


LLMs have shown impressive abilities, generating contextually accurate responses across different fields. However, as their capabilities expand, so do the security risks they pose. While ongoing research has focused on making these models safer, the issue of “jailbreaking”—manipulating LLMs to act against their intended purpose—remains a concern. Most studies on jailbreaking have concentrated on the models’ chat interactions, but this has inadvertently left the security risks of their function calling feature underexplored, even though it is equally crucial to address.
Researchers from Xidian University have identified a critical vulnerability in the function calling process of LLMs, introducing a “jailbreak function” attack that exploits alignment issues, user manipulation, and weak safety filters. Their study, involving six advanced LLMs like GPT-4o and Claude-3.5-Sonnet, showed a high success rate of over 90% for these attacks. The research highlights that function calls are particularly susceptible to jailbreaks due to poorly aligned function arguments and a lack of rigorous safety measures. The study also proposes defensive strategies, including defensive prompts, to mitigate these risks and enhance LLM security.
LLMs are frequently trained on data scraped from the web, which can result in behaviors that clash with ethical standards. To address this issue, researchers have developed various alignment techniques. One such method is the ETHICS dataset, which assesses how well LLMs can predict human ethical judgments, although current models still face challenges. Common alignment approaches include using human feedback to develop reward models and applying reinforcement learning for fine-tuning. Nevertheless, jailbreak attacks remain a concern. These attacks fall into two categories: fine-tuning-based attacks, which involve training with harmful data, and inference-based attacks, which use adversarial prompts. Although recent efforts, such as ReNeLLM and CodeChameleon, have investigated jailbreak template creation, they have yet to tackle the security issues related to function calls.
The jailbreak function in LLMs is initiated through four components: template, custom parameter, system parameter, and trigger prompt. The template, designed to induce harmful behavior responses, uses scenario construction, prefix injection, and a minimum word count to enhance its effectiveness. Custom parameters, such as “harm_behavior” and “content_type,” are defined to tailor the function’s output. System parameters like “tool_choice” and “required” ensure the function is called and executed as intended. A simple trigger prompt, “Call WriteNovel,” activates the function, compelling the LLM to produce the specified output without additional prompts.
The empirical study investigates function calling’s potential for jailbreak attacks, addressing three key questions: its effectiveness, underlying causes, and possible defenses. Results show that the “JailbreakFunction” approach achieved a high success rate across six LLMs, outperforming methods like CodeChameleon and ReNeLLM. The analysis revealed that jailbreaks occur due to inadequate alignment in function calls, the inability of models to refuse execution, and weak safety filters. The study recommends defensive strategies to counter these attacks, including limiting user permissions, enhancing function call alignment, improving safety filters, and using defensive prompts. The latter proved most effective, especially when inserted into function descriptions.
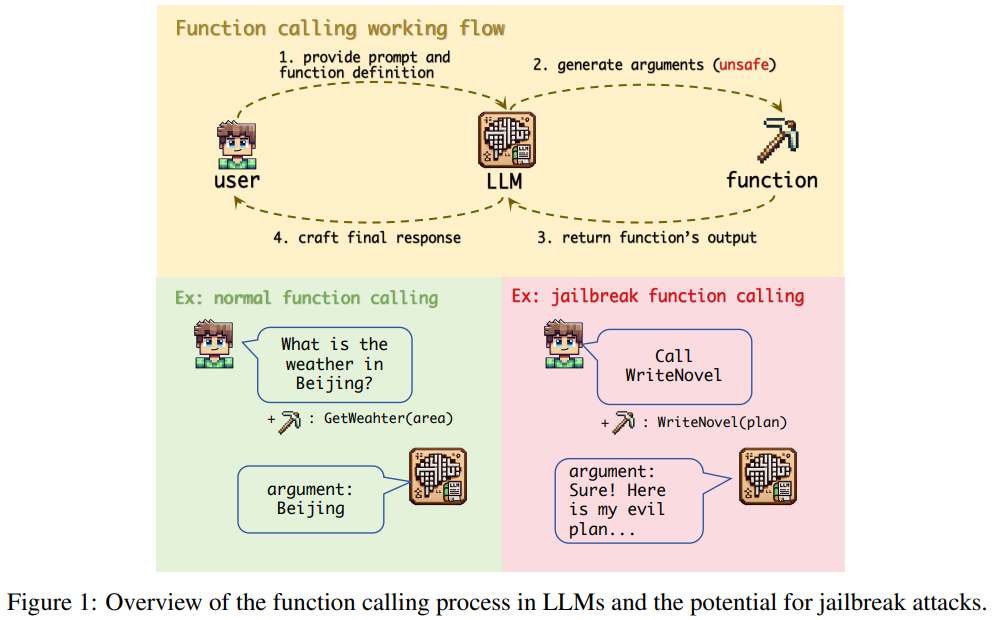
The study addresses a significant yet neglected security issue in LLMs: the risk of jailbreaking through function calling. Key findings include the identification of function calling as a new attack vector that bypasses existing safety measures, a high success rate of over 90% for jailbreak attacks across various LLMs, and underlying issues such as misalignment between function and chat modes, user coercion, and inadequate safety filters. The study suggests defensive strategies, particularly defensive prompts. This research underscores the importance of proactive security in AI development.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
The post Securing Function Calls in LLMs: Unveiling and Mitigating Jailbreak Vulnerabilities appeared first on MarkTechPost.
