


Speculative decoding is emerging as a vital strategy to enhance high-throughput long-context inference, especially as the need for inference with large language models (LLMs) continues to grow across numerous applications. Together AI’s research on speculative decoding tackles the problem of improving inference throughput for LLMs that deal with long input sequences and large batch sizes. This research provides crucial insights into overcoming memory bottlenecks during inference, particularly when managing long-context scenarios.
Context and Challenges in Long-Context Inference
As the use of LLMs increases, the models are tasked with handling more extensive context lengths. Applications like information extraction from large document sets, synthetic data generation for fine-tuning, extended user-assistant conversations, and agent workflows all require the models to process sequences that span thousands of tokens. This demand for high-throughput processing at long context lengths presents a technical challenge, largely due to the extensive memory requirements for storing key-value (KV) caches. These caches are essential for ensuring the model can efficiently recall earlier parts of long input sequences.
Traditionally, speculative decoding, which leverages unused computational resources during memory-bound decoding phases, has yet to be considered suitable for high-throughput situations. The prevailing assumption was that decoding would be compute-bound for large batch sizes, and GPU resources would already be fully utilized, leaving no room for speculative techniques. However, Together AI’s research counters this assumption. They demonstrate that decoding becomes memory-bound again in scenarios with large batch sizes and long sequences, making speculative decoding a viable and advantageous approach.
Key Innovations: MagicDec and Adaptive Sequoia Trees
Together AI introduces two critical algorithmic advancements in speculative decoding: MagicDec and Adaptive Sequoia Trees, designed to enhance throughput under long-context and large-batch conditions.
1. MagicDec: The primary bottleneck during long-context, large-batch decoding is loading the KV cache. MagicDec addresses this by employing a fixed context window in the draft model, enabling the draft model to function more quickly than the target model. By fixing the context window size, the draft model’s KV cache is significantly smaller than that of the target model, which speeds up the speculative process. Interestingly, the approach also allows using a very large and powerful draft model. Using the full target model as the draft becomes feasible under this regime because the bottleneck no longer loads the model parameters.
MagicDec leverages several strategies from other models, like TriForce and StreamingLLM. It uses a StreamingLLM draft model, combining sliding window attention with an attention sink to reduce the KV cache size further. By structuring the speculative decoding in stages, MagicDec achieves even higher speedups, with more significant gains as the batch size increases.
2. Adaptive Sequoia Trees: Another key insight from Together AI’s research is that the length of input sequences influences how memory-bound the decoding process becomes. In other words, the longer the sequence, the more the decoding process relies on loading and maintaining the KV cache. Adaptive Sequoia Trees adapt to this situation by selecting the number of speculated tokens based on sequence length. The underlying principle is that, with longer sequences, more tokens should be speculated to maximize throughput.
The Sequoia algorithm, which Together AI references in their work, helps determine the optimal tree structure for speculative tokens. This structure balances the need to generate more tokens against the computational cost of verifying those tokens. As the tree size increases, the speculative decoding process can create more tokens per forward pass, thereby improving throughput.
Memory and Compute Trade-offs in Speculative Decoding
One of the fundamental challenges that Together AI addresses is understanding the balance between memory and compute requirements during decoding. Decoding involves two types of operations: those involving the model parameters and those related to the KV cache. As sequence lengths grow, the operations involving the KV cache become the dominant factor in memory consumption, and thus, decoding becomes memory-bound.
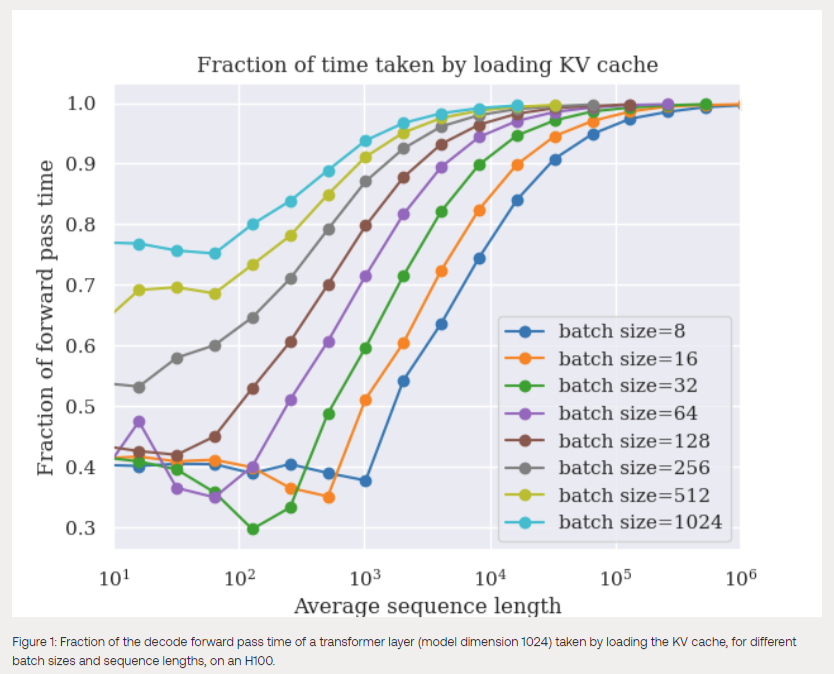
Through their detailed analysis of transformer layers during autoregressive decoding, Together AI demonstrates that at large batch sizes and long context lengths, the time to load the KV cache exceeds that required for computing model parameters. This is a significant insight because it implies that even with powerful GPUs, the model’s performance is bottlenecked by memory access, not computation, for long-context sequences. As a result, there is ample room for speculative techniques to use idle computing resources effectively.
Empirical Results
The researchers validate their theoretical models through empirical analysis, showing that speculative decoding can substantially improve performance. For instance, their results indicate that, under certain conditions, speculative decoding can achieve up to a 2x speedup for models like LLaMA-2-7B-32K and 1.84x speedup for LLaMA-3.1-8B, both on 8 A100 GPUs. These results are notable because they show that speculative decoding can be highly effective, even at scale, where large batch sizes and long sequences typically make inference slower and more memory-intensive.

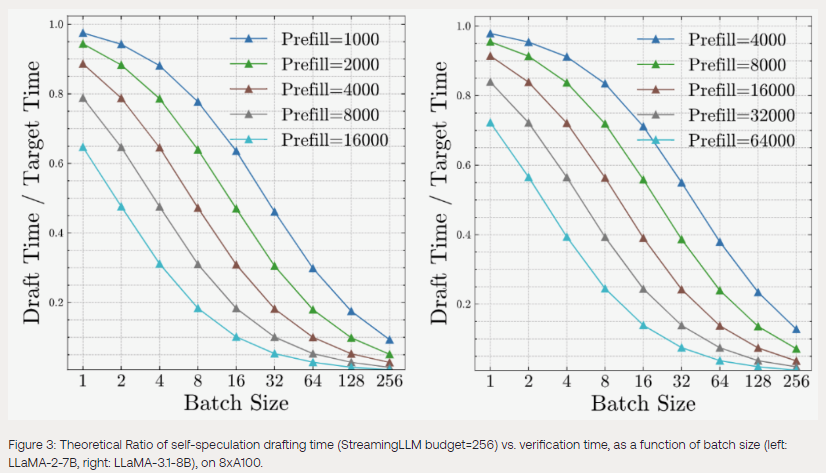
The researchers show that counterintuitively, larger batch sizes make speculative decoding more effective. As batch sizes increase, the draft-to-target cost ratio decreases, meaning that the computational cost of speculative decoding becomes relatively lower compared to the cost of verifying the generated tokens. This finding opens new possibilities for using speculative techniques in high-throughput, large-scale LLM deployments.
Conclusion
Together AI’s research on speculative decoding for long-context, high-throughput inference reshapes the understanding of how LLMs can be optimized for real-world, large-scale applications. By focusing on memory bottlenecks rather than purely computational constraints, this work demonstrates that speculative decoding can significantly enhance model throughput and reduce latency, especially for applications involving long input sequences. With innovations like MagicDec and Adaptive Sequoia Trees, speculative decoding is poised to become a key technique for improving LLM performance in long-context scenarios. It is vital for future AI-driven applications that rely on large-scale inference.
Sources
- https://www.together.ai/blog/speculative-decoding-for-high-throughput-long-context-inference https://arxiv.org/pdf/2408.11049
The post Together AI Optimizing High-Throughput Long-Context Inference with Speculative Decoding: Enhancing Model Performance through MagicDec and Adaptive Sequoia Trees appeared first on MarkTechPost.
