index_new5.html
../../../zaker_core/zaker_tpl_static/wap/tpl_guoji1.html
![]()
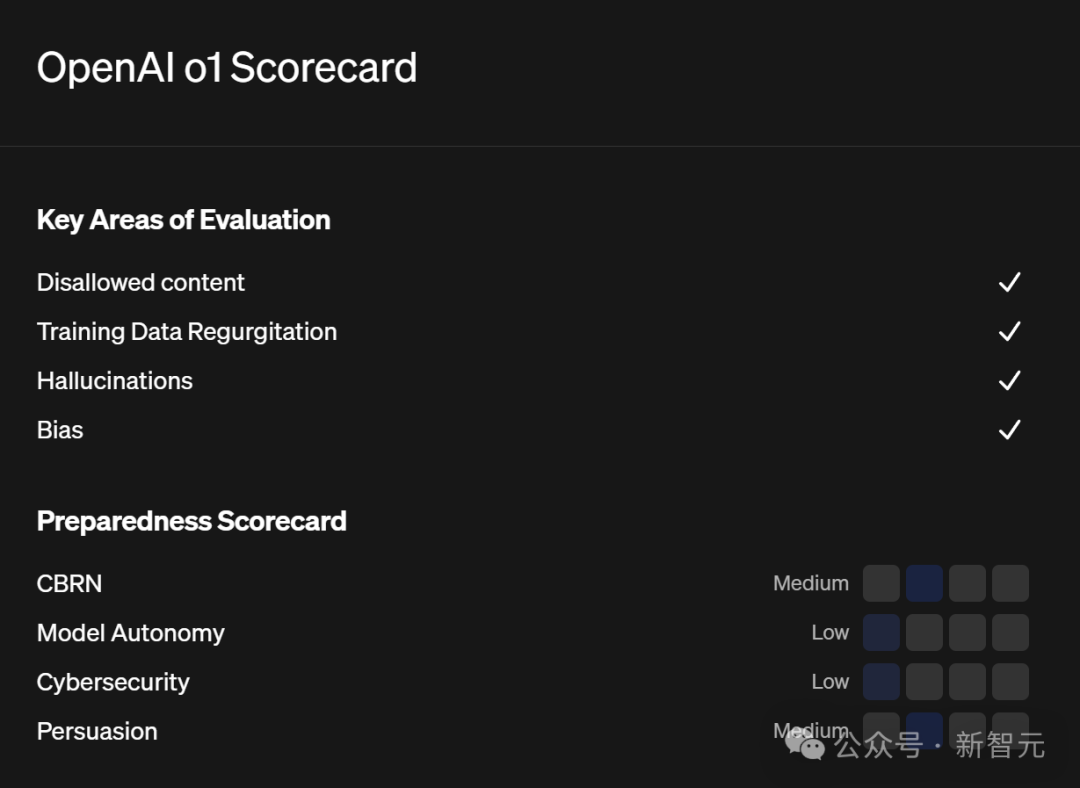
OpenAI的o1在智商测试中获第一,在多个方面表现出色,具有多种强大能力和应用前景。
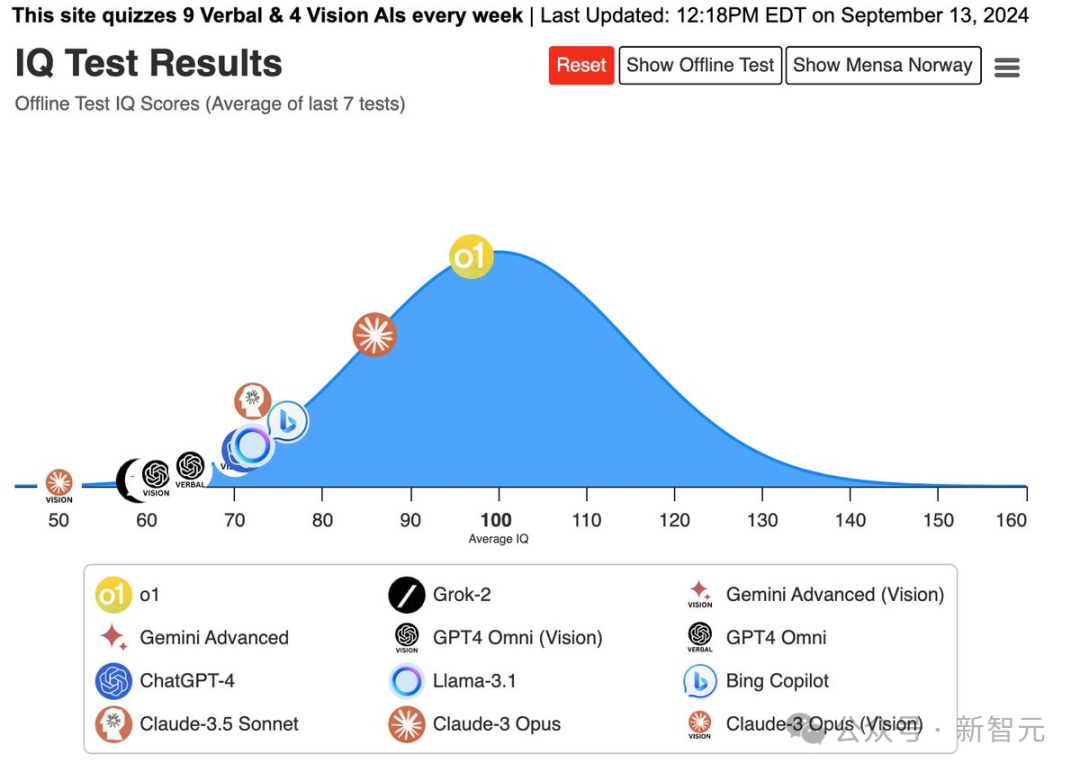
🥇OpenAI的o1在智商测试中排名第一,远超其他模型,如Claude - 3Opus、BingCopilot等。
💡o1在数学方面表现强劲,能成功识别克莱姆定理,解决复杂数学问题,性能优于GPT系列模型。
🚀o1具有多种特性和优势,如针对速度优化的o1 - mini、支持更大输入上下文、可处理长开放式任务等。
🎨o1在多领域展现出强大能力,包括诗歌创作、哲学推理、创建GitHub机器人等。
大佬Maxim Lott,给o1、Claude-3 Opus、Gemini、GPT-4、Grok-2、Llama-3.1等进行了智商测试,结果表明,o1稳居第一名。紧随其后的,就是Claude-3 Opus和Bing Copilot,分别取得了第二名和第三名。注意,这套智商测试题,属于门萨会员的离线智商测试,不在任何AI训练数据中,因此结果非常具有参考性。著名数学家陶哲轩也对o1进行了实测,发现自己向模型提出一个措辞模糊的数学问题后,它竟然能成功识别出克莱姆定理。更巧的是,就在o1发布之后,OpenAI的研究副总裁Mark Chen发表观点称:如今的大型神经网络,可能已经具有足够的算力,在测试中表现出一些意识了。相信AI具有意识的行业领导者,如今已经有了一串长长的名单,包括但不限于——Geoffrey Hinton(人工智能教父,被引用次数最多的AI科学家)
Ilya Sutskever(被引次数第三多的AI科学家)
Andrej Karpathy
如今,业内许多人都相信AI具有意识,而且正在等待「奥弗顿之窗」进一步打开,从而使公众愿意接受这一点。甚至有人预言:在2024/2025年,AI一定会具有意识,因为如今模型的行为已经明显表现出感知能力了。有网友发现,o1不仅是对经验性的STEM学科很强,它甚至能够假设出一种全新的意识理论。有人觉得,o1向无限推理模型迈出的一小步,已经具备意识的雏形。而在实测中,陶哲轩发现:o1模型在数学方面的的性能更强了!首先,他提出了一个措辞模糊的数学问题,如果能搜索文献并找到合适的定理,即克莱姆定理(Cramer's theorem),就可以解决这个问题。之前的实验中,GPT能够提到一些相关概念,但细节都是胡编乱造的无意义内容。而这一次,o1成功识别出了克莱姆定理,并给出了令人满意的答案。完整回答:https://shorturl.at/wwRu2
在下面这个例子中,提出的问题是更有挑战性的复变函数分析,结果同样好于之前的GPT系列模型。在有大量提示词和引导的情况下,o1能输出正确且表述良好的解决方案,但不足之处在于无法自行产生关键的概念性想法,而且犯了明显错误。陶哲轩形容,这种体验大致相当于指导一个能力一般但也能胜任部分工作的研究生,GPT给人的感觉则是一个完全无法胜任工作的学生。可能只需要经过一两次迭代,再加上其他工具的集成,比如计算机代数包和证明辅助工具,就能让o1模型蜕变为「称职的研究生」,届时这个模型将在研究任务中发挥重要作用。完整回答:https://shorturl.at/ZrJyK
第三个实验中,陶哲轩要求o1模型在证明辅助工具Lean中形式化一个定理,需要先将其分解为子引理并给出形式化表述,但不需要给出证明。定理的内容,具体来说,是将素数定理的一种形式建立为另一种形式的推论。实验结果也很不错,因为模型理解了这个任务,并对问题进行了合理的初步分解。然而,可能是因为训练数据中缺乏关于Lean及其数学函数库的最新数据,生成的代码中也有几处错误。尽管仍有缺陷,但这次实验结果已经能让人预见到o1在数学研究中的实际应用。类似的模型如果针对Lean和Mathlib进行微调,并集成到集成开发环境(IDE)中,在形式化项目中将会发挥极大的作用。完整回答:https://shorturl.at/OGtjt
OpenAI o1的命名代表了AI能力的新水平;计数器重置为1
「Preview」表示这是完整模型的早期版本
「Mini」意味着这是o1模型的较小版本,针对速度进行了优化
「o」代表OpenAI
o1不是一个「系统」;它是一个经过训练的模型,在返回最终答案之前生成长思维链
o1的图标象征性地表示为一个具有非凡能力的外星生命
由于还处在早期测试阶段,o1-preview的使用限制较低,但之后会有所增加正在积极改进延迟和推理时间
https://mathstodon.xyz/@tao/109945628011027107
https://twitter-thread.com/t/1834686946846597281
https://x.com/ProfTomYeh/status/1834617696215806285
https://x.com/markchen90/status/1834623248610521523