


Large Language Models (LLMs) face deployment challenges due to latency issues caused by memory bandwidth constraints. Researchers use weight-only quantization to address this, compressing LLM parameters to lower precision. This approach improves latency and reduces GPU memory requirements. Implementing this effectively requires custom mixed-type matrix-multiply kernels that move, dequantize, and process weights efficiently. Existing kernels like bits and bytes, Marlin, and BitBLAS have shown significant speed-ups but are often limited to 4-bit quantization. Recent advancements in odd-bit and non-uniform quantization methods highlight the need for more flexible kernels that can support a wider range of settings to maximize the potential of weight quantization in LLM deployment.
Researchers have attempted to solve the LLM deployment challenges using weight-only quantization. Uniform quantization converts full-precision weights to lower-precision intervals, while non-uniform methods like lookup table (LUT) quantization offer more flexibility. Existing kernels like bits and bytes, Marlin, and BitBLAS move quantized weights from main memory to on-chip SRAM, performing matrix multiplications after de-quantizing to floating-point. These show significant speed-ups but often specialize in 4-bit uniform quantization, with LUT-quantization kernels underperforming. Non-uniform methods like SqueezeLLM and NormalFloat face trade-offs between lookup table size and quantization granularity. Also, non-uniformly quantized operations can’t utilize GPU accelerators optimized for floating-point calculations. This highlights the need for efficient kernels that can utilize quantized representations to minimize memory movement and GPU-native floating-point matrix multiplications, balancing the benefits of quantization with hardware optimization.
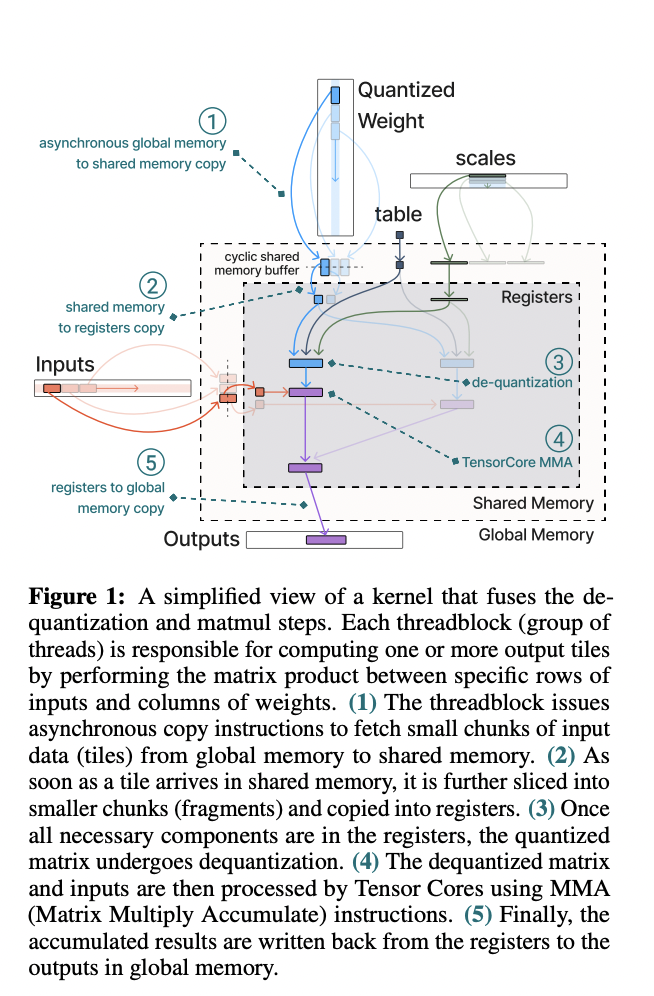
Researchers from Massachusetts Institute of Technology, High School of Mathematics Plovdiv and Carnegie Mellon University, MBZUAI, Petuum Inc. introduce an innovative approach that, flexible lookup-table engine (FLUTE) for deploying weight-quantized LLMs, focusing on low-bit and non-uniform quantization. It addresses three main challenges: handling sub-8-bit matrices, optimizing lookup table-based dequantization, and improving workload distribution for small batches and low-bit-width weights. FLUTE overcomes these issues through three key strategies: offline weight restructuring, a shared-memory lookup table for efficient dequantization, and Stream-K partitioning for optimized workload distribution. This approach enables FLUTE to effectively manage the complexities of low-bit and non-uniform quantization in LLM deployment, improving efficiency and performance in scenarios where traditional methods fall short.
FLUTE is an innovative approach for, flexible mixed-type matrix multiplications in weight-quantized LLMs. It addresses key challenges in deploying low-bit and non-uniform quantized models through three main strategies:
- Offline Matrix Restructuring: FLUTE reorders quantized weights to optimize for Tensor Core operations, handling non-standard bit widths (e.g., 3-bit) by splitting weights into bit-slices and combining them in registers.Vectorized Lookup in Shared Memory: To optimize dequantization, FLUTE uses a vectorized lookup table stored in shared memory, accessing two elements simultaneously. It also employs table duplication to reduce bank conflicts.Stream-K Workload Partitioning: FLUTE implements Stream-K decomposition to evenly distribute workload across SMs, mitigating wave quantization issues in low-bit and low-batch scenarios.
These innovations allow FLUTE to efficiently fuse dequantization and matrix multiplication operations, optimizing memory usage and computational throughput. The kernel employs a sophisticated pipeline of data movement between global memory, shared memory, and registers, utilizing GPU hardware capabilities for maximum performance in weight-quantized LLM deployments.
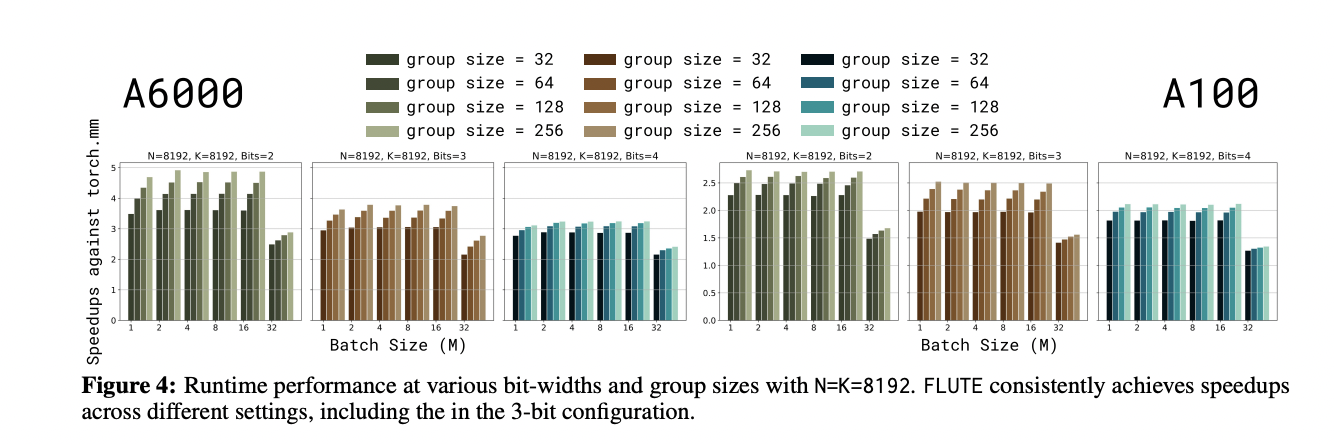
FLUTE shows impressive performance across various matrix shapes on both A6000 and A100 GPUs. On the A6000, it occasionally approaches the theoretical maximum speedup of 4x. This performance is also consistent across different batch sizes, unlike other LUT-compatible kernels which typically achieve similar speedups only at a batch size of 1 and then degrade rapidly as batch size increases. Also, FLUTE’s performance compares well even to Marlin, a kernel highly specialized for FP16 input and uniform-quantized INT4 weights. This demonstrates FLUTE’s ability to efficiently handle both uniform and non-uniform quantization schemes.
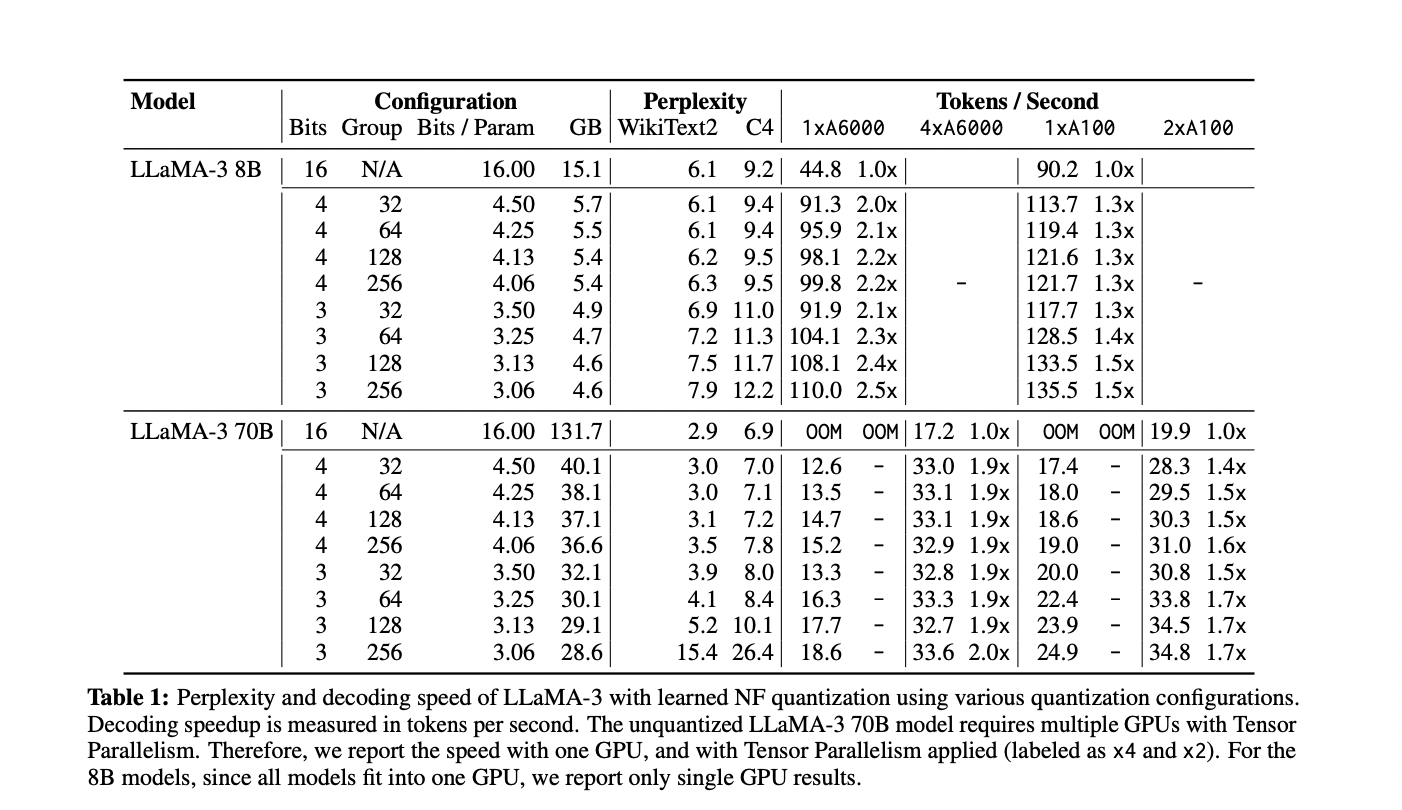
FLUTE demonstrates superior performance in LLM deployment across various quantization settings. The learned NF quantization approach outperforms standard methods and combines well with AWQ. FLUTE’s flexibility allows for experiments with different bit widths and group sizes, nearly matching 16-bit baseline perplexity with small group sizes. End-to-end latency tests using vLLM framework showed meaningful speedups across various configurations, including with Gemma-2 models. A group size of 64 was found to balance quality and speed effectively. Overall, FLUTE proves to be a versatile and efficient solution for quantized LLM deployment, offering improved performance across multiple scenarios.
FLUTE is a CUDA kernel designed to accelerate LLM inference through fused quantized matrix multiplications. It offers flexibility in mapping quantized to de-quantized values via lookup tables and supports various bit widths and group sizes. FLUTE’s performance is demonstrated through kernel-level benchmarks and end-to-end evaluations on state-of-the-art LLMs like LLaMA-3 and Gemma-2. Tested on A6000 and A100 GPUs in single and tensor parallel setups, FLUTE shows efficiency across unquantized, 3-bit, and 4-bit configurations. This versatility and performance make FLUTE a promising solution for accelerating LLM inference using advanced quantization techniques.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post FLUTE: A CUDA Kernel Designed for Fused Quantized Matrix Multiplications to Accelerate LLM Inference appeared first on MarkTechPost.
