
Published on October 24, 2024 4:49 PM GMT
ArXiv paper.
Thanks to Nora Belrose, Buck Shlegeris, Jan Hendrik Kirchner, and Ansh Radhakrishnan for guidance throughout the project.
Scalable oversight studies methods of training and evaluating AI systems in domains where human judgment is unreliable or expensive, such as scientific research and software engineering in complex codebases. Most work in this area has focused on methods of improving the quality of labels. Recent work by Burns et al. (2023) considers the complementary problem of training models with low-quality labels, finding that large pretrained models often have an inductive bias towards producing correct answers. In practice, however, neither label quantity nor quality is fixed: practitioners face a quantity-quality tradeoff. In this paper, we explore the microeconomics of the quantity-quality tradeoff on binary NLP classification tasks used in Burns et al. (2023). While sample-efficient learning has been studied extensively, little public research has focused on scalable elicitation: eliciting capabilities from pretrained models subject to labeling cost constraints. We find that this setting has novel dynamics caused by the tradeoff between label quantity and quality, as well as the model's existing latent capabilities. We observe three regimes of eliciting classification knowledge from pretrained models using supervised finetuning: quantity-dominant, quality-dominant, and a mixed regime involving the use of low- and high-quality data together to attain higher accuracy at a lower cost than using either alone. We explore sample-efficient elicitation methods that make use of two datasets of differing qualities, and establish a Pareto frontier of scalable elicitation methods that optimally trade off labeling cost and classifier performance. We find that the accuracy of supervised fine-tuning can be improved by up to 5 percentage points at a fixed labeling budget by adding a few-shot prompt to make use of the model's existing knowledge of the task.
How does this help with AI safety?
Ensuring safety of capable AI systems would be a lot easier if humans had access to all of the knowledge of the AIs they’re supervising. This is the broad framing that has motivated my interest in the Eliciting Latent Knowledge agenda. In this work, we try to measure how effective various elicitation strategies are (in binary classification settings) by plotting accuracy versus cost given various assumptions about the costs of low- and high-quality labels. We attempt to investigate scalable oversight as a quantitative rather than qualitative problem (the framing laid out in the post is roughly what motivates this work).
While I think our work has somewhat generalizable insights for non-scheming models, there may be additional difficulties when trying to elicit knowledge from schemers because intentionally misgeneralizing policies may be more salient than the policies we want to elicit for some distributions of inputs.
Summary of findings
Here are two of our findings:
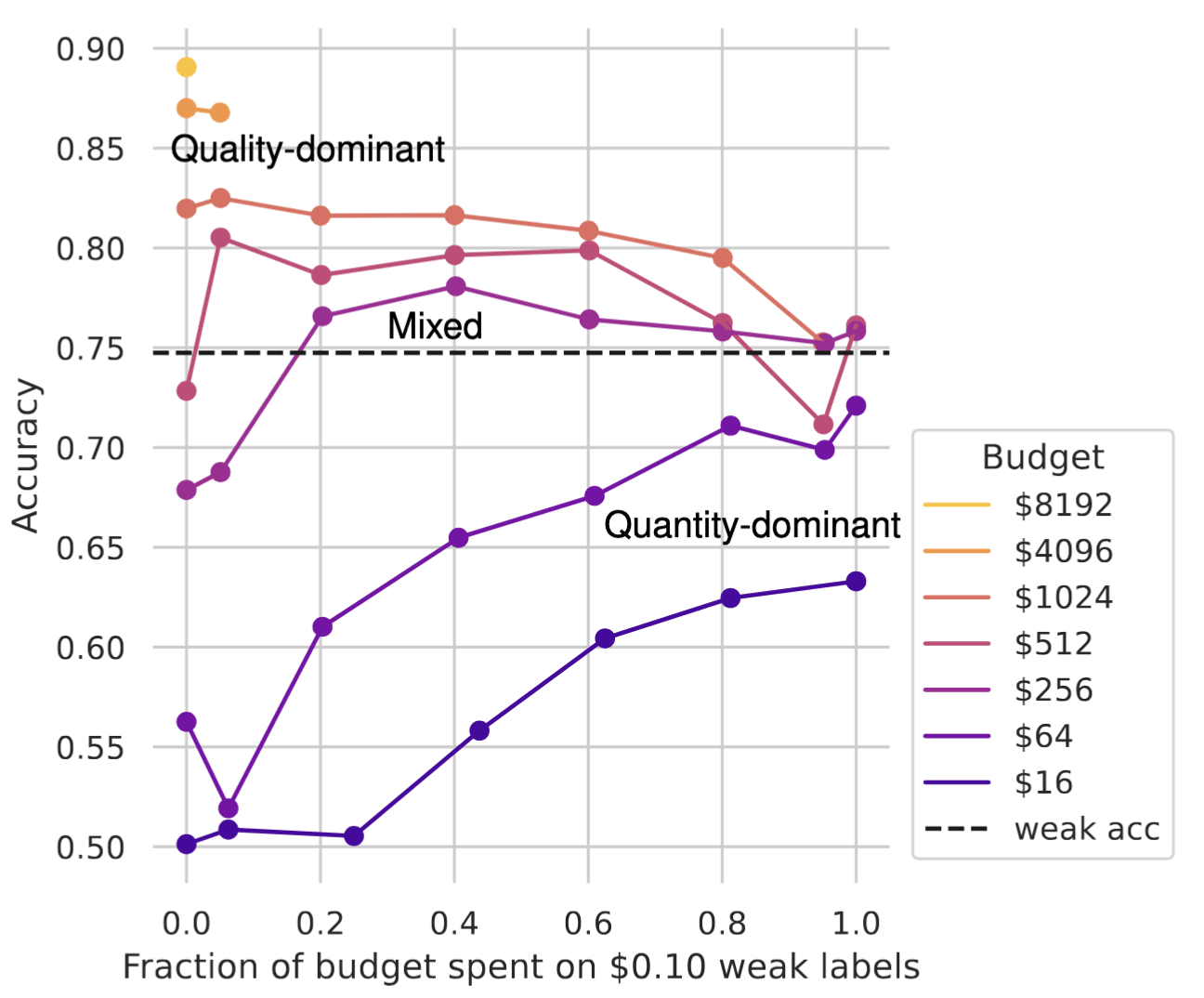
1. There exists a “mixed” regime where some budget should be spent on a large quantity of low-quality labels before training on some high-quality labels
Here, we arbitrarily define high-quality labels to cost $1 and weak labels $0.10. So, along the x-axis, one high-quality label is given up for every 10 weak labels used. The model is sequentially trained on low- then high-quality labels. Different budgets produce 3 regimes with distinct optimal budget allocations:
Quality-dominant (budget≥$1024): No budget should be allocated to weak labels
Quantity-dominant (≤$64): All budget should be allocated to weak labels
Mixed ($256≤budget<$1024): Peak of the accuracy curve is somewhere in the middle
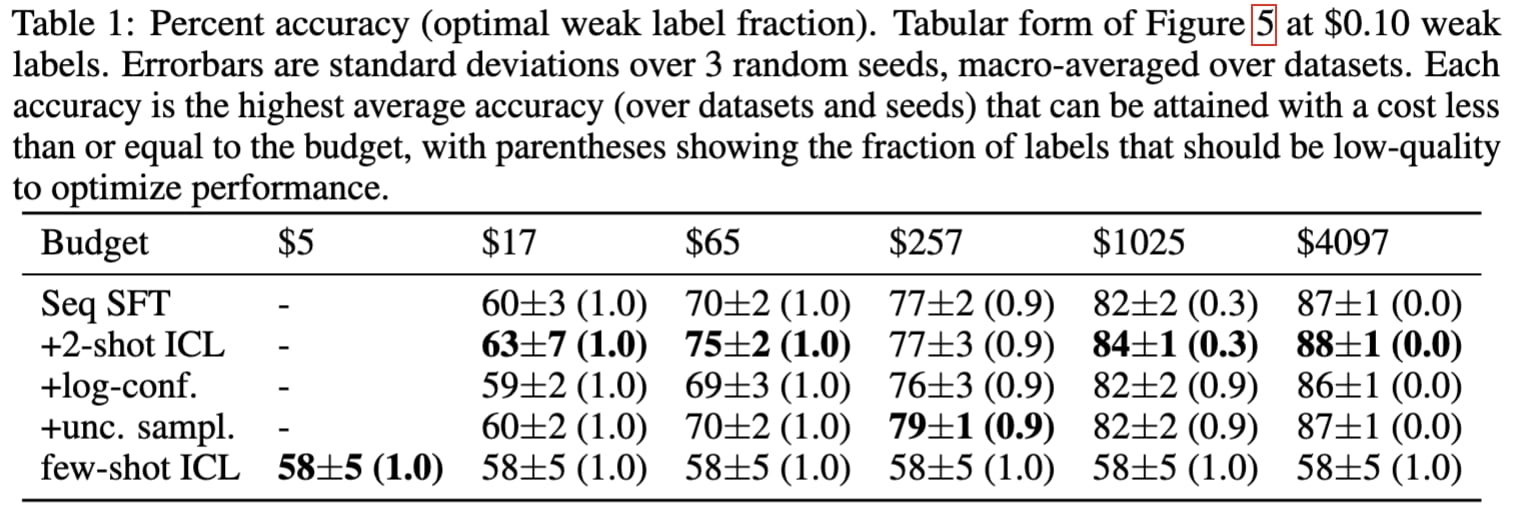
2. Increasing the salience of the task with a few-shot prompt consistently increases the sample-efficiency of SFT compared to either few-shot prompting or SFT alone.
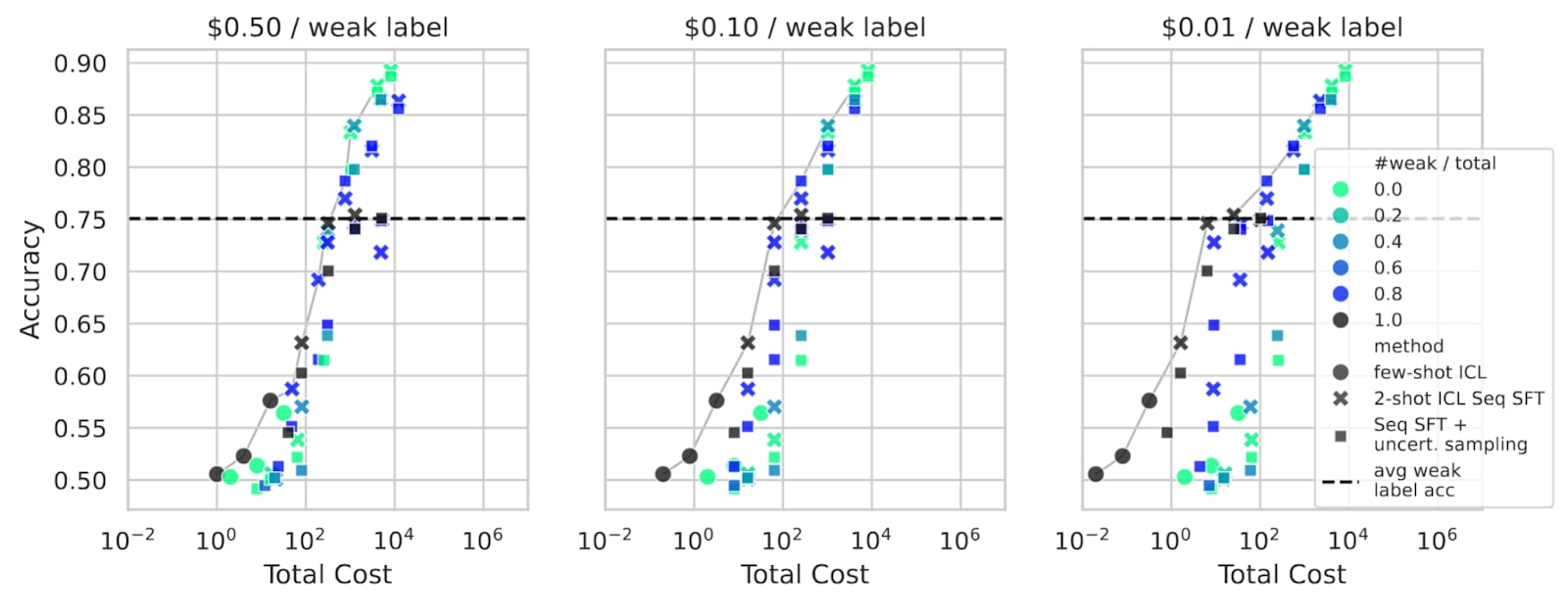
We think that more research should be aimed at expanding the Pareto frontier of labeling cost and accuracy in realistic elicitation settings, and answering related questions like “How sample efficient should we expect elicitation to be?”
Discuss
