

几个月前,爱范儿在一台 M3 Ultra 的 Mac Studio 成功部署了 671B 的 DeepSeek 的本地大模型(4-bit 量化版)。相比传统 GPU 方案需要复杂的内存管理和数据交换,苹果 512GB 的统一内存可以直接将整个模型加载到内存中,避免了频繁的数据搬运。
而如果把 4 台顶配 M3 Ultra 的 Mac Studio,通过开源工具串联成一个「桌面级 AI 集群」,是否就能把本地推理的天花板再抬高一个维度?
这正是来自英国创业公司 Exo Labs 正在尝试解决的问题。
「不要以为牛津大学 GPU 多得用不完」
你可能会以为像牛津这样的顶级大学肯定 GPU 多得用不完,但其实完全不是这样。
Exo Labs 创始人 Alex 和 Seth 毕业于牛津大学。即使在这样的顶尖高校做研究,想要使用 GPU 集群也需要提前数月排队,一次只能申请一张卡,流程漫长而低效。
他们意识到,当前 AI 基础设施的高度集中化,使得个人研究者和小型团队被边缘化。
去年 7 月,他们启动了第一次实验,用两台 MacBook Pro 成功串联跑通了 LLaMA 模型。虽然性能有限,每秒只能输出 3 个 token,但已经足以验证 Apple Silicon 架构用于 AI 分布式推理的可行性。

真正的转折点来自 M3 Ultra Mac Studio 的发布。512GB 统一内存、819GB/s 的内存带宽、80 核 GPU,再加上 Thunderbolt 5 的 80Gbps 双向传输能力——这些规格让本地 AI 集群从理想变成了现实。
同时跑两个 670 亿参数大模型是什么体验?
4 台顶配 M3 Ultra 的 Mac Studio 通过 Thunderbolt 5 串联后,账面数据相当惊人:
- 128 核 CPU(32×4)240 个 GPU 核心(80×4)2TB 统一内存(512GB×4)总内存带宽超过 3TB/s
这样的组合,几乎是一台家用级别的小型超算。但硬件只是基础,真正发挥效能的关键是 EXO Labs 开发的分布式模型调度平台 Exo。Exo 会根据内存与带宽状态将模型自动拆分,部署在最合适的节点上。
在现场,Exo 展示了以下核心能力:
- 大模型加载:8-bit 量化后的 DeepSeek 完整载入需要 700GB 以上内存,单台 Mac Studio 无力承担。Exo 会将模型拆分部署到 2 台 Mac Studio 上完成加载。激活后,它的「打字速度」基本上超过了人的阅读速度。
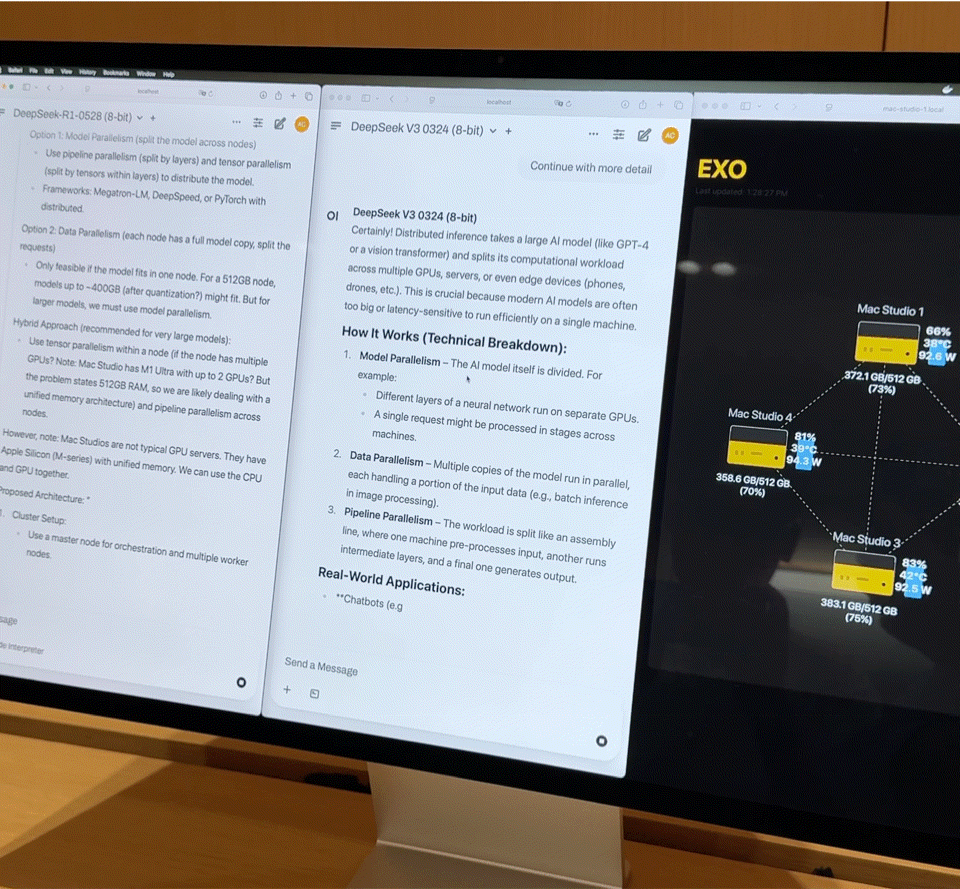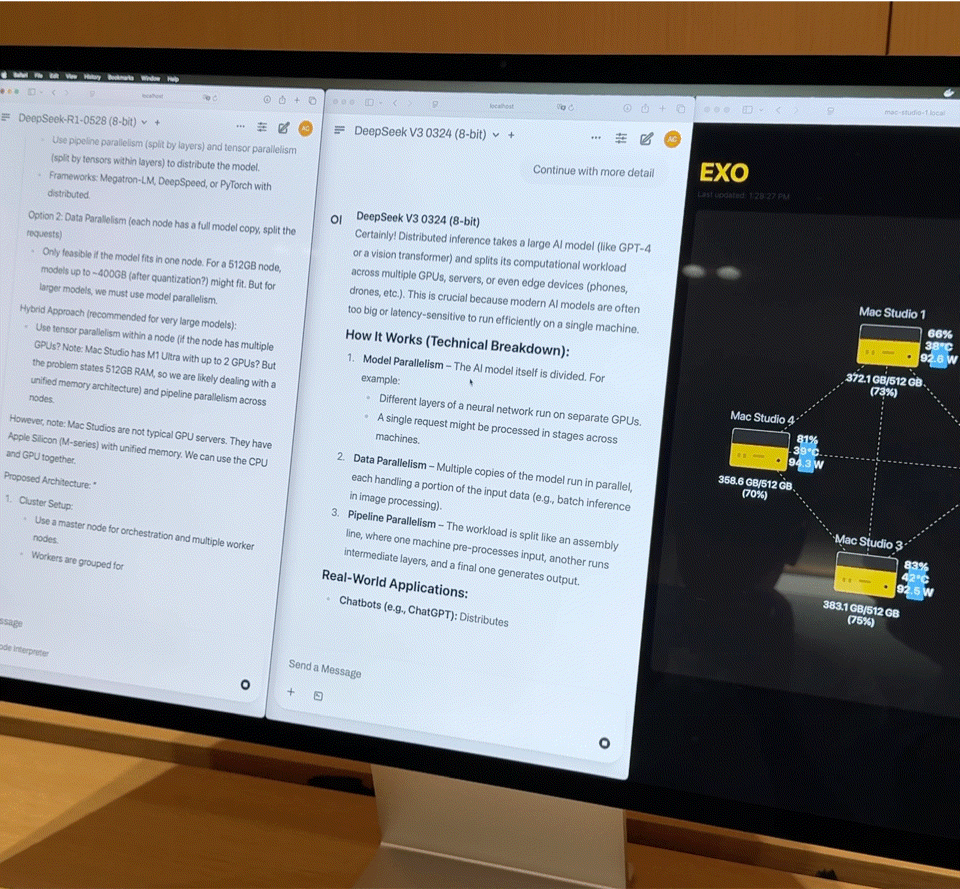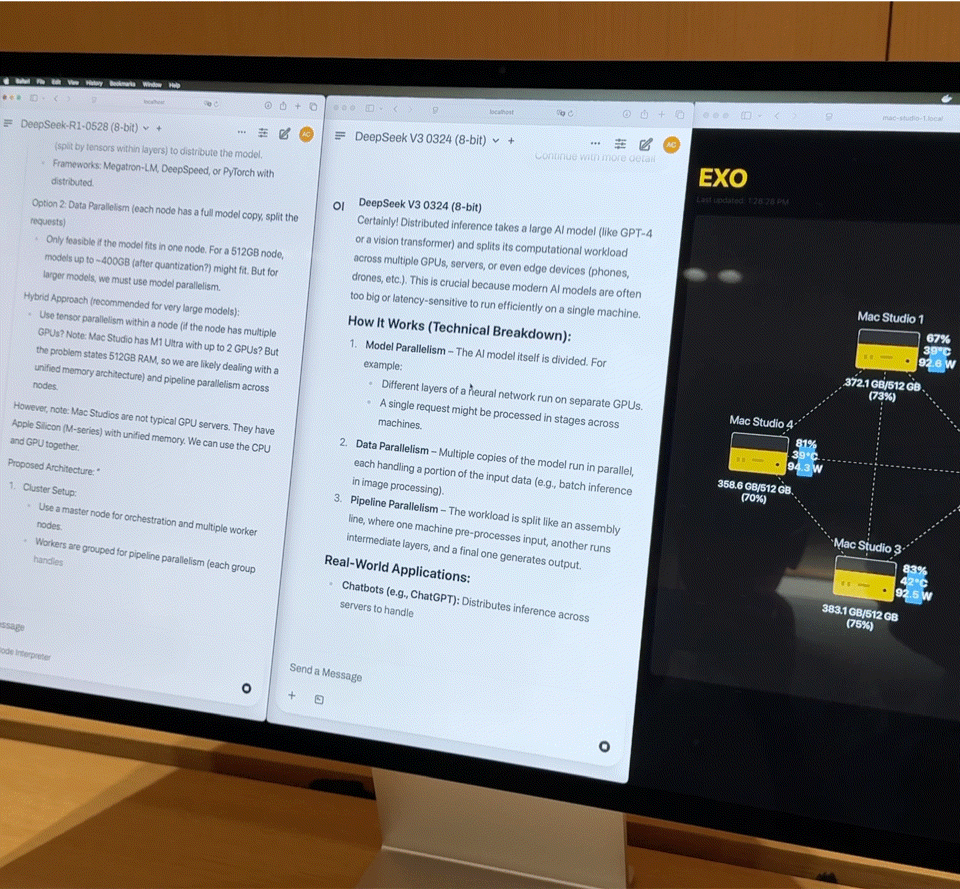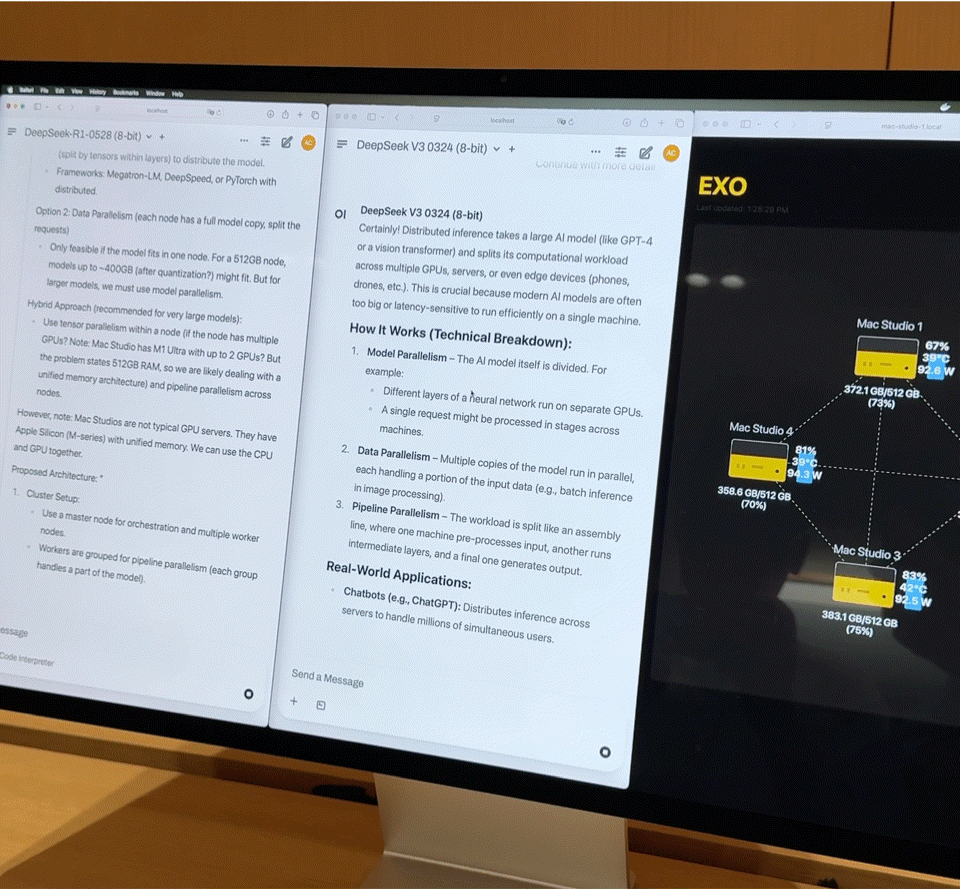
- 并行推理:在运行 DeepSeek V3 的基础上,又加载了同样 670 亿参数的 DeepSeek R1。系统立即将 R1 分配到剩余的两台设备上,实现两个大模型并行推理,支持多用户同时提问。文档私有问答:拖入公司财报 PDF,模型在本地完成知识嵌入与问答,不依赖任何云端资源,数据完全私有可控。轻量微调:若企业有数千份内部资料,可通过 QLoRA + LoRA 技术进行本地微调。单台微调需耗时数日,而通过 Exo 的集群调度能力,训练任务可线性加速,大幅缩短时间成本。
巨大的成本差异
我们在现场后台观察拓扑图发现:即使 4 台机器同时处于高负载状态,整套系统功耗始终控制在 400W 以内,运行几乎无风扇噪音。
要在传统服务器方案中实现同等性能,至少需要部署 20 张 A100 显卡,服务器加网络设备成本超 200 万人民币,功耗达数千瓦,还需独立机房与制冷系统。
苹果芯片在 AI 浪潮中意外找到了新定位

在设计 M 芯片之初,苹果更多是为节能、高效的个人创作而生。但统一内存、高带宽 GPU、Thunderbolt 多路径聚合等特性,却在 AI 浪潮中意外找到了新定位。
M3 Ultra Mac Studio 的起售价格为 3999 美元,配备 96GB 统一内存,而 512GB 的顶配版本价格确实不菲。但从技术角度来看,统一内存架构带来的优势是革命性的。
传统 GPU 即使是最高端的工作站卡,显存通常也只有 96GB。而苹果的统一内存让 CPU 和 GPU 共享同一块高带宽内存,避免了数据在不同存储层级之间的频繁搬运,这对大模型推理来说意义重大。
当然,EXO 这套方案也有明显的定位差异。它不是为了与 H100 正面对抗,不是为了训练下一代 GPT,而是为了解决实际的应用问题:运行自己的模型,保护自己的数据,进行必要的微调优化。
如果说 H100 是金字塔顶的王者,而 Mac Studio 正在成为中小团队手中的瑞士军刀。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
