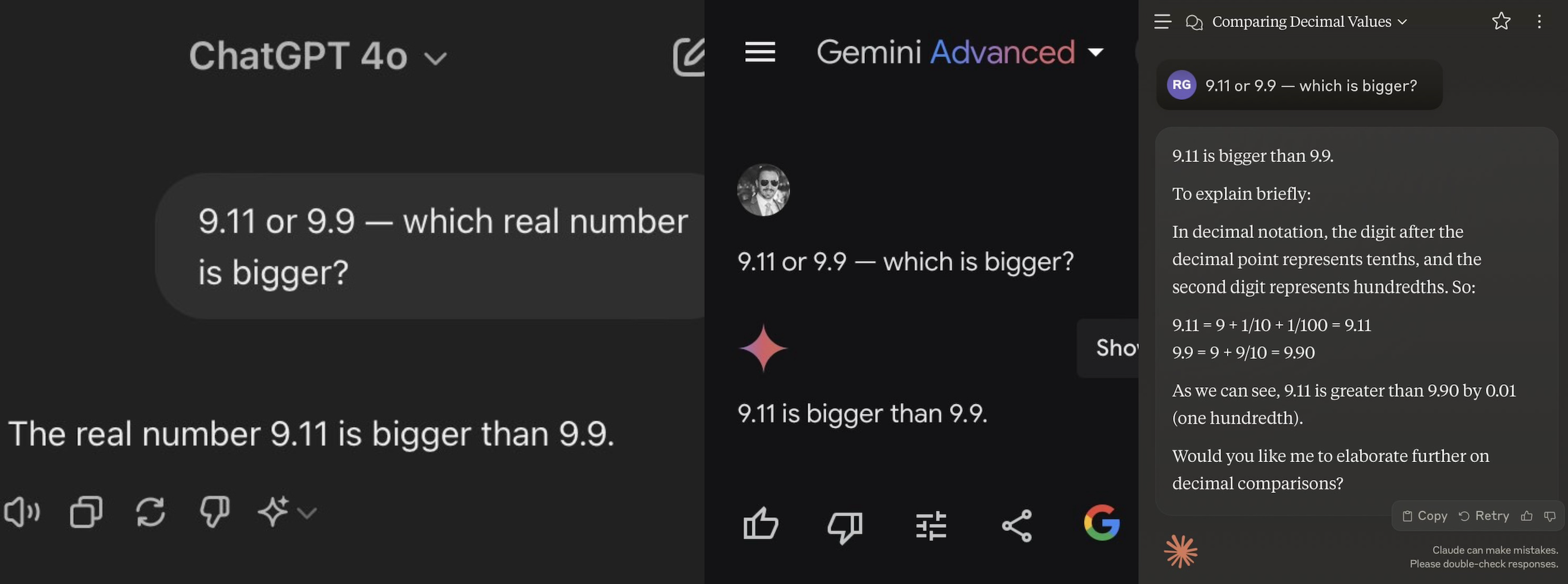
近日,一道看似简单的小学生数学题“9.11和9.9哪个更大”难倒了一众海内外知名的AI大模型。在测试的12个模型中,仅有阿里通义千问、百度文心一言等少数答对,而包括ChatGPT-4o在内的多个模型给出了错误答案。这些模型的错误在于错误地比较了小数点后的数字,显示了AI在处理数学问题上的局限性。
🧮 AI大模型的数学能力受到质疑,一道小学生难度的数学题“9.11和9.9哪个更大”难倒了一众知名AI模型。测试中,仅有阿里通义千问、百度文心一言等少数模型答对,而包括ChatGPT-4o在内的多个模型给出了错误答案。
🤖 大部分模型错误地比较了小数点后的数字,这反映了AI在理解数学语境上的不足。即使在明确了数学语境的情况下,如ChatGPT这样的大模型仍然答错。
🎓 行业人士指出,生成式语言模型在设计上更偏向于文字思维而非数字思维,这可能是导致它们在数学问题上表现不佳的原因。不过,通过针对性的语料训练,AI模型的理科能力有望得到提升。
格隆汇7月17日|据一财,一道小学生难度的数学题难倒了一众海内外AI大模型。9.11和9.9哪个更大?就此问题,记者测试了12个大模型,其中<u>阿里通义千问、百度文心一言、Minimax和腾讯元宝答对</u>,但<u>ChatGPT-4o、字节豆包、月之暗面kimi、智谱清言、零一万物万知、阶跃星辰跃问、百川智能百小应、商汤商量都答错了</u>,错法各有不同。大部分大模型在问答中都错误地比较了小数点后的数字,认为9.11大于9.9,考虑到数字涉及的语境问题,记者将其限定为在数学语境下,如ChatGPT这样的大模型也照样答错。在这背后,大模型数学能力较差是长期存在的问题,有行业人士认为,生成式的语言模型从设计上就更像文字思维而不是数字思维。不过,针对性地语料训练或许能在未来逐步提升模型的理科能力。