


The primary challenge in scaling large-scale AI systems is achieving efficient decision-making while maintaining performance. Distributed AI, particularly multi-agent reinforcement learning (MARL), offers potential by decomposing complex tasks and distributing them across collaborative nodes. However, real-world applications face limitations due to high communication and data requirements. Traditional methods, like model predictive control (MPC), require precise system dynamics and often oversimplify nonlinear complexities. While promising in areas like autonomous driving and power systems, MARL still struggles with efficient information exchange and scalability in complex, real-world environments due to communication constraints and impractical assumptions.
Peking University and King’s College London researchers developed a decentralized policy optimization framework for multi-agent systems. By leveraging local observations through topological decoupling of global dynamics, they enable accurate estimations of international information. Their approach integrates model learning to enhance policy optimization with limited data. Unlike previous methods, this framework improves scalability by reducing communication and system complexity. Empirical results across diverse scenarios, including transportation and power systems, demonstrate its effectiveness in handling large-scale systems with hundreds of agents. It offers superior performance in real-world applications with limited communication and heterogeneous agents.
In the decentralized model-based policy optimization framework, each agent maintains localized models that predict future states and rewards by observing its actions and the states of its neighbors. Policies are optimized using two experience buffers: one for real environment data and another for model-generated data. A branched rollout technique is used to prevent compounding errors by starting model rollouts from random states within recent trajectories to improve accuracy. Policy updates incorporate localized value functions and leverage PPO agents, guaranteeing policy improvement by gradually minimizing approximation and dependency biases during training.
The Methods outline a networked Markov Decision Process (MDP) with multiple agents represented as nodes in a graph. Each agent communicates with neighbors to optimize a decentralized reinforcement learning policy to improve local rewards and global system performance. Two system types are discussed: Independent Networked Systems (INS), where agent interactions are minimal and ξ-dependent systems, which account for diminishing influence with distance. A model-based learning approach approximates system dynamics, ensuring monotonic policy improvements. This method is tested in large-scale scenarios like traffic control and power grids, focusing on decentralized agent control for optimal performance.
The study demonstrates the superior performance of a decentralized MARL framework, tested in both simulators and real-world systems. Compared to centralized baselines like MAG and CPPO, the approach significantly reduces communication costs (5-35%) while improving convergence and sample efficiency. The method performed well across control tasks, such as vehicle and traffic signal management, pandemic network control, and power grid operations, consistently outperforming baselines. Shorter rollout lengths and optimized neighbor selection enhanced model predictions and training outcomes. These results highlight the framework’s scalability and effectiveness in managing large-scale, complex systems.
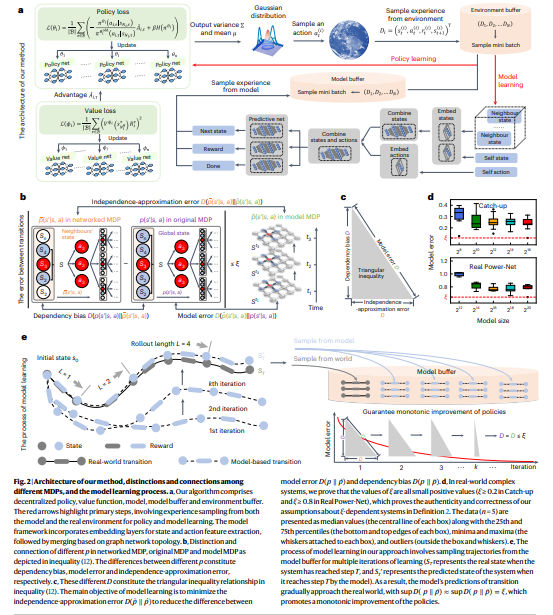
In conclusion, the study presents a scalable MARL framework effective for managing large systems with hundreds of agents, surpassing the capabilities of previous decentralized methods. The approach leverages minimal information exchange to assess global conditions, akin to the six degrees of separation theory. It integrates model-based decentralized policy optimization, which improves decision-making efficiency and scalability by reducing communication and data needs. By focusing on local observations and refining policies through model learning, the framework maintains high performance even as the system size grows. The results highlight its potential for advanced traffic, energy, and pandemic management applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and LinkedIn. Join our Telegram Channel.
If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
The post Scalable Multi-Agent Reinforcement Learning Framework for Efficient Decision-Making in Large-Scale Systems appeared first on MarkTechPost.
