


LLMs like GPT-4, MedPaLM-2, and Med-Gemini perform well on medical benchmarks but need help to replicate physicians’ diagnostic abilities. Unlike doctors who gather patient information through structured questioning and examinations, LLMs often need more logical consistency and specialized knowledge, leading to inadequate diagnostic reasoning. Although they can assist in initial screenings by leveraging medical corpora, their responses can be inconsistent and fail to adhere to professional guidelines, particularly in complex or specialized cases. This gap highlights their limitations in providing reliable medical diagnoses.
Researchers from Zhejiang University and Ant Group have introduced the RuleAlign framework, which aims to align LLMs with specific diagnostic rules to improve their effectiveness as AI physicians. They developed a medical dialogue dataset, UrologyRD, focusing on rule-based urology interactions. Using preference learning, the model is trained to ensure that its responses follow established protocols without needing additional human annotation. Experimental results show that RuleAlign enhances the performance of LLMs in both single-round and multi-round evaluations, demonstrating its potential in medical diagnostics.
Medical LLMs are advancing rapidly in academia and industry, with efforts focused on integrating medical data into general LLMs through supervised fine-tuning (SFT). Notable examples include MedPaLM-2, Med-Gemini, and Chinese models like DoctorGLM and HuatuoGPT-II. These models often use specialized datasets, such as BianQueCorpus, to balance questioning and advice-giving abilities. Optimize LLMs through preference learning and reward models to enhance model alignment approaches like RLHF and DPO. Techniques like SLiC and SPIN refine alignment by combining loss functions, data augmentation, and iterative training.
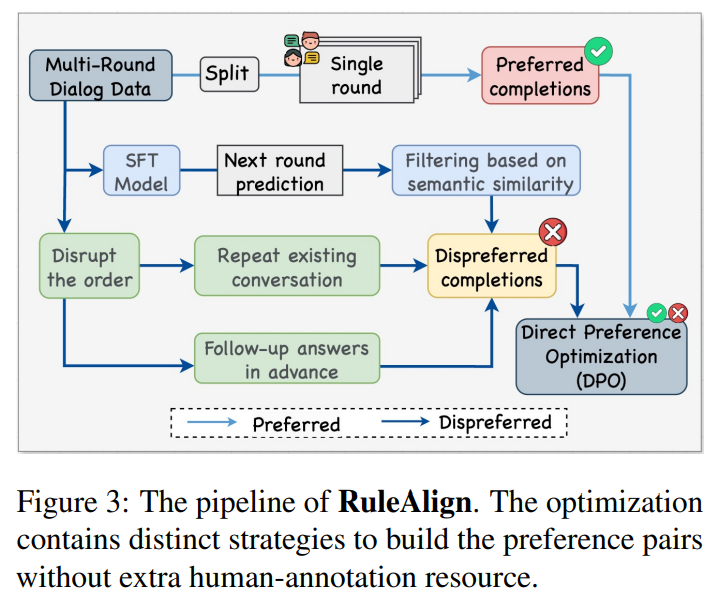
To create the UrologyRD dataset, researchers first collected detailed diagnostic rules by summarizing relevant medical conversations and extracting key guidelines. These rules focus on urology, specifying disease-related constraints and essential evidence for diagnosis. The dataset was generated by mapping disease names to broader categories and adapting dialogues using these rules. To align LLMs with human objectives, the RuleAlign framework employs preference learning. It optimizes LLM outputs by training with rule-based dialogues, distinguishing preferred and dispreferred responses, and refining through semantic similarity and dialogue order disruption to enhance diagnostic accuracy.
Single-round and multi-round tests are used to assess performance in evaluating LLMs for medical diagnosis. Metrics such as perplexity, ROUGE, and BLEU are applied in single-round tests. At the same time, SP testing evaluates the models on information completeness, guidance rationality, diagnostic logicality, clinical applicability, and treatment logicality. RuleAlign demonstrates superior performance, improving ROUGE and BLEU scores and reducing perplexity. It efficiently aligns LLM responses with diagnostic rules, although it sometimes struggles with hallucinations and logical consistency. The method’s optimization strategies, including semantic similarity and order disruption, significantly enhance model accuracy and coherence in generating medical dialogues.
In conclusion, the study introduces UrologyRD, a medical dialogue dataset based on diagnostic rules, and proposes RuleAlign, an innovative method for automatic preference pair synthesis and alignment. Experiments demonstrate RuleAlign’s effectiveness across various evaluation settings. Despite advancements in LLMs like GPT-4, MedPaLM-2, and Med-Gemini, which perform competitively with human experts, challenges remain in their diagnostic capabilities, especially inpatient information collection and reasoning. RuleAlign aims to address these issues by aligning LLMs with diagnostic rules, potentially advancing research in AI-driven medical applications, and improving the role of LLMs as AI physicians.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and LinkedIn. Join our Telegram Channel.
If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
The post Enhancing Diagnostic Accuracy in LLMs with RuleAlign: A Case Study Using the UrologyRD Dataset appeared first on MarkTechPost.
