
Published on August 13, 2025 7:21 AM GMT
Or the snappier[1] title from my email inbox: "Meta's mind-reading movie AI"
Paper: TRIBE: TRImodal Brain Encoder for whole-brain fMRI response prediction (arXiv:2507.22229)
Summary
- Meta's Brain & AI Research team[2] won first place at Algonauts 2025 with TRIBE, a deep neural network trained to predict brain responses to stimuli across multiple modalities (text, audio, video), cortical areas (superior temporal lobe, ventral, and dorsal visual cortices), and individuals (four people).The model is the first brain encoding pipeline which is simultaneously non-linear, multi-subject, and multi-modal.The team show that these features improve model performance (exemplified by their win!) and provide extra insights, including improved neuroanatomical understandings.Specifically, the model predicts blood-oxygen-level-dependent (BOLD) signals (a proxy for neural activity) in the brains of human participants exposed to video content: Friends, The Bourne Supremacy, Hidden Figures, The Wolf of Wall Street and Life (a BBC Nature documentary).
Epistemic Status
I provide a summary with key points from the paper alongside my takeaways, keeping things light and engaging!
I'm a data scientist with a deep interest in AI alignment and neuroscience but not a neuroscientist. I have moderate confidence in my statements but errors are possible.
I spent 2-3 hours deeply reading the paper, performing supplementary research, and drafting notes. I spent 4 hours writing up notes.
Review
(1) Review preamble
A few days ago I published a [long] piece on why we might model superintelligence as third-order cognition — and the implications this would have for AI alignment.
Part of my post talks about appreciating Meta as a key-player in this world model, particularly due to their focus on highly individualised superintelligent AI.
I state that we can model "humans with superintelligence" as third-order cognition beings, one crucial property of which being lower order irreconcilability.[3]
I propose that a sufficient way to measure this happening is with "hierarchical predictive advantage: higher-order cognition shows, at a statistically significant level, accurate prediction of lower-order interactions that cannot be matched at the lower-order level."
Accordingly, I was very excited to see both of these ideas captured by an article in my email inbox suggesting "Meta’s AI predicts brain responses to videos"!
This post is my review of that paper, and key takeaways.
(2) Abstract
From the paper:
Here, we introduce TRIBE, the first deep neural network trained to predict brain responses to stimuli across multiple modalities, cortical areas and individuals. By combining the pretrained representations of text, audio and video foundational models and handling their time-evolving nature with a transformer, our model can precisely model the spatial and temporal fMRI responses to videos, achieving the first place in the Algonauts 2025 brain encoding competition with a significant margin over competitors. Ablations show that while unimodal models can reliably predict their corresponding cortical networks (e.g. visual or auditory networks), they are systematically outperformed by our multimodal model in high-level associative cortices. Currently applied to perception and comprehension, our approach paves the way towards building an integrative model of representations in the human brain.
The main takeaway here is that, as described by their naming, the TRIBE deep neural network is integrating data across text, audio, and video modalities. This gives a systematic advantage over unimodal models.[4]
(3) Motivation
The team state their motivation:
Progress in neuroscience has historically derived from an increasing specialization into cognitive tasks and brain areas … While this divide-and-conquer approach has undeniably yielded deep insights into the brain’s mechanisms of cognition, it has led to a fragmented scientific landscape: How neuronal assemblies together construct and globally broadcast a unified representation of the perceived world remains limited to coarse conceptual models.
So the overall idea is to deploy a model that is more complex (0.9B trainable parameters)[5] across richer inputs (text, audio, and video). I pattern-match this as a scaling hypothesis applied to cognitive neuroscience research.
The paper goes on to introduce the idea that:
[representations of] image, audio and video … have been shown to – at least partially – align with those of the brain ...
And so:
... several teams have built encoding models to predict brain responses to natural stimuli from the activations of neural networks in response to images.
The paper states three limitations of existing encoding models: 1) linearity, 2) subject-specificity, and 3) uni-modality — which are all implementation challenges in successfully fitting a model to brain function.[6]
(4) Contribution
In contrast to these, introducing TRIBE:
TRIBE: a novel deep learning pipeline to predict the fMRI brain responses of participants watching videos from the corresponding images, audio and transcript. This approach addresses the three limitations outlined above: our model learns how to capture the dynamical integration of modalities in an end-to-end manner across the whole brain, and from multiple subjects. Our model achieves state-of-the-art results, reaching the first place out of 263 teams in the Algonauts 2025 competition on multimodal brain encoding. We demonstrate with ablation analyses the importance of the multimodal, multisubject and nonlinear nature of TRIBE. Finally, we observe that the benefit of multimodality is highest in associative cortices.
A line that stood out to me here was:
We observe that the benefit of multimodality is highest in associative cortices.
This makes intuitive sense — primary sensory cortices, e.g touch, through their simplicity are highly optimised to not require many cross-modal inputs.
In comparison, associative cortices integrate distinct first-order signals — and as a result can be better modelled by a deep neural network (i.e TRIBE) that is itself drawing from distinct modal signals (vs. one that is uni-modal).
Can we extend this understanding to the way that superintelligence might integrate with human intelligence?
One logical parallel would be to state that a human-superintelligence ("human-SI") binding will have strengthened predictive power over states within its own bounded frame by advancing the scope and depth of superintelligent integration of lower-order subsystems — i.e. human metacognition and lower-order (non-metarepresentational) cognition.
Indeed, if we extend further to suppose bidirectional integration with these systems, we might expect predictive power to increase accordingly.
(5) Related work
Back to the paper:
For "related work" they state:
While there has been recent research on deep learning for multimodal brain decoding, there currently exists no equivalent for brain encoding.
It was at this point in the paper that I realised "decoding" is the fun part! That's the actual "mind reading".
Although more precisely: the combination of these is how we get to "AI can read your thoughts". It predicts the encoding and then has the interpretability skill to decode it.
The team link out to this related work — the paper "Reconstructing the Mind’s Eye: fMRI-to-Image with Contrastive Learning and Diffusion Priors" is phenomenal.
I'm very happy to be able to highlight it now — I actually remember seeing this paper around the time it came out and having my mind blown.
Possibly the most insane figure I’ve seen in an academic paper:

And if that wasn't enough:

It’s poignant that they gave the brain googley eyes and that’s not even the most insane part of the image.
The TRIBE paper calls out that there have been efforts to model brain encoding using vision-language transformers (vs. their deep learning approach), but that these are insufficient since:
The way these models integrate information across modalities may be very different from how the human brain does such multimodal integration. An ideal encoding pipeline should thus learn how to best combine different modalities.
(6) Methodology
Next, the paper goes into their methodology.
The experiment is operationalised by performing a regression on "blood-oxygen-level-dependent (BOLD) signals" in the brain, which act as an indirect proxy for neural activity, the thinking[7] being:
- Local neural signal firing → metabolic demand → vascular response → changes in blood oxygenation (and some changes to flow and volume) → fMRI signal change
To do this, the team:
Take as input the video clip being viewed by the participant, as well as the corresponding audio file and transcript. From these, we extract high-dimensional embeddings from the intermediate layers of start-of-the art generative AI models along three modalities of interest: text, audio and video, which we feed to our deep encoding model.
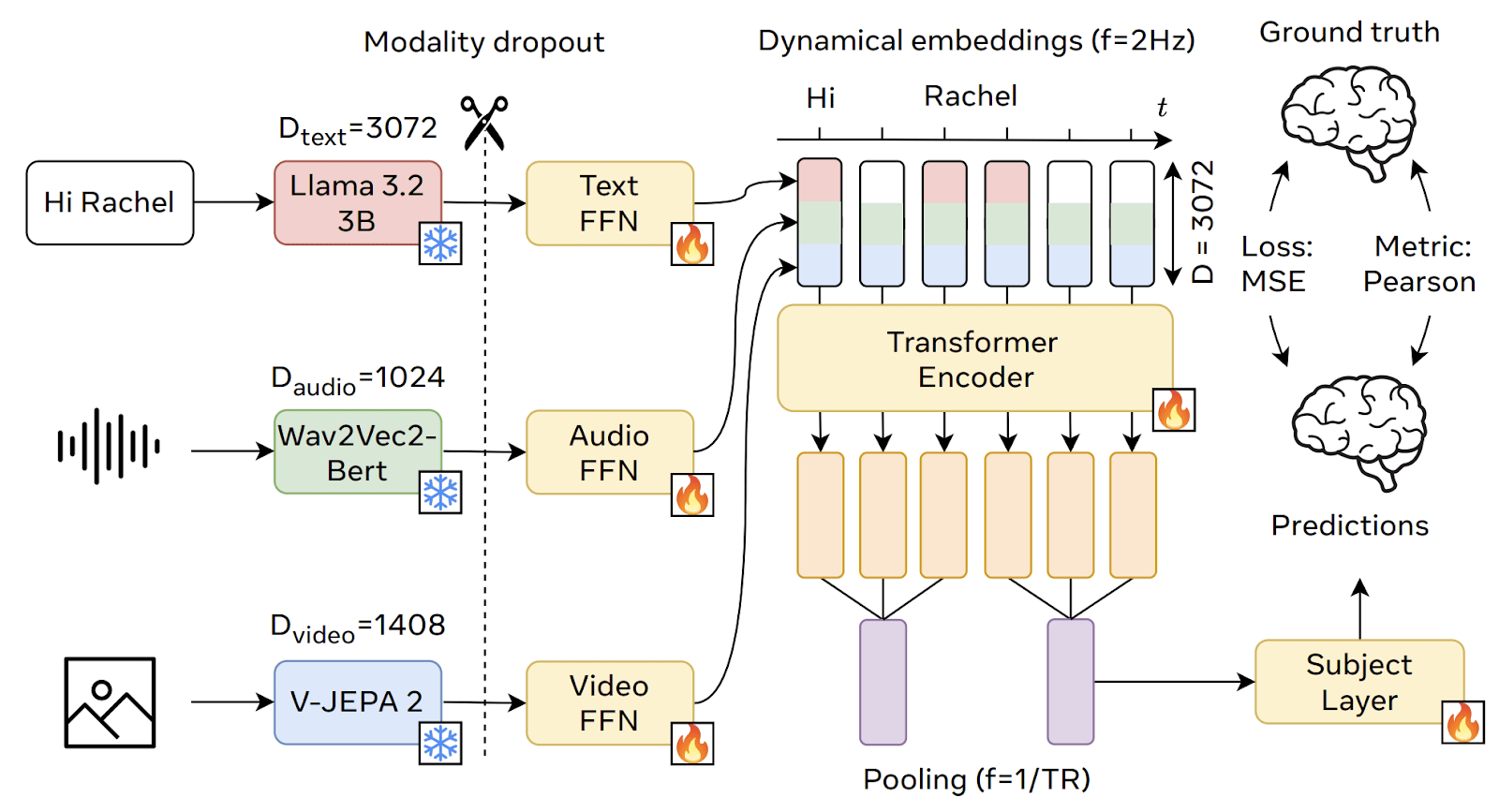
Note: dynamic embeddings are fed through a transformer — this is what makes the model "nonlinear".
Hilariously, the encoding model is pre-trained based on 6 humans (three women, three men) watching six seasons of Friends, plus some movies.
I’m surprised any brain signals were firing during the seasons of Friends.[8]
We train our encoding model on the Courtois NeuroMod dataset. This dataset consists of six human participants who watched the same naturalistic videos, namely the first six seasons of the popular TV series Friends as well as four movies: The Bourne Supremacy, Hidden Figures, The Wolf of Wall Street and Life (a BBC Nature documentary). This amounts to an unprecedently large recording volume of over 80 hours of fMRI per subject. In the present work, we focus on a subset of four subjects curated for the Algonauts 2025 competition.
I wonder how this body of work was chosen to capture the responses of the human mind?
A confession: in my mind, when I was imagining the setup of this competition, I naively thought this might be happening live — i.e brain fMRIs were being recorded and in parallel teams were training their models and working to build streaming predictions of brain waves. The actual implementation — all teams had access to a big set of fMRI data, and then tried to create a model that would show similar data given the same inputs (minus a human biological brain) — makes more sense.
Anyway, in the paper we see the deep learning model encoding similar brain responses to the actual measured response (Pearson correlation coefficients in the range 0.77 - 0.85):
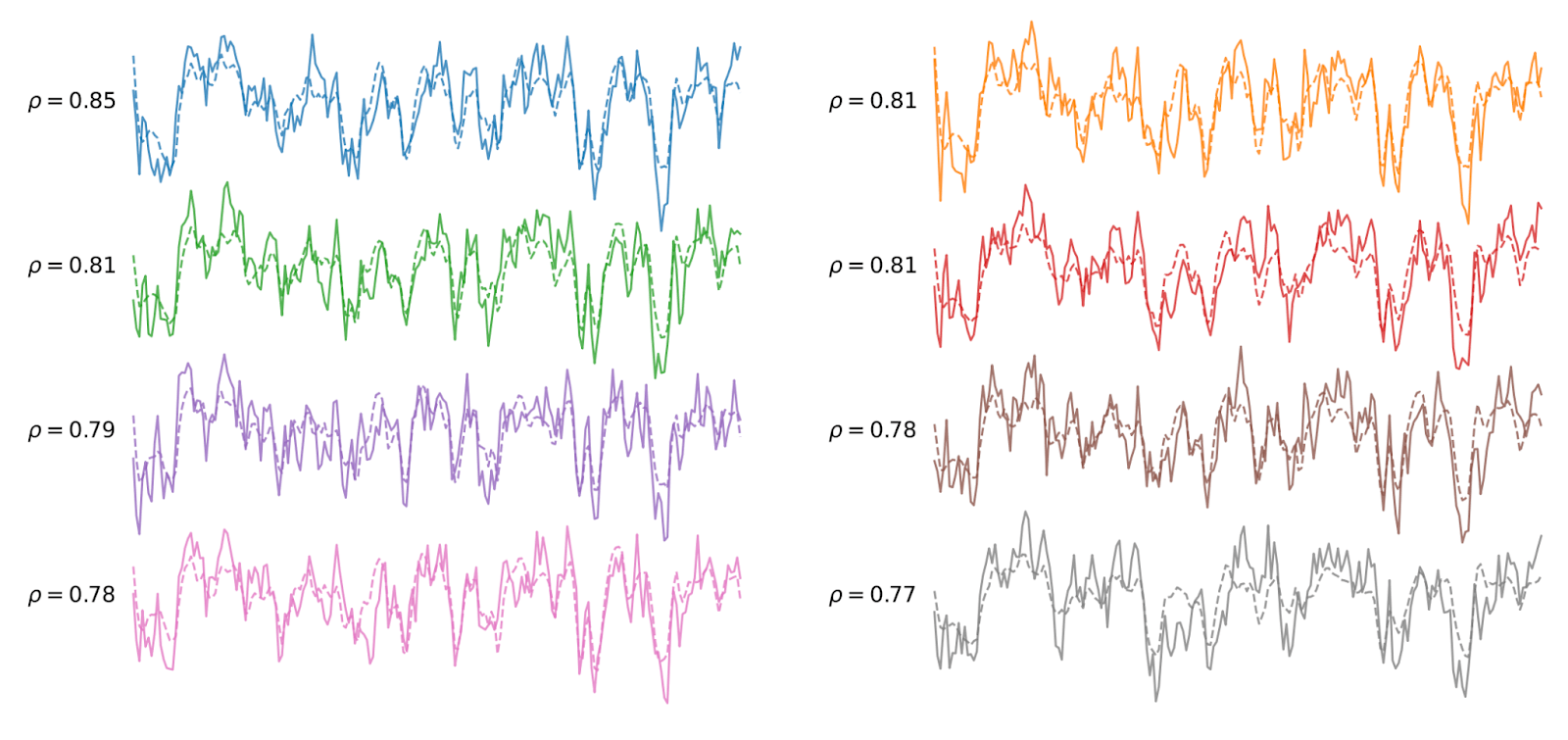
Visually it looks like a pretty impressive correlation. Note that we can describe this as "strong positive co-movement", but it falls short of mind-reading:
- The Pearson correlation coefficient ρ being approximately 0.8 gives a shared variance of ρ² = 0.64, suggesting that the model explains approximately 64% of the variance while 36% remains unexplained.The model isn't directly predicting the neural signal — it's approximately predicting the BOLD signal which itself is a proxy of the neural signal.Even with the neural signal prediction, the model is not architected to decode the encoding, to be able to infer what is actually being thought.
Expanding on the "hierarchical predictive advantage" theoretically exhibited by superintelligence that I talked about in my preamble: this should look like the AI encoding and then decoding thoughts with >95% accuracy — before the thought arises from (human) second-order cognition.
The model building phase of Algonauts ran from January 6th to July 6th — 6 months.
Put another way, with the current methodology the lag from “human having thought” (captured by fMRI) to "deep learning model encoding a similar thought" is currently on the order of months. The encoding also only captures "strong positive comovement".
I will be very interested to see how model effectiveness evolves over time, specifically: 1) reducing lag time, 2) improving correlation, 3) establishing and optimising a highly performant decoding layer to interpret encodings.
Importantly in the absence of decoding: we don’t know what associative cortex representations the deep learning model is encoding — I would speculate that it is capturing the most simplistic features of the source data, i.e auditory response corresponding to volume vs. deep thoughts about the meaning of the sounds.
(7) Results
Without a deep comprehension of how much variance is occurring with the encoding model, I found it interesting to note that while TRIBE finished first in the Algonauts competition, it was outperformed by SDA and MedARC for subject 5:
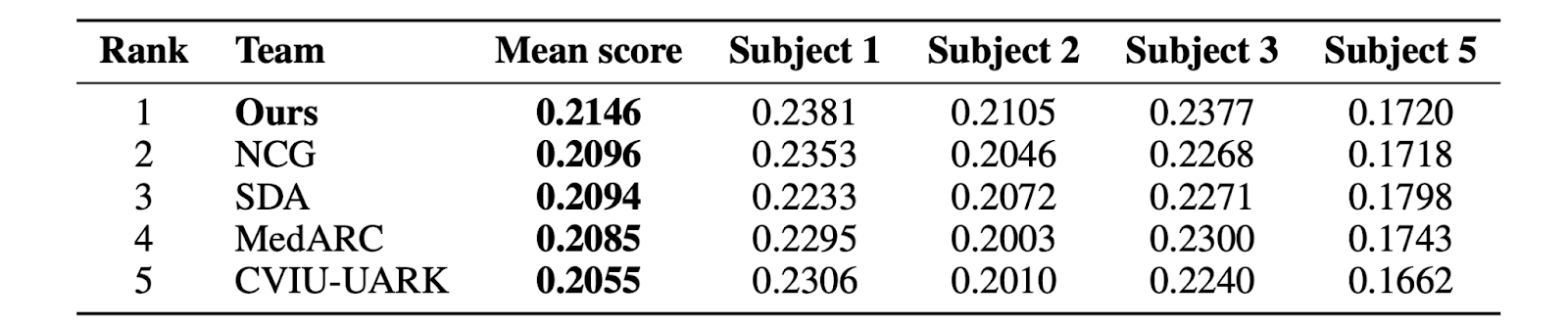
For brain encoding model outputs to be tightly attributable to multi-modal model capability, I would’ve expected performance to be pretty uniform across subjects (i.e for first place to outperform other models across all subjects).
The team show how the model generalises across movies outside of the training distribution. From just training on Friends, they are able to generalise and achieve a mean correlation score of 0.1886 on a very different type of audiovisual experience: watching Planet Earth.
0.1886 might sound a bit low,[9] so the team follows brain encoding research best practice to upweight their correlation score based on noise in the data. Specifically, noise arises from the fact that measurement happens across 1,000 experiential "parcels" of a subject watching a TV or movie — but many of these parcels simply add noise to the correlation measurement because they lack anything interesting happening.[10]
After upweighting, they state a stronger normalized Pearson correlation of the overall model of 0.54 ± 0.1.
The team provide great insight into the performance benefits of adding additional modalities:
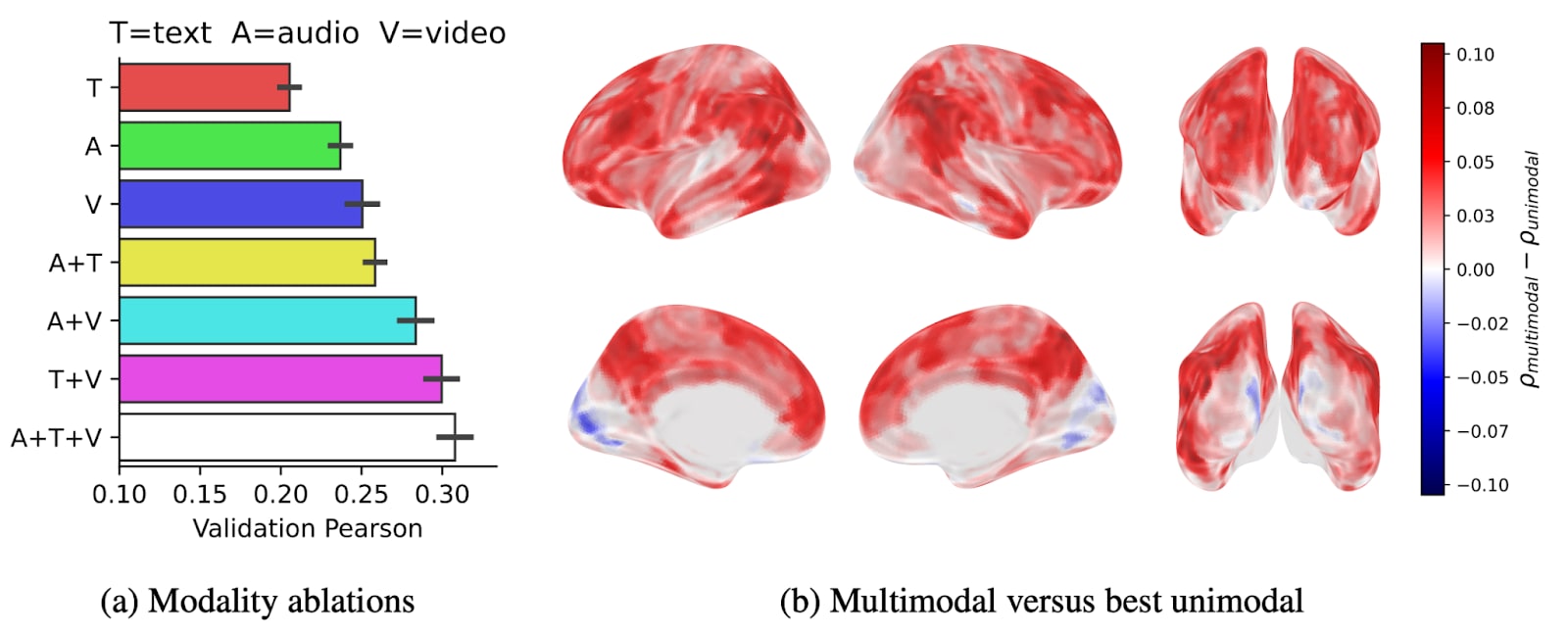
Breaking this down across modalities by parts of the brain, they find:
We observe that the multimodal encoder consistently outperforms the unimodal models, especially in associative areas such as the prefrontal or parieto-occipito-temporal cortices (up to 30% increase in encoding score). Interestingly, the multimodal model performs less well than the vision-only model in the primary visual cortex, which is highly specific to visual features.
— which is interesting!
What might be happening differently in the primary visual cortex, vs. other parts of the brain?
The team state later on that the design of the competition required smoothing out the spatial data, i.e worsening visual resolution, which seems to be the cause. It seems likely though that there are other mechanistic differences between cortices.
We observe interesting bimodal associations in some key areas: in particular, text+audio (yellow) in can be observed in the superior temporal lobe and video+audio (cyan) can be observed in the ventral and dorsal visual cortices.
The team, for fun, uses the model to explore interplay between modalities by iteratively masking each modality. In doing so they derive existing neuroanatomical understandings but using a novel approach — ablations of a tri-modal deep learning model. This is cool!
Lastly, the ambition of the team in their vision of extending the model makes interesting reading!
Broader impact: Building a model able to accurately predict human brain responses to complex and naturalistic conditions is an important endeavour for neuroscience. Not only does this approach open the possibility of exploring cognitive abilities (e.g. theory of mind, humour)[11] that are challenging to isolate with minimalist designs, but they will eventually be necessary to evaluate increasingly complex models of cognition and intelligence. In addition, our approach forges a path to (1) integrate the different sub-fields of neuroscience into a single framework and to (2) develop in silico experimentation, where in vivo experiments could be complemented and guided by the predictions of a brain encoder.
Can we use AI to engineer the funniest joke of all time? Maybe then we can finally say it was all worth it.
- ^
Snappier yet demonstrably false.
- ^
Exact org structure is unclear — this used to be Meta Fundamental AI Research (FAIR), but seems there have been some reorgs. I did some LinkedIn stalking and this seems to be the working name... in any case the team is mostly a bunch of cracked AI researchers in Paris.
- ^
Defined as third-order cognition (here, the superintelligence) being wholly irreconcilable at second- and first- order levels of cognition (e.g human metacognition).
- ^
Unimodal models = models only trained on one mode (e.g audio).
- ^
There are also billions of parameters in the frozen backbone stack:
Text model Llama-3.2-3B (3B parameters)
Audio model Wav2Vec-Bert-2.0 (580M parameters)
Video model V-JEPA-2-Gigantic-256 (1B parameters) - ^
They are also quite densely defined.
- ^
Get it?
- ^
Just kidding.
- ^
I think it's actually very impressive!
- ^
Again if this disturbs results, not sure how they got results from Friends.
- ^
Bolded by me.
Discuss
