
Published on August 2, 2024 10:06 AM GMT
We recently published a workshop paper at ICML 2024 which we want to summarize here briefly. Code for the paper can be found on GitHub. This work was done as part of the PIBBSS affiliateship. Thx to @Jayjay for comments on the draft.
TLDR: We analyze the probability distribution over token space in hidden LLM layers for a model that is instructed to lie and to tell the truth. We extract this probability distribution by applying the logit/tuned lens to the residual stream. We find large differences between lying and truth-telling in the entropy and KL-divergence of the predictive distribution and in the probability of the predicted token. The results suggest that the model converges to an answer faster (in earlier layers) when telling the truth. The predictive distribution has a sharper peak when telling the truth than when lying.
Introduction
Research from cognitive science suggests that lying is more cognitively demanding than truth-telling for humans. For example, lying increases response time and activates brain regions linked to executive function, supporting the cognitive load hypothesis. This hypothesis motivates us to explore if it is possible to find differences in information processing in LLMs when the model is instructed to lie or to tell the truth.
LLMs use the same computational resources (in terms of number of operations and memory usage) for each forward pass, which means that many cognitive signals used to detect lying in humans may not apply to LLMs. However, full access to the LLM's internal representations, might enable us to detect some useful internal signal to discriminate between lying and truth-telling.
By applying the logit lens to these internal representations, we can extract a transformer’s predictive distribution at each layer. We can then apply information-theoretic measures to the predictive distribution and see if we find differences in it's dynamics and shape when truth-telling versus lying.
We adopt the following (informal) definition for lying in LLMs from prior work to differentiate lies from statements that are incorrect due to model hallucinations or insufficient knowledge:
An incorrect model output is a lie if and only if the model is able to output the correct answer when instructed to tell the truth.
Method
We first choose a dataset with statements to be completed and apply an instruction (condition) to tell the truth/lie for each data sample. We then generate truthful/untruthful model completions for each data sample and filter data samples to only keep samples where the model generated a successful truthful and a successful false response.
Here is an example of this setup:

We then select the last input token, right before the truthful/untruthful completion. In the example above, this would be the is token just before Paris/Rome. For this token, we extract the internal residual stream representations for each layer.
The logit lens allows us to unembed the internal representations so we can explore the shape and the dynamics of the predictive distribution across the layers of the transformers by looking at the family .
Here is a figure for an intuition:
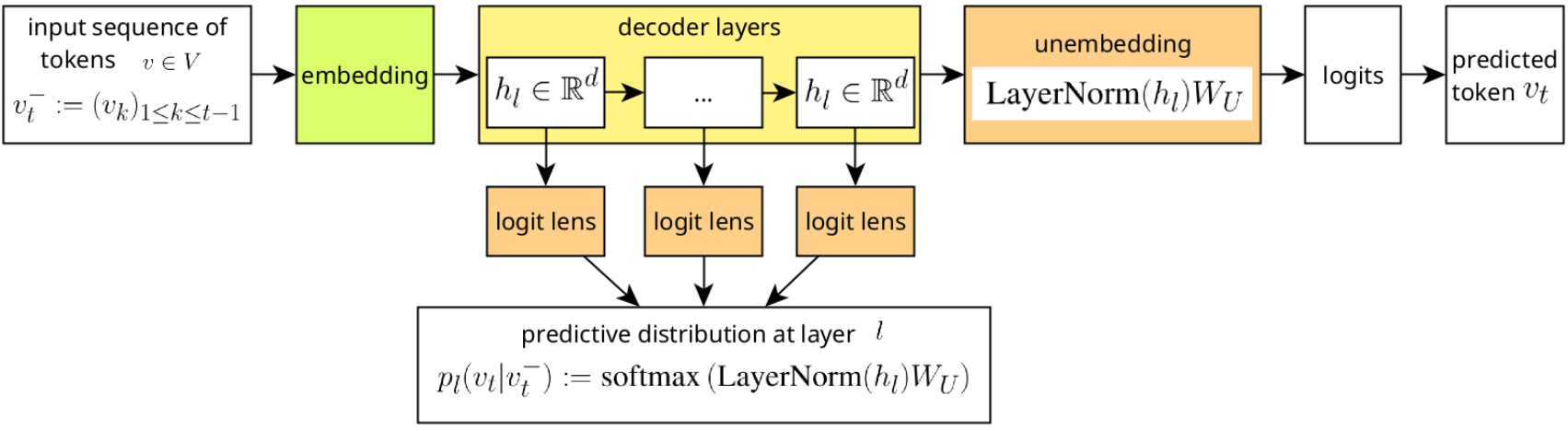
Given a sequence of tokens forming a condition (for example, an instruction to lie or tell the truth), and an input (for example an incomplete statement), the conditional entropy of some output at layer is:
The KL divergence between predictive distributions at layers and is:
In general we will consider , the output layer.
Results
We show our main results using the model zephyr-7b-beta and the dataset Statements1000. We show the medians and quartiles for the whole dataset.
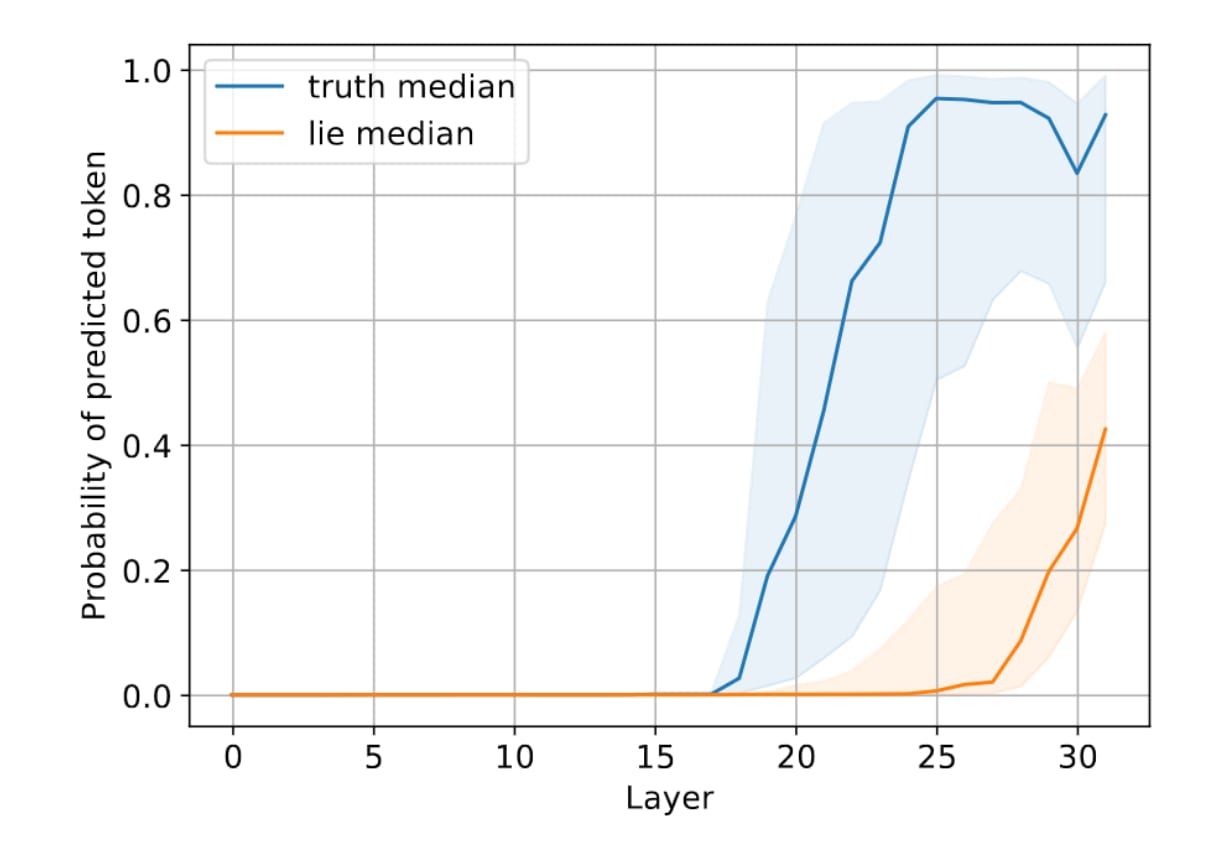
The probability of the predicted token increases earlier and is higher when telling the truth while it increases later and is not as high when lying. This indicates that the model converges faster to the predicted token and is more "certain" of the predicted token when telling the truth.
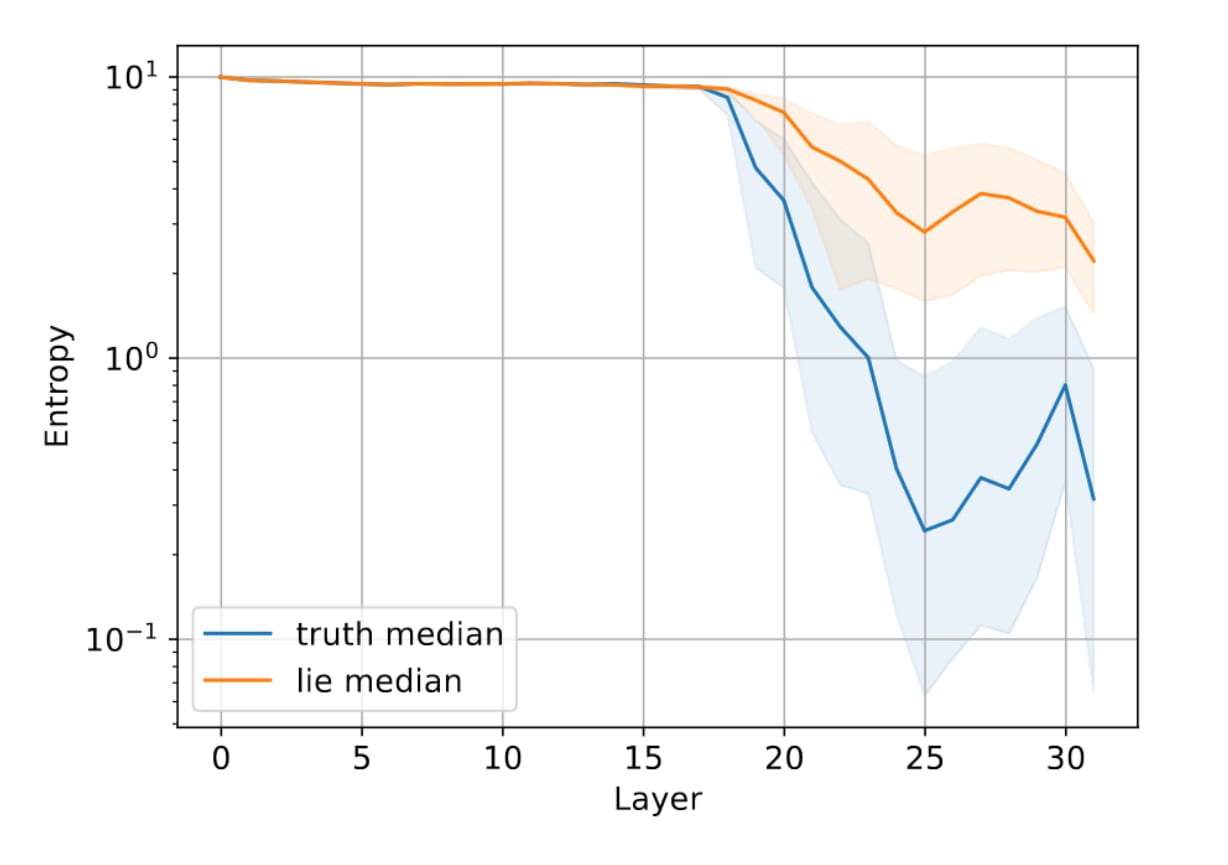
The Entropy is lower in mid to later layers when telling the truth. This means that the predictive distribution is more peaked when generating the truth and more spread out when generating a lie, which could be due to the fact that there are more possible false model completions than there are correct completions.
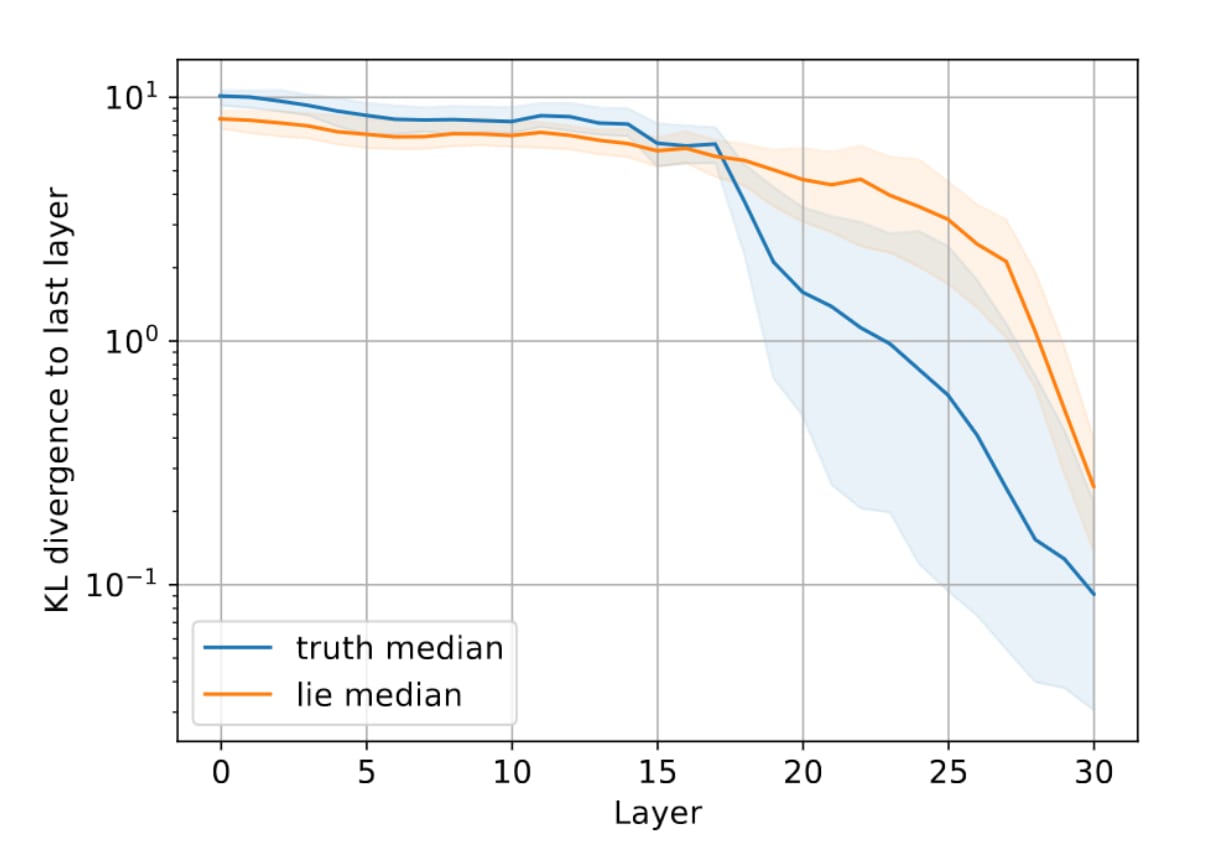
The KL divergence between intermediate layers and the last layer is higher at first but then drops earlier and faster when telling the truth, which means the model converges faster to the output distribution when telling the truth vs when lying.
Other experiments
Qualitatively, we find our results consistent when changing the model (we tested lama-7b-chat-hf and llama-13b-chat-hf), when substituting logit lens with tuned lens and when varying the instructions that induce lying or truth-telling. Checkout the paper for details on these experiments.
We observe an even more pronounced difference in the information theoretic measures when switching to the cities dataset, as shown in the graphs below.
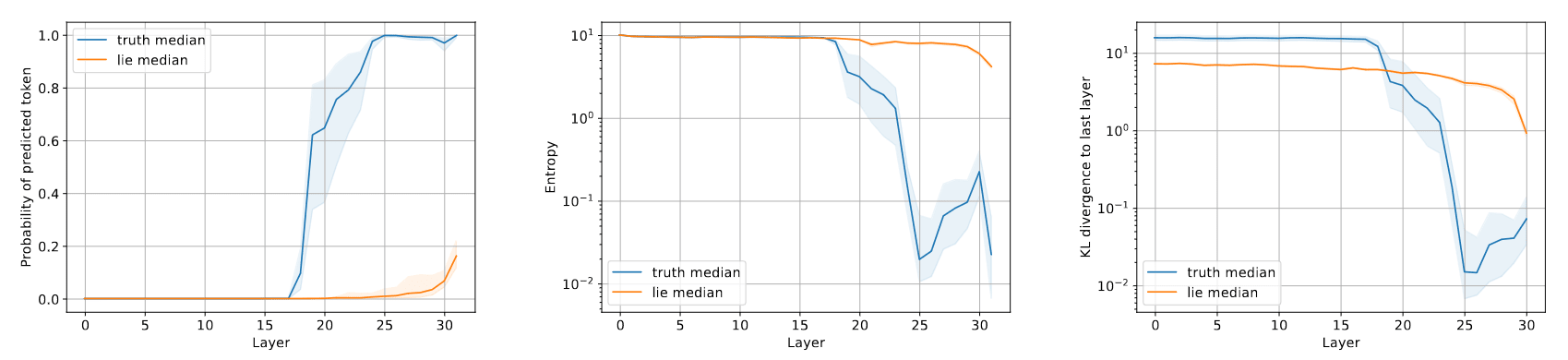
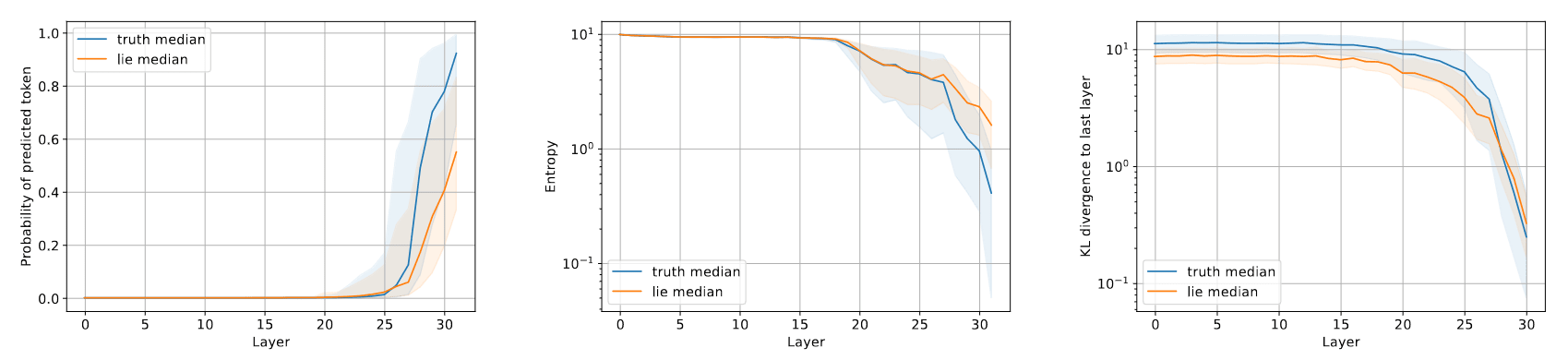
However we observe a much weaker difference on the FreebaseStatements dataset (adapted from FreebaseQA) as shown below. One possible explanation is, that the model is typically less certain about the truth in this context (the success rate when generating true statements is much lower compared to Statements1000 or cities).
Conclusion
Our information-theoretic measures suggest that the predictive distribution converges faster and looks more similar to the output distribution when the model is instructed to output the truth than when it is instructed to lie. Furthermore the predictive distribution is more spread out when the model is instructed to lie.
This evokes parallels to research in human cognition, which suggests that lying is typically less straightforward and more cognitively demanding than telling the truth.
Limitations
- Our results heavily rely on the assumption that we can extract meaningful probability distributions using the logit lens/tuned lens.Since our analysis is based on the predictive distributions over token space rather than the internal representations, our method is sensitive to different tokenizations even if the information content is the same (see XML setup in paper appendix), which is not desirable when aiming to detect lying.We do think most of the effect that we are observing comes from the fact that there are many more ways to lie than to tell the truth in this setup. It would be useful to look at binary choice scenarios .We only tested direct instructions to lie and not goal oriented or sycophantic lying.For our method to work we need the predicted token to be indicative of the truth/a lie. If the predicted token contains little information about the truth content of the completion the method is unlikely to work.
Our analysis is exploratory and relies on descriptive statistics and not hypothesis driven statistical testing.
Discuss
