

首先开篇上来 直接给了旧的时间线和新的时间线
取消了B100系列(原本预计30W颗 HGX8卡) 延后了B200系列从大批量(原本B200大概预期是20W颗左右 HGX 8卡)跟rack系列无关
改成了B200小批量(数量未知 还是HGX 8卡)跟rack系列依然无关
而最重要的是rack系列的GB200 NVL36/72 实际上只延误了半个季度 大概是一个半月 而不是大家想象中的一个季度到两个季度(更乐观的预期是 不会延误 首批NVL36将于9月交付 倒时候也可以跟踪一下)
新增的rack系列GB200A ultra NVL36(风冷)系列(明年Q3推出) 算力和大致概念如下图(但是并非NVL 64或者GB200A系列)
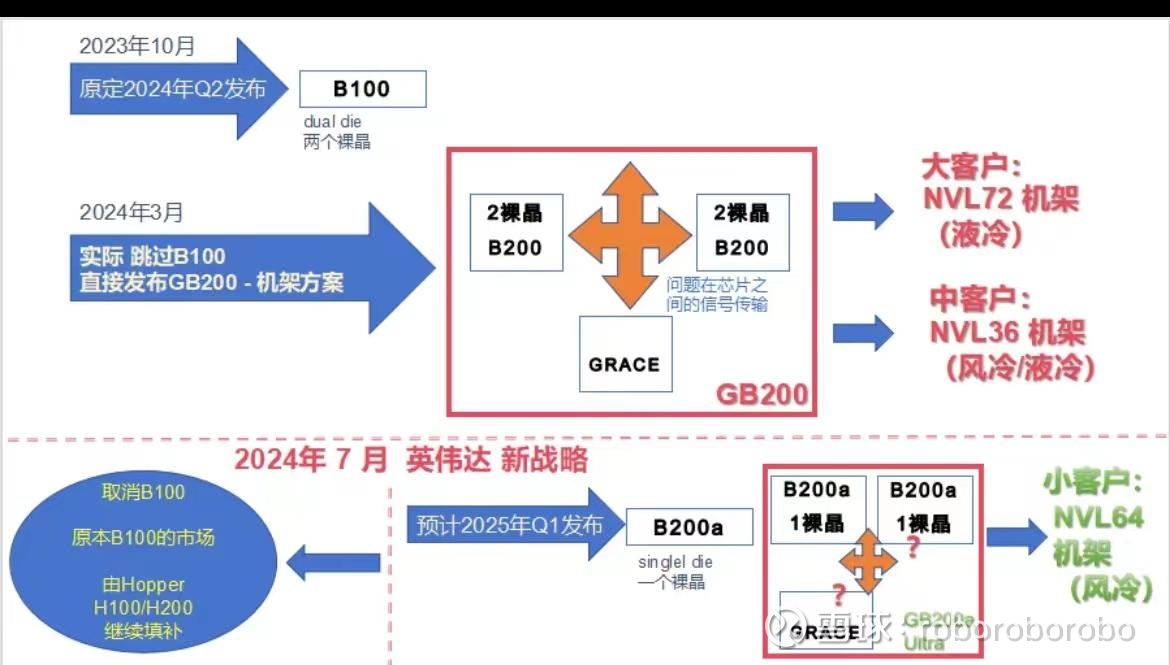

发生一系列的原因大家应该也都知道了 就是cowos-L良率的问题 但是台积电本身就有cowos-l产能紧缺的问题 cowos-s是成熟的工艺 产能比较充足 为了不妨碍B200系列和GB200 rack正常出货(仅延后半个Q) 相当于做了牺牲直接砍掉了B100 用比较充足的cowos-s去流片B200a系列(还要改设计 虽然写作B200A 但是实际上差不多是H100一样的单die) 所以差不多B200A是明年Q2的样子正式出货

简单来说 之后还会有B20系列 本质上和B200a差不多 都是单die小算力 卖组网的网络附加率多赚零配件钱的rack方案来扩充产品体系(之后会谈什么叫做网络附加率 nv真会做生意)
所以B200a本身还是8卡服务器 目前以带宽和算力来看 似乎还不如H200系列(双die高hbm vs 单die低hbm)而B200a ultra肯定直接盯着rack+风冷省小公司能耗指标这点上
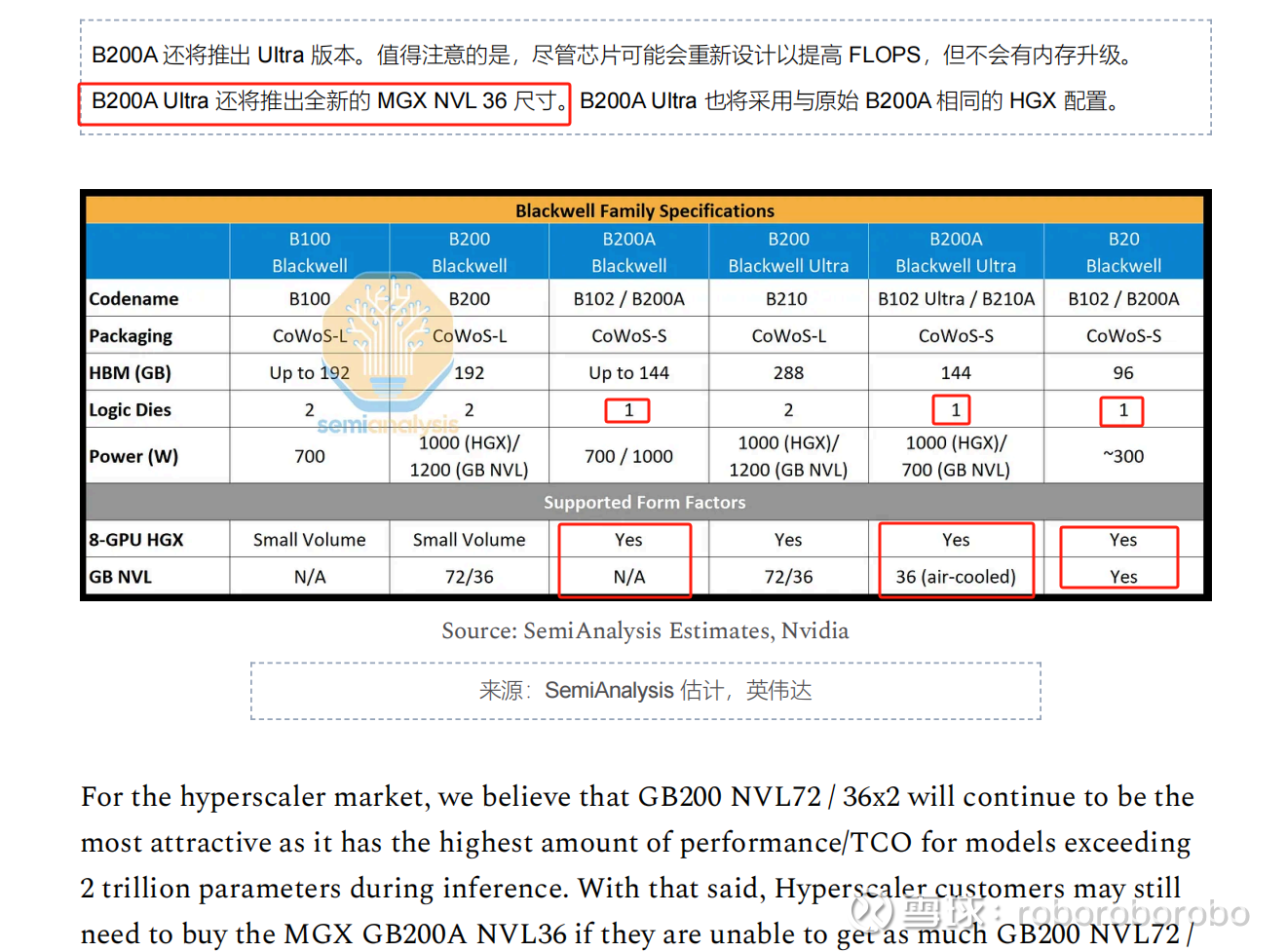
很显然 B200a初期只有8卡方案 而我们在讨论的新的rack架构 主要就是B200a ultra的 nvl36方案 但是这个方案推出的时间比较晚 时间在明年Q3左右


MGX B200a ultra nvl36方案很明显 不是给大型csp和nsp大厂用的 因为算力密度显然是比不上nvl36和nvl72 同样组成大规模训练集群的话 需要的功耗 基建 场地 配套设施就更多 收敛比也不够 性价比就非常低(同等算力密度估计总体价格是差不多的)
主要针对的客户是能耗指标不高的 新云小客户和小企业 而且可能主要用于推理 对于训练的效率未知 密度肯定不及专门训练的十万卡以上集群的

这里就要说一下啥叫网络附加率 这个词 翻译的挺魔性
本质上就是nv想卖成套的网络互联组网方案 增加零配件的用量来提高asp和毛利
8卡时代 很简单 核心占比就是GPU的asp 然后还有网卡和光模块 交换机 内容非常简单
但是经常有客户 例如为了推理需求 常常通过减少网卡 光模块的采购来节约成本
打个比方说 训练满配就是8卡GPU对应8网卡 光模块是满配
但是如果做推理 可以以8卡GPU对应4网卡 2网卡的方式去搭建 会省不少网络配件的钱 实际上光模块的配置就减少了很多 所以A和H时代 如果用GPU配比去计算光模块数量 大部分时候总是对不上
nv就反其道而行 我可以适当降低GPU和交换机的利润 但是你必须打包给你满配rack的组网架构(比如配套网卡 光模块 铜缆连接器 电源) mgx com tray 无论bianca还是ariel都必须满配互联速率
nv以比较好的折扣去卖GPU(一般GPU不会给太多折扣 但是例如交换机 比如QM系列和SP以太网系列 大客户买折扣不少)而靠网络零配件赚钱成为了现在的趋势
然后搭配这比如光模块 铜缆连接器 电源 液冷这类硬件强打强卖给客户 从零配件这里赚50%毛利以上(最典型就是光模块 问xc啥的采购回来650刀 卖客户1200刀啥的 ACC 铜缆连接器都差不多 50%毛利的附加率 )
配件卖的越多 nv就越赚钱
然后SA继续下调传统8卡 HGX的销量 因为B200A的 HGX连跑新云客户的基础开源模型LLAMA3 405B的大模型都非常吃力(真别傻乎乎信什么国产算力做的广告他们能跑)
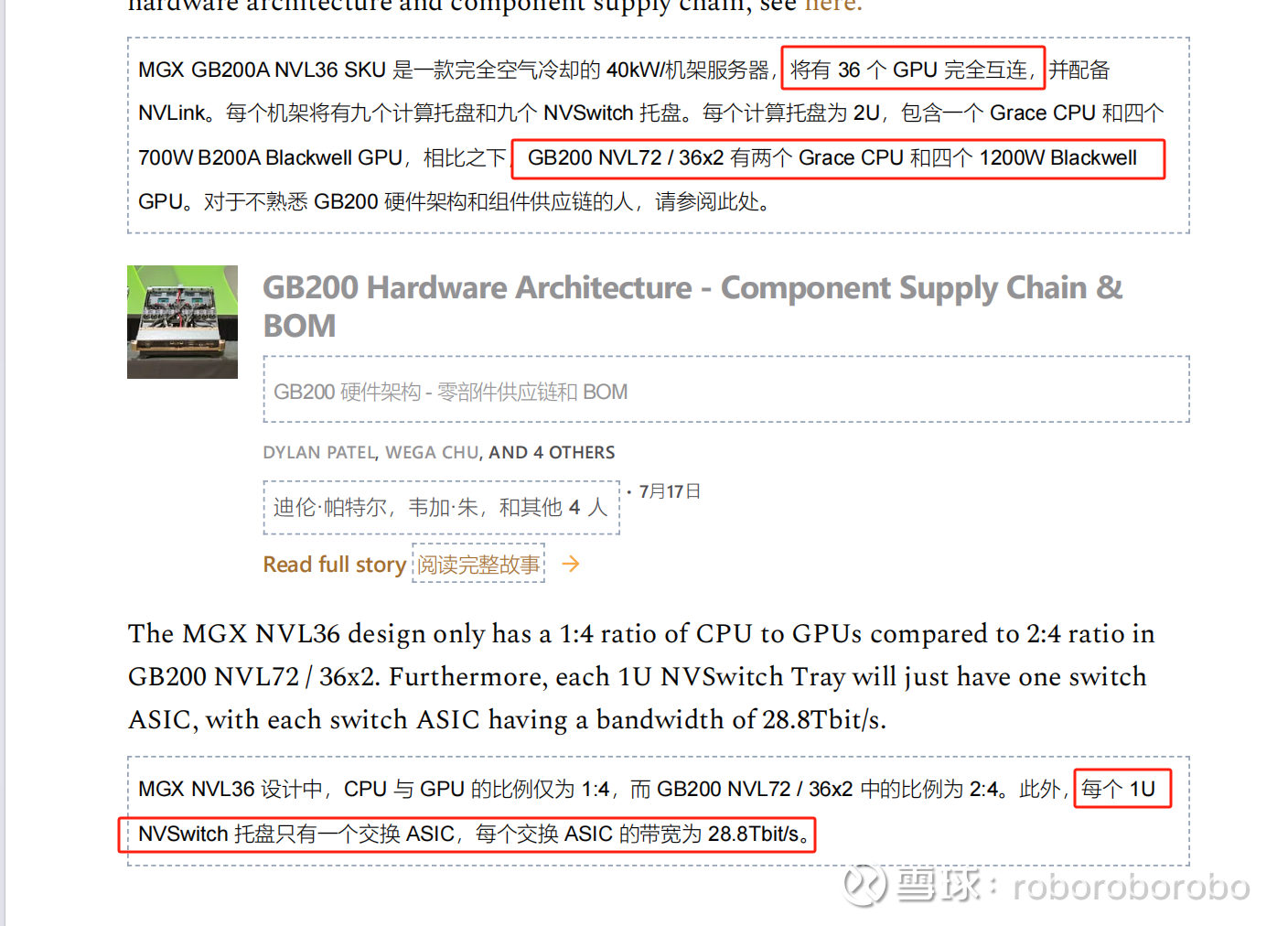
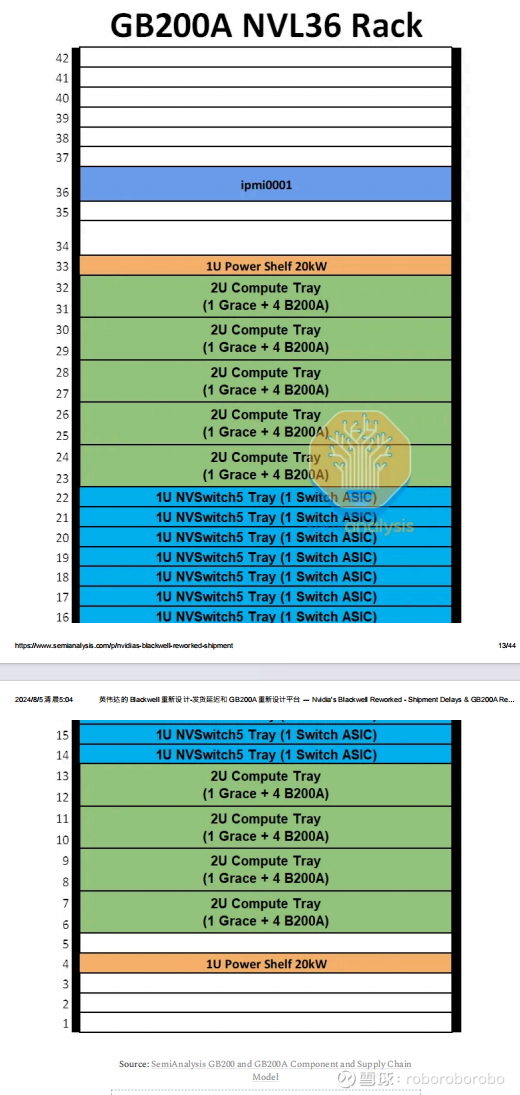

MGX GB200A ultra NVL36呼之欲出(请记住 这是B200A ultra组成的 明年Q3才发售)
问题来了 零配件到底用多少 铜缆连接器这里是差不多NVL36的体量 几乎一样
虽然nv swtich 的芯片减少了一个 但是内部做的overpass就是跟nvl72的640跟线一样 做满overpass 但是不向外拓展( 没有scable 没有额外的18个ospf口)
线材的用量等同于NVL72的sw tray的一半
NVL36的sw tray的线材用量 几乎等同于NVL72(我这么说你肯定觉得很晕 但是事实就是这样 2组overpass vs 1组overpass)
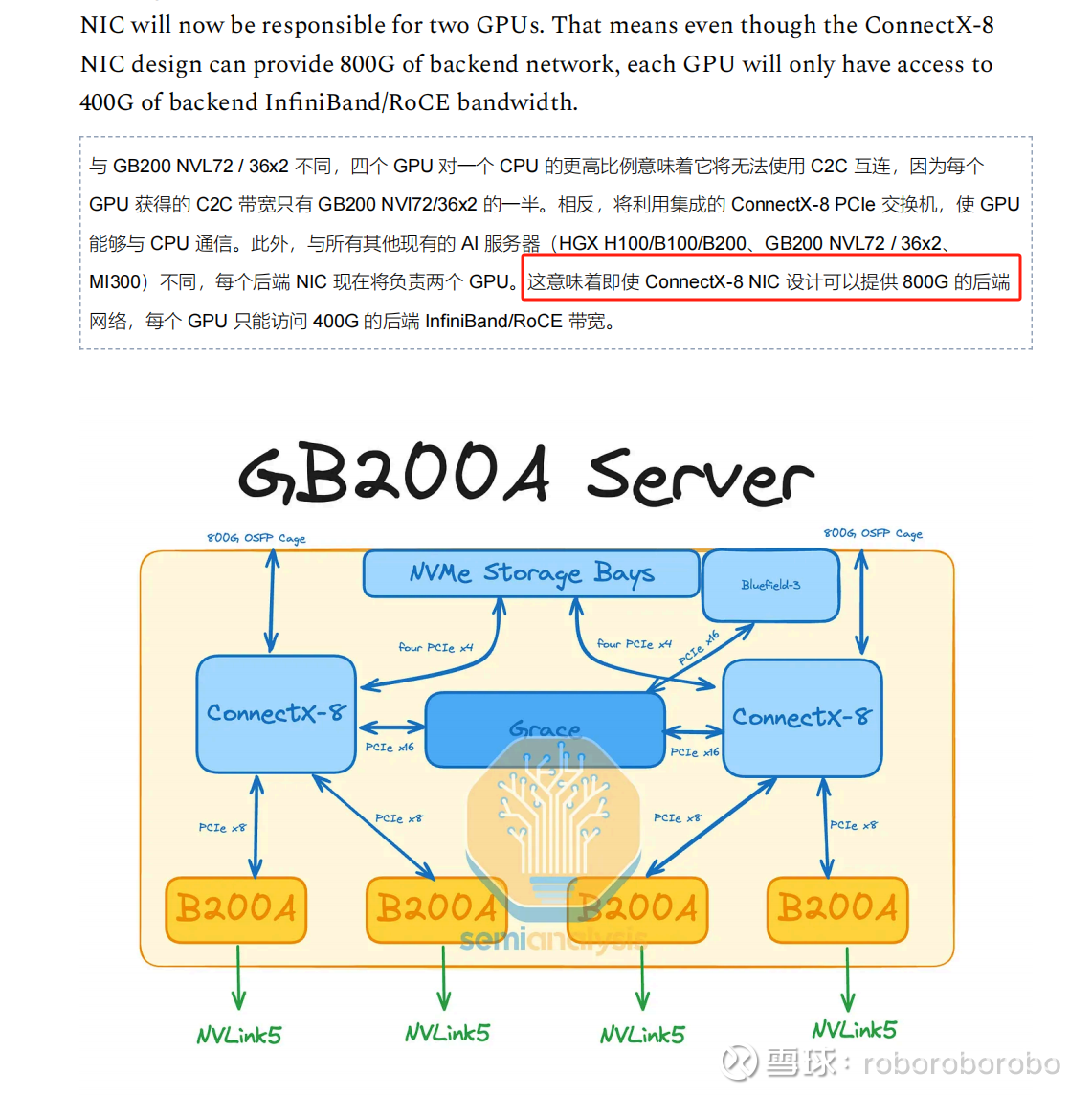
明年Q3还没有CX8我肯定不信 所以这点很容易理解 就是CX8网卡搭配800G光模块的Y型光模块 2个800G 另外一边是1.6T光模块 大大增加1.6T的光模块增量(光模块最简单就是看网卡用啥 用CX8就是强制1.6T)


解释了为什么NVL64被取消了 主要原因就是nv swtich tray 如果有4个nv swtich芯片会导致能耗过热问题(因为本身是风冷方案 不想能耗那么高 否则还不如直接上液冷)

最后SA上了传统艺能 就是强行分析MGX GB200A ultra NVL36呼之欲出(请记住 这是B200A ultra组成的 明年Q3才发售)的推出对目前供应链和预期销售的影响
对于明年Q3才发售的这个产品目前来看 算力密度大概率和价格都是NVL36的一半 这玩意非常像是nvl18 能抢占先发的nvl36和nvl72的份额这件事我感觉是不太可能的 但是有利于dell smic hp这类卖零散客户和小型企业的厂商
毕竟CSP和NSP吃了nvl36和nvl72的份额的大头 除非不用用途的需求特别旺盛
他们也不会非常愿意去用小企业跑推理才需要的降频版本的GB200A ultra NVL36(主要原因 我个人觉得这玩意的价格和算力密度x2以后和nvl36几乎没区别)

铜缆背板+铜缆的sw tray毫无疑问就是增加了 增加多少我有空算一下
这里写的就是柜内线 因为柜内线就是cartridge cable+switch tray的overpass这两部分组成(背板线+nvlink线)
请记住 这块是安费诺目前独供 并没有其他任何供应商 至少为期一年

这里主要代指是柜外线的1.6T ACC
我并不认可nvl36x2这个高性能机型会少卖 毕竟H1就出的产品 怎么能跟后期Q3出的产品比
csp拿到NVL36 还要去规划 土地 能耗 电力这些东西(这些指标和基建基本都是提前规划好的 大概率不会轻易去变动和匹配) 更改需要的时间人力成本都非常高 不会真的等到你Q3 拿个降频版本去取代(到了Q3才后知后觉没土地 没有能耗?) nvl36和72的主力公司 aws meta 微软都是以训练或者卖训练需求为主
而不是中小公司的推理和运行lamma3之类的模型需求为主
所以这个点并不认可 还有就是TE已经过1.6T acc认证 molex估计也快了 这安费诺虽然占了大头 但是友商在一年内有份额是没问题的(友商一供竟然是ltk乐庭 哈哈哈)


说实话每次SA分析到了光模块 结论都很迷 因为他们认为cx7网卡可以买400G 800G 但是nv以后全体就直接cx8 (cx8更贵 nv赚钱啊 又为什么要去看以前的老产品cx7)
实际上最简单的一点就是如果明年Q3用的就是CX8网卡 光模块的用量就是跟网卡匹配 不用总是意淫GPU速率是多少 CX8网卡既然是标配 光模块用800G和1.6T就是标配 这就完事了
这又不是我8卡服务器 我客户要省钱 我自己去采购网卡 极限操作就是H100 8卡 就搭配2张网卡去搭建 现在nv主打一个网络附加率(nv当然是卖800G和1.6T赚的更多) 强打强卖 网卡我都卖出去了 你不配光模块是啥意思?

这里SA的分析师认为延后半个Q对鸿海都有影响 有点为赋新词强说愁了 据我所知鸿海的排产没有任何变化 之后的MGX GB200A ultra NVL36大部分也是给他们做(今天一早问的)
本话题在雪球有224条讨论,点击查看。
雪球是一个投资者的社交网络,聪明的投资者都在这里。
点击下载雪球手机客户端 http://xueqiu.com/xz]]>
