


Large Vision-Language Models (LVLMs) have demonstrated impressive capabilities for capturing and reasoning over multimodal inputs and can process both images and text. While LVLM are impressive at understanding and describing visual content, they sometimes face challenges due to inconsistencies between their visual and language components. This happens due to the part that handles images and the part that processes language may have different stored information, leading to conflicts between their outputs. It has also been found that when asked a question about the same entity presented in two different modalities, the LVLM provides two contradictory answers. This cross-modality parametric knowledge conflict is detrimental as it hinders the performance of LVLM.
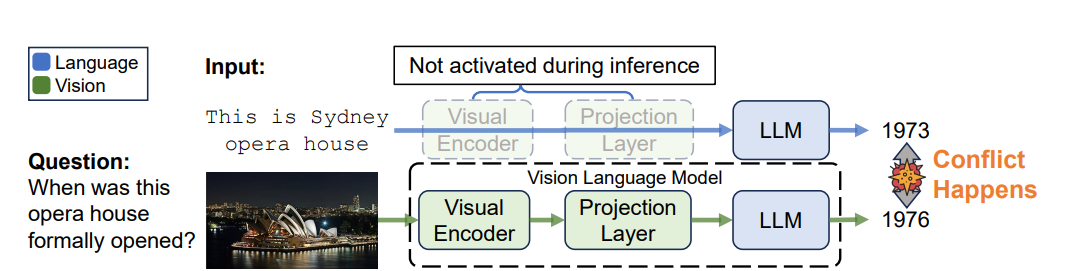
For Large Vision-Language Models (LVLMs), current methods have shown capabilities in interpreting multimodal inputs but they face challenges as cross-modality parametric knowledge creates conflicts. Existing research has primarily focused on optimizing individual model components but has not emphasized these conflicts. This paper is the first-of-its-kind work to define and study cross-modality parametric knowledge conflicts in LVLMs although it cites numerous studies and datasets that have contributed to understanding and addressing these issues.
A team of researchers from the University of California (Davis), Fadan University, the University of Southern California, and Texas A&M University developed a dynamic contrastive decoding (DCD) method to solve cross-modality parametric knowledge conflicts in Large Vision-Language Models (LVLMs). In this method, the idea of contrastive decoding is used, in which the unwanted predictions (logits) are taken away from the original predictions to lessen conflicts. The dynamic contrastive decoding (DCD) method changes this process by adding answer confidence as a factor to help adjust the predictions. This approach changes the way contrastive decoding works by including confidence as the key factor and helps to measure the differences in information between the text and the images more accurately. Since not all models provide the logits of the generated contents, the researchers also introduced two prompt-based(i.e. Reminder prompt, Answer prompt) improvement strategies for those models.
In terms of performance, the method has shown good results on datasets like ViQuAE and InfoSeek. In experiments, it improved accuracy by 2.36% on the ViQuAE dataset and 2.12% on the InfoSeek dataset when tested on the LLaVA-34B model.

In conclusion, this research paper introduced the concept of cross-modality parametric knowledge conflicts in LVLMs. It proposed a systematic approach to detect these conflicts, revealing a persistently high conflict rate across all model sizes. The findings indicate that simply scaling up models does not resolve these conflicts, highlighting the need for targeted intervention strategies. The dynamic contrastive decoding (DCD), selectively removes unreliable logits to improve answer accuracy. For models without access to logits, the two prompt-based strategies (i.e. Reminder prompt, Answer prompt) gave results depending on the size of the model, thus concluding that the large models have more ability to understand and grasp the knowledge provided to them. In the future, this method can be used in multimodal data to increase their accuracy and optimize their output.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Data Retrieval Conference (Promoted)
The post Dynamic Contrastive Decoding (DCD): A New AI Approach that Selectively Removes Unreliable Logits to Improve Answer Accuracy in Large Vision-Language Models appeared first on MarkTechPost.
