


Large vision-language models (LVLMs) are very good at tasks that require visual understanding and language processing. However, they are always ready to provide answers, which makes them passive answer providers. LVLMs often give detailed and confident responses, even when the question is not clear or impossible to answer. For example, LLaVA, one of the best open-weight LVLMs, makes assumptions when faced with unclear or invalid questions, leading to biased and incorrect responses. This happens because LVLMs do not engage proactively, which should include questioning invalid questions, asking to clarify complex ones, and seeking more information when needed.
Multimodal pretraining has greatly improved vision-language tasks, with unified frameworks, handling various cross-modal and unimodal tasks. Currently, visual instruction tuning has become very important for developing general-purpose LVLMs, enhancing their ability to learn vision-language reasoning from zero-shot and few-shot textual instructions. Further research explores variations in visual instruction tuning, focusing on better text localization, OCR reading, object attribute relations, open-world knowledge, and efficiency. However, LVLMs can sometimes behave unpredictably. To address this issue, efforts like Llava-Guard have been developed to ensure safety compliance against toxic or violent content.
Researchers from the University of Illinois Urbana-Champaign, the University of Southern California, and the University of California, Los Angeles have proposed self-iMaginAtion for ContrAstive pReference OptimizatiON (MACAROON). It is used to improve the proactive conversation abilities of LVLMs. MACAROON works by instructing LVLMs to create pairs of contrasting responses based on task descriptions and human-defined criteria. This information is further used in conditional reinforcement learning, helping the models to distinguish between good and bad responses and standardizing the training data. Results of the proposed method show a positive change in the behaviors of LVLMs, providing a more dynamic and proactive engagement paradigm (0.84 AAR after MACAROON).
Creating a preference dataset with human annotations is costly, and hard to grow. In MACAROON, the same pipeline is adopted in PIE construction to produce 6 types of questions without labels, following the hierarchy described in this paper. MACAROON independently produces questions about hidden human preferences to make scaling easier. The proposed technique only needs human annotators to develop a detailed question description and define two sets of criteria specifying wanted and unwanted behaviors in LVLMs for each type of question. Then, self-imagination is applied to each specific question.
The results for PIE indicate that the current LVLM performs well in detecting Tier I questions, which are straightforward and easy to identify as invalid. However, it shows bad performance on Tier III questions, which are more challenging because existing LVLMs are primarily designed for single-turn responses without extensive interaction. MACAROON stands out with an AAR of 0.84, showing proactive engagement better than any other LVLMs. It also demonstrates strong performance in general vision-language tasks, ranking second in SEEDBench and AI2D and third in both perception and reasoning sections of MME.
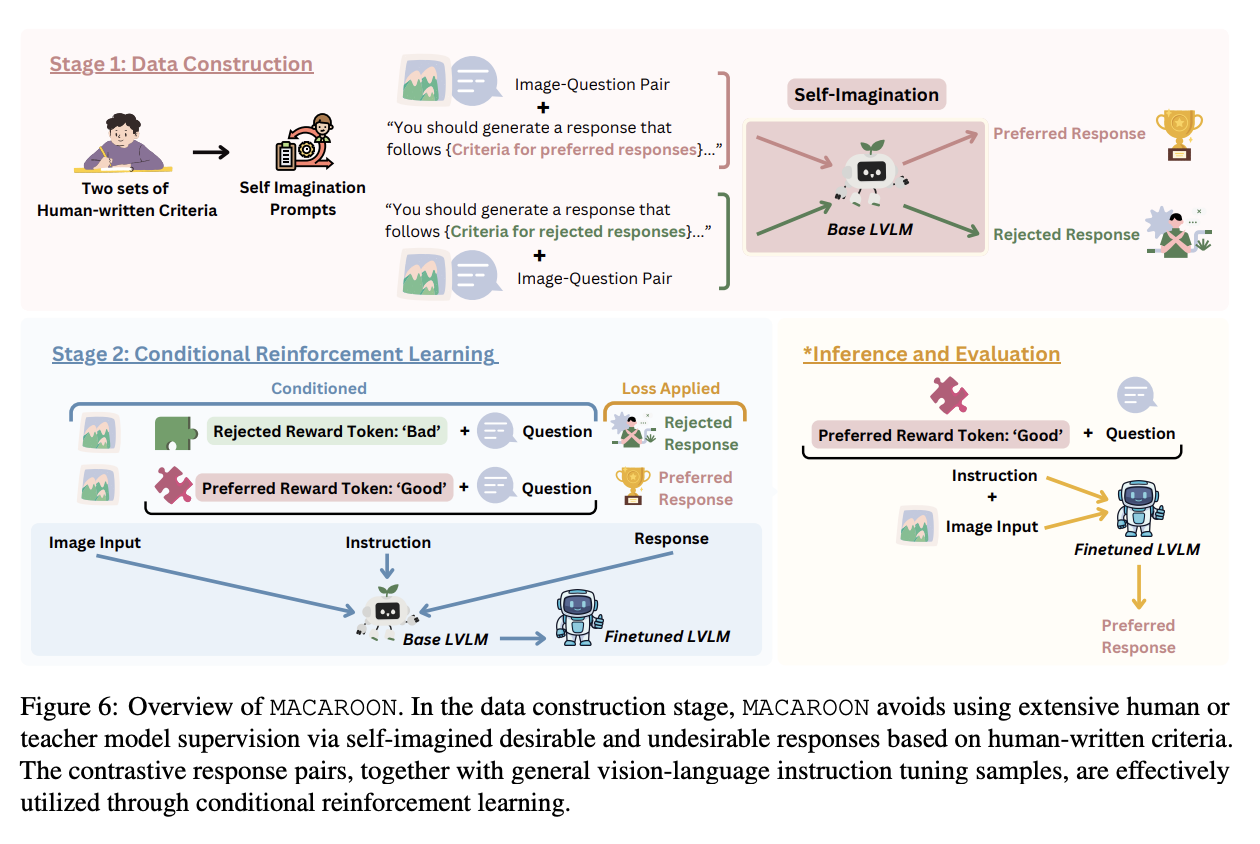
In conclusion, researchers have introduced MACAROON which integrated self-generated contrastive response pairs in a conditional reinforcement learning setting, enabling LVLMs to engage more effectively with humans. The main focus includes exploring the proactive engagement capabilities of LVLMs within the English language domain. However, the approach has limits: it relies on single images from a high-quality dataset for visual context. Future studies could explore AI that plans actions based on sequences of images over time (like videos), providing more depth for investigation.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post MACAROON: Enhancing the Proactive Conversation Abilities of Large Vision-Language Models LVLMs appeared first on MarkTechPost.
