


A significant challenge in information retrieval today is determining the most efficient method for nearest-neighbor vector search, especially with the growing complexity of dense and sparse retrieval models. Practitioners must navigate a wide range of options for indexing and retrieval methods, including HNSW (Hierarchical Navigable Small-World) graphs, flat indexes, and inverted indexes. These methods offer different trade-offs in terms of speed, scalability, and quality of retrieval results. As datasets become larger and more complex, the absence of clear operational guidance makes it difficult for practitioners to optimize their systems, particularly for applications requiring high performance, such as search engines and AI-driven applications like question-answering systems.
Traditionally, nearest-neighbor search is handled using three main approaches: HNSW indexes, flat indexes, and inverted indexes. HNSW indexes are commonly used for their efficiency and speed in large-scale retrieval tasks, particularly with dense vectors, but they are computationally intensive and require significant indexing time. Flat indexes, while exact in their retrieval results, become impractical for large datasets due to slower query performance. Sparse retrieval models, like BM25 or SPLADE++ ED, rely on inverted indexes and can be effective in specific scenarios but often lack the rich semantic understanding provided by dense retrieval models. The main limitation across these approaches is that none are universally applicable, with each method offering different strengths and weaknesses depending on the dataset size and retrieval
Researchers from the University of Waterloo introduce a thorough evaluation of the trade-offs between HNSW, flat, and inverted indexes for both dense and sparse retrieval models. This research provides a detailed analysis of the performance of these methods, measured by indexing time, query speed (QPS), and retrieval quality (nDCG@10), using the BEIR benchmark dataset. The researchers aim to give practical, data-driven advice on the optimal use of each method based on the dataset size and retrieval requirements. Their findings indicate that HNSW is highly efficient for large-scale datasets, while flat indexes are better suited for smaller datasets due to their simplicity and exact results. Additionally, the study explores the benefits of using quantization techniques to improve the scalability and speed of the retrieval process, offering a significant enhancement for practitioners working with large datasets.
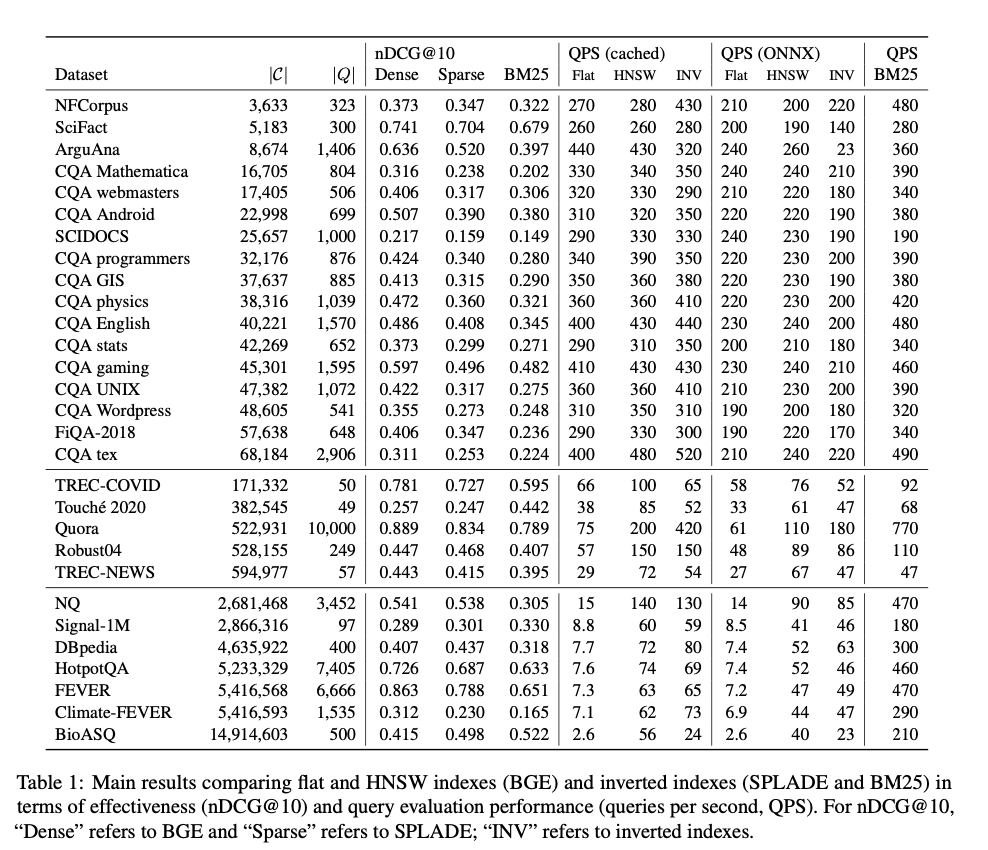
The experimental setup utilizes the BEIR benchmark, a collection of 29 datasets designed to reflect real-world information retrieval challenges. The dense retrieval model used is BGE (Base General Embeddings), with SPLADE++ ED and BM25 serving as the baselines for sparse retrieval. The evaluation focuses on two types of dense retrieval indexes: HNSW, which constructs graph-based structures for nearest-neighbor search, and flat indexes, which rely on brute-force search. Inverted indexes are used for sparse retrieval models. The evaluations are conducted using the Lucene search library, with specific configurations such as M=16 for HNSW. Performance is assessed using key metrics like nDCG@10 and QPS, with query performance evaluated under two conditions: cached queries (precomputed query encoding) and ONNX-based real-time query encoding.
The results reveal that for smaller datasets (under 100K documents), flat and HNSW indexes show comparable performance in terms of both query speed and retrieval quality. However, as dataset sizes increase, HNSW indexes begin to significantly outperform flat indexes, particularly in terms of query evaluation speed. For large datasets exceeding 1 million documents, HNSW indexes deliver far higher queries per second (QPS), with only a marginal decrease in retrieval quality (nDCG@10). When dealing with datasets of over 15 million documents, HNSW indexes demonstrate substantial improvements in speed while maintaining acceptable retrieval accuracy. Quantization techniques further boost performance, particularly in large datasets, offering notable increases in query speed without a significant reduction in quality. Overall, dense retrieval methods using HNSW prove to be far more effective and efficient than sparse retrieval models, particularly for large-scale applications requiring high performance.
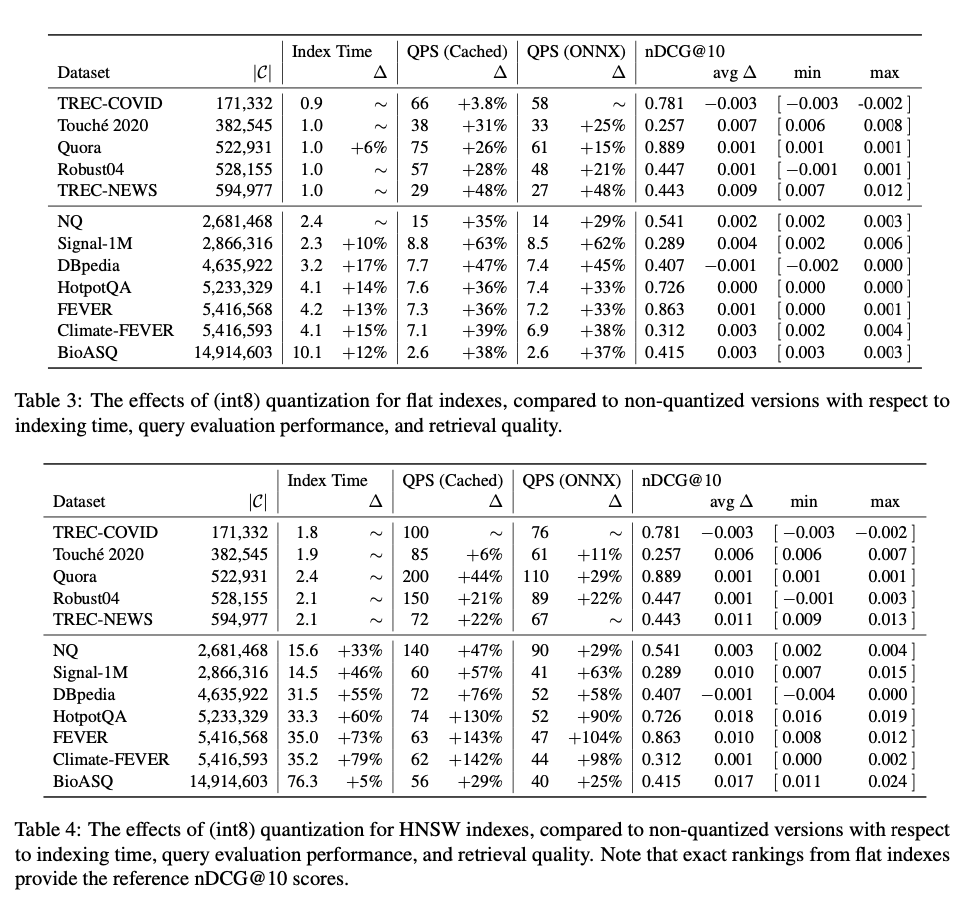
This research offers essential guidance for practitioners in dense and sparse retrieval, providing a comprehensive evaluation of the trade-offs between HNSW, flat, and inverted indexes. The findings suggest that HNSW indexes are well-suited for large-scale retrieval tasks due to their efficiency in handling queries, while flat indexes are ideal for smaller datasets and rapid prototyping due to their simplicity and accuracy. By providing empirically-backed recommendations, this work significantly contributes to the understanding and optimization of modern information retrieval systems, helping practitioners make informed decisions for AI-driven search applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit

The post HNSW, Flat, or Inverted Index: Which Should You Choose for Your Search? This AI Paper Offers Operational Advice for Dense and Sparse Retrievers appeared first on MarkTechPost.
