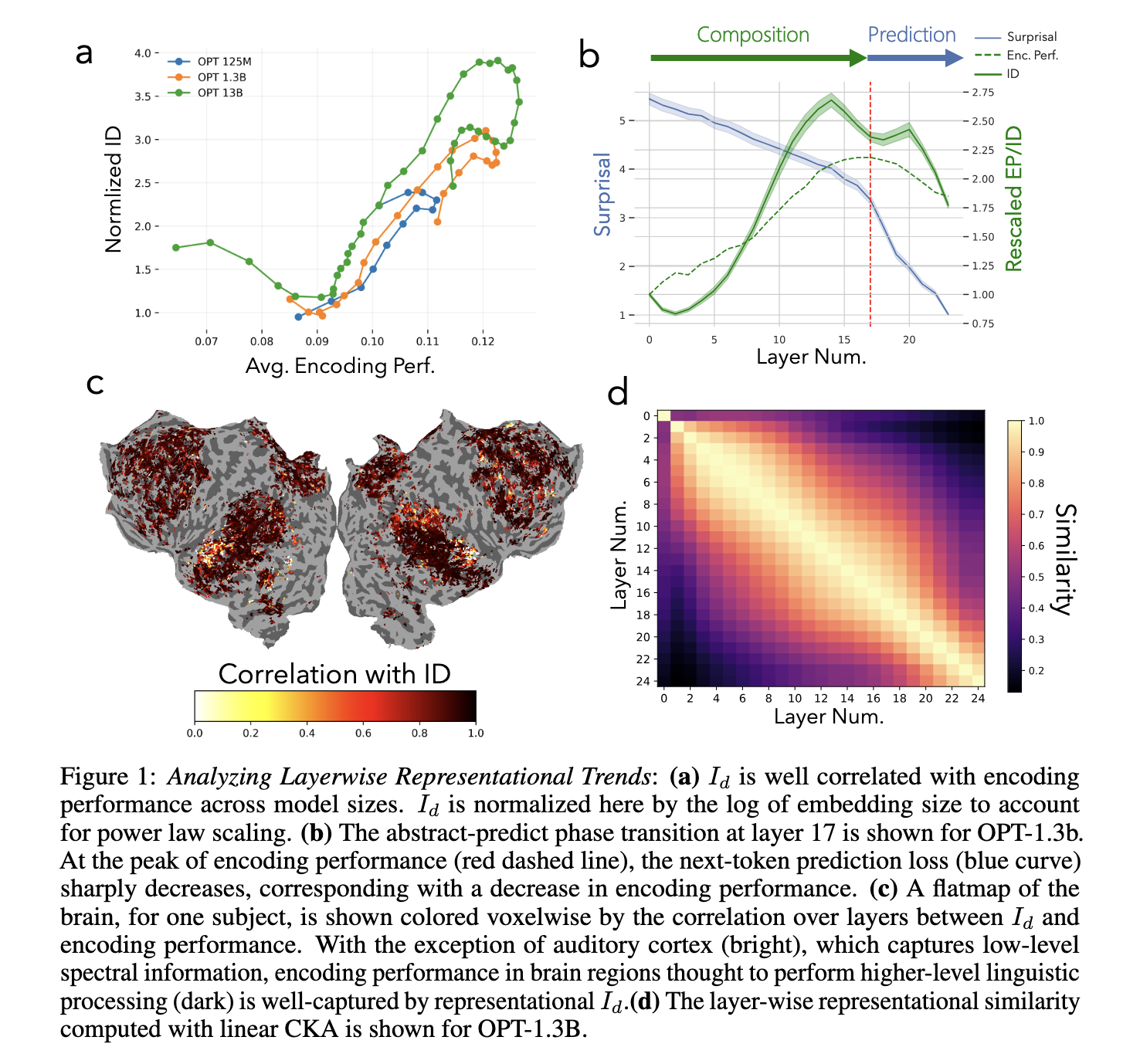
Researchers from the Universitat Pompeu Fabra and Columbia University have introduced a new methodology to explore this phenomenon. Using manifold learning techniques, they identified a two-phase abstraction process in LLMs. During training, LLMs first compress complex language features into fewer layers, a phase the researchers call “composition.” The second phase, “prediction,” focuses on the model’s task of predicting the next word. According to their findings, this abstraction process is crucial for the high brain-model similarity observed in LLMs, with the composition phase being more critical than previously thought. The study highlights the importance of this layered approach to language representation in understanding LLM and brain functions.
The researchers analyzed the intrinsic dimensionality of the model’s representations to investigate further how LLMs achieve brain-model similarity. This approach allowed them to study how complex language features were captured across different layers of the model. They tested various LLMs, including the Pythia language model, using nine different checkpoints during training, ranging from 1,000 to 143,000 training steps. The results showed that earlier model layers handle language composition, while later layers focus on refining predictions. By measuring the dimensionality of each layer, the team demonstrated that the model’s ability to capture complex linguistic features increased during the early phases of training, reflecting the brain’s abstraction process.
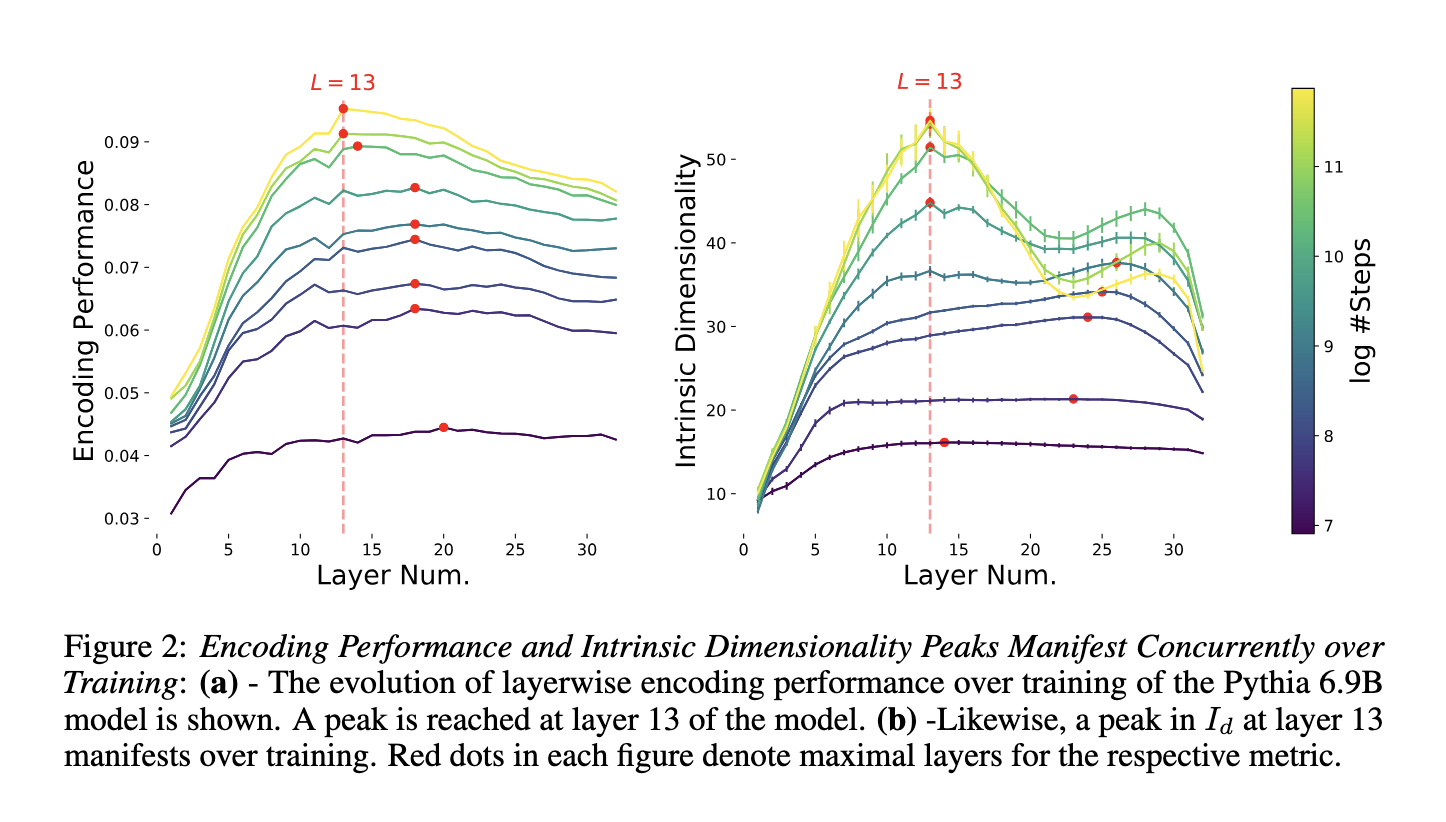
The researchers found a strong correlation between intermediate layers and brain-model similarity in their experiments. They identified that the optimal layer for predicting brain activity peaked at layer 17 in the OPT-1.3b model, corresponding to the highest encoding performance. The researchers used three LLM sizes (125M, 1.3B, and 13B) and measured the voxelwise product-moment correlation between representational dimensionality and encoding performance. For the largest Pythia model (6.9B parameters), the researchers confirmed that the intrinsic dimensionality grew over time, with a peak in encoding performance and dimensionality at layer 13. These results suggest that the first abstraction phase is more important for brain-model similarity than the final prediction phase, challenging previous assumptions about the role of prediction tasks in brain-LM alignment.
The study’s findings are significant because they show that LLMs and human brains share a similar two-phase process when it comes to language abstraction. The researchers also suggest that improvements in LLM performance could be achieved by focusing on spectral properties across layers. If these properties are efficiently combined, they could create a representation that surpasses the performance of any single layer in the model, offering new avenues for enhancing brain-language model alignment.
In conclusion, the research offers insights into how LLMs and the brain handle language processing. By identifying a two-phase abstraction process in LLMs, the researchers have better understood brain-model similarity. Their findings suggest that the composition phase, rather than the prediction phase, is most responsible for this similarity. This study opens the door for future research into how language models can be optimized for machine learning and neuroscience tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit

The post Intrinsic Dimensionality and Compositionality: Linking LLM Hidden States to fMRI Encoding Performance appeared first on MarkTechPost.
