
在开发 Docmatix 时,我们发现经其微调的 Florence-2 在 DocVQA 任务上表现出色,但在基准测试中得分仍比较低。为了提高基准测试得分,我们必须在 DocVQA 数据集上进一步对模型进行微调,以学习该基准测试的语法风格。有意思的是,人类评估者认为经额外微调后,模型的表现似乎反而不如仅在 Docmatix 上微调那么好,因此我们最后决定仅将额外微调后的模型用于消融实验,而公开发布的还是仅在 Docmatix 上微调的模型。
尽管模型生成的答案在语义上与参考答案一致 (如图 1 所示),但基准测试的得分却较低。这就引出了一个问题: 我们应该微调模型以改进在既有指标上的表现,还是应该开发与人类感知更相符的新指标?
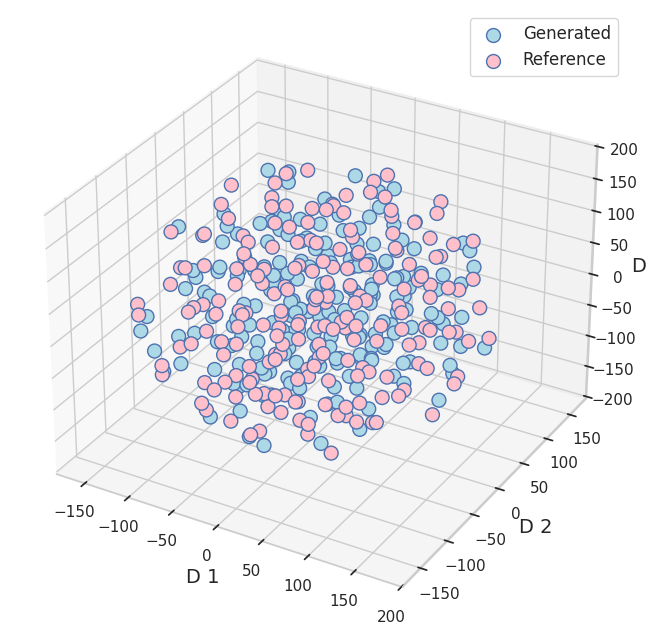
图 1: Docmatix 数据集微调模型零样本生成的答案与参考答案之间的 t-SNE 图
背景
社区最近很关注分布外 (out-of-distribution,OOD) 评估,即利用诸如零样本之类的方法将模型的能力迁移至未见过的 VQA 任务抑或是对一个 VQA 数据集进行微调并在另一个 VQA 数据集上进行评估。这一转变与用于微调视觉语言模型 (VLM) 的合成数据集 (例如 Docmatix、SciGraphQA、SimVQA) 的日渐兴起紧密相关。
一直以来,VQA 准确度一直是评估模型性能的主要指标,其方法是计算模型预测答案与人工标注的一组参考答案之间的精确字符串匹配率。因为传统的 VQA 评估遵循独立同分布 (independent and identically distributed,IID) 范式,其训练数据和测试数据分布相似,而传统的模型训练是遵循此假设的,所以此时该指标的效果很好,详情请参阅
但在 OOD 场景下,由于格式、专业度以及表达等方面的差异,生成的答案尽管正确,但可能与参考答案不尽匹配。图 1 完美地展示了这种情况,图中我们将零样本生成的文本描述与合成数据集中的参考文本描述进行了比较。指令生成的数据集与人工标注的数据集之间的差异尤甚。目前已有一些
方法


图 2: 来自 Docmatix 和 DocVQA 测试集的问答对示例。注: 此处未显示相应的图像。
尽管 Docmatix 和 DocVQA 中问答对的内容相似,但它们的风格却有着显著差异。此时,CIDER、ANLS 以及 BLEU 等传统指标对于零样本评估而言可能过于严格。鉴于从 t-SNE 中观察到的嵌入的相似性 (图 1),我们决定使用一个不同于以往的新评估指标: LAVE (LLM-Assisted VQA Evaluation,LLM 辅助 VQA 评估),以期更好地评估模型在未见但语义相似的数据集上的泛化能力。
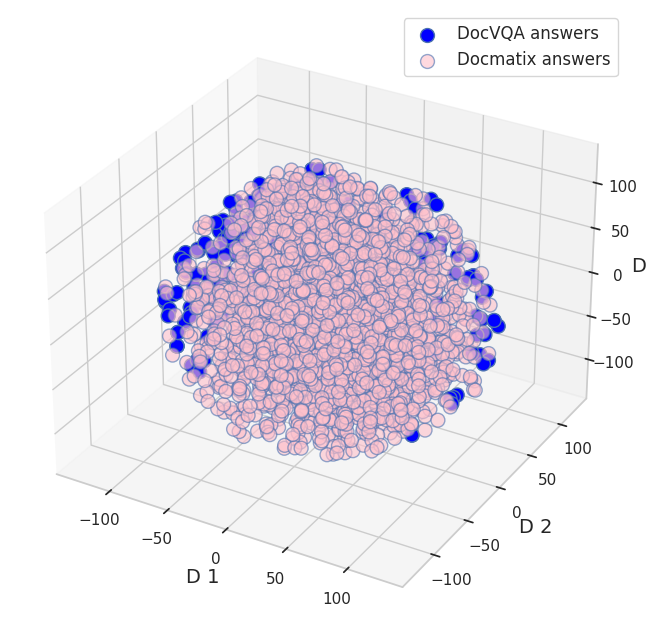
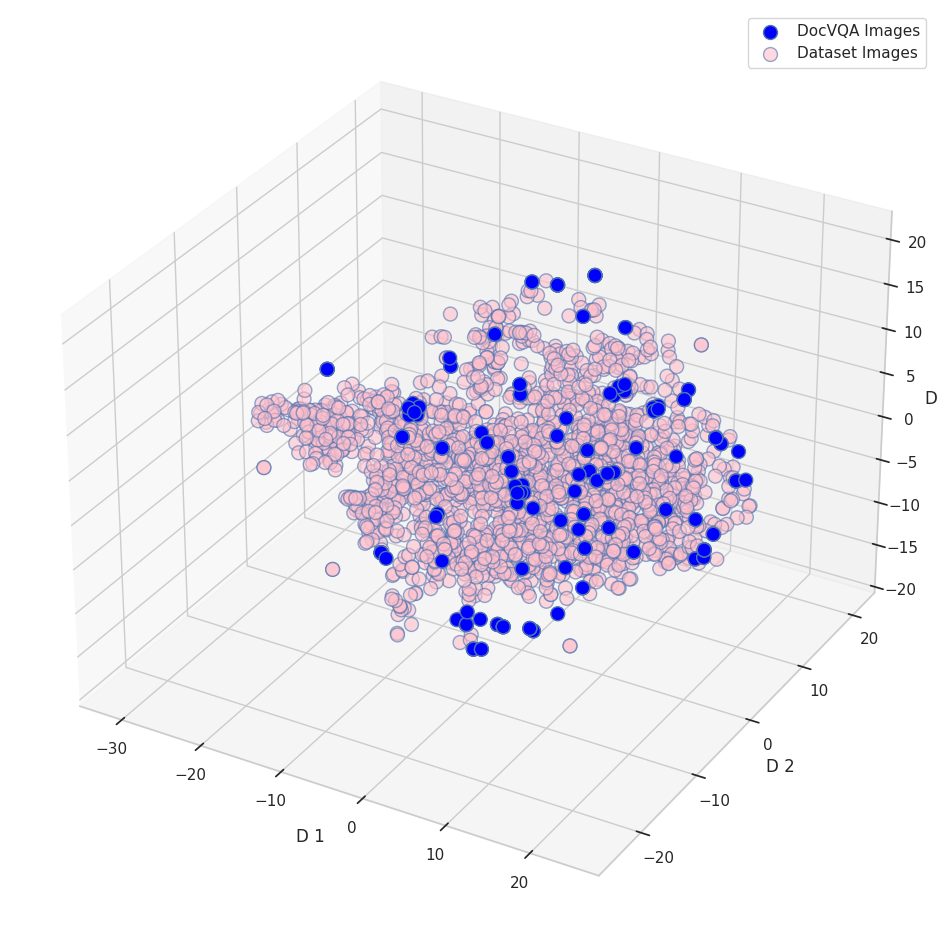
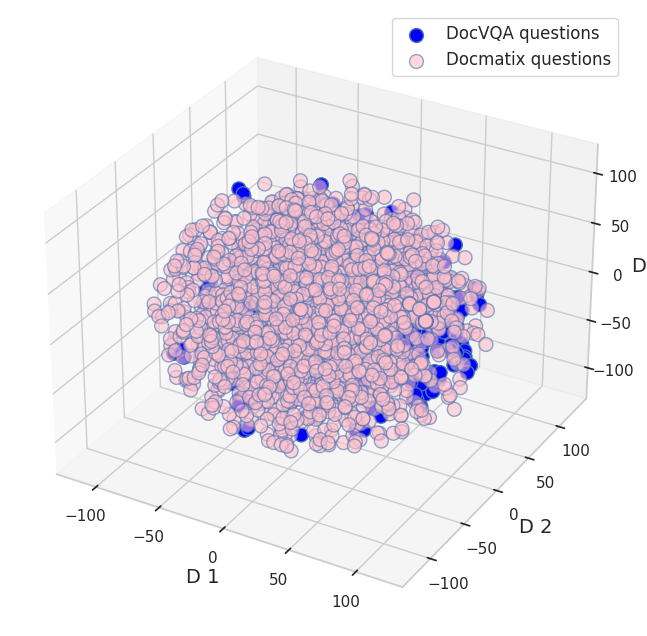
图 3: Docmatix 和 DocVQA 数据集中的问题、答案以及图像特征的 t-SNE 图
评估时,我们选择
关于 LAVE
我们遵循
我们撰写了任务描述并在其后加上了指令 “在评分之前给出理由” 以要求 LLM 给出评分理由。每个演示都包含一个问题、一组参考答案、候选答案、答案得分及其理由。在提示中,我们还要求 “仅提供一个评分” 以避免因逐句分析带来的多个评分。
task_description ="""You are given a question, a set of gold-standard reference answers written byexperts, and a candidate answer. Please rate the accuracy of the candidate answer for the questionconsidering the reference answers. Use a scale of 1-3, with 1 indicating an incorrect or irrelevantanswer, 2 indicating an ambiguous or incomplete answer, and 3 indicating a correct answer.Give the rationale before rating. Provide only one rating.THIS IS VERY IMPORTANT:A binary question should only be answered with 'yes' or 'no',demonstrations = [ {otherwise the candidate answer is incorrect."""
"question": "What's the weather like?",
"reference_answer": ["sunny", "clear", "bright", "sunny", "sunny"],
"generated_answer": "cloudy" }]
评分函数
给定 LLM 为测试样本生成的提示,我们从最后一个字符 (为 1、2 或 3) 中提取评分,并将其缩放至 [0, 1] 范围内: ,以获取最终评分。
结果
各指标得分如下:
| 指标 | CIDER | BLEU | ANLS | LAVE |
|---|---|---|---|---|
| 得分 | 0.1411 | 0.0032 | 0.002 | 0.58 |
几个生成案例

图 4: Docmatix 测试子集中的一个问题、参考答案、模型生成的答案以及 Llama 给出的评分及理由。

图 5: Docmatix 测试子集中的一个问题、参考答案、模型生成的答案以及 Llama 给出的评分及理由。
现有的 VQA 系统评估标准是否过于僵化了?我们还需要微调吗?
当使用 LLM 来评估答案时,我们答案的准确率提高了大约 50%,这表明虽未遵循严格的格式,答案也可能是正确的。这表明我们目前的评估指标可能过于僵化。值得注意的是,本文并不是一篇全面的研究论文,因此需要更多的消融实验来充分了解不同指标对合成数据集零样本性能评估的有效性。我们希望社区能够以我们的工作为起点,继续深化拓展下去,从而改进合成数据集背景下的零样本视觉语言模型评估工作,并探索能够超越提示学习的其它更有效的方法。
参考文献
@inproceedings{cascante2022simvqa,
title={Simvqa: Exploring simulated environments for visual question answering}, author={Cascante-Bonilla, Paola and Wu, Hui and Wang, Letao and Feris, Rogerio S and Ordonez, Vicente}, booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, pages={5056--5066}, year={2022}}@article{hu2024mplug,title={mplug-docowl 1.5: Unified structure learning for ocr-free document understanding},
author={Hu, Anwen and Xu, Haiyang and Ye, Jiabo and Yan, Ming and Zhang, Liang and Zhang, Bo and Li, Chen and Zhang, Ji and Jin, Qin and Huang, Fei and others}, journal={arXiv preprint arXiv:2403.12895}, year={2024}}@article{agrawal2022reassessing,title={Reassessing evaluation practices in visual question answering: A case study on out-of-distribution generalization},
author={Agrawal, Aishwarya and Kaji{\'c}, Ivana and Bugliarello, Emanuele and Davoodi, Elnaz and Gergely, Anita and Blunsom, Phil and Nematzadeh, Aida}, journal={arXiv preprint arXiv:2205.12191}, year={2022}}@inproceedings{li2023blip, title={Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models}, author={Li, Junnan and Li, Dongxu and Savarese, Silvio and Hoi, Steven}, booktitle={International conference on machine learning}, pages={19730--19742}, year={2023}, organization={PMLR}}@inproceedings{manas2024improving, title={Improving automatic vqa evaluation using large language models}, author={Ma{\~n}as, Oscar and Krojer, Benno and Agrawal, Aishwarya}, booktitle={Proceedings of the AAAI Conference on Artificial Intelligence}, volume={38}, number={5}, pages={4171--4179}, year={2024}}@article{li2023scigraphqa, title={Scigraphqa: A large-scale synthetic multi-turn question-answering dataset for scientific graphs}, author={Li, Shengzhi and Tajbakhsh, Nima}, journal={arXiv preprint arXiv:2308.03349}, year={2023}}
英文原文:
https://hf.co/blog/zero-shot-vqa-docmatix 原文作者: Dana Aubakirova,Andres Marafioti
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
