
Amazon researchers developed a new AI architecture that cuts inference time by 30% by selecting only task-relevant neurons, similar to how the brain uses specialized regions for specific tasks. This breakthrough approach addresses one of the biggest challenges facing large AI models: the computational expense and latency associated with activating every neuron for every request, regardless of their relevance.
The traditional deployment of large language models (LLMs) and foundational AI systems has relied on activating the full network for every input. While this guarantees versatility, it results in significant inefficiency—much of the network’s activity is superfluous for any given prompt. Inspired by the human brain’s efficiency—the brain flexibly recruits only the circuits it needs for a given cognitive task—Amazon’s architecture mimics this behavior by activating neurons most relevant to the current input context.
Dynamic, Context-Aware Pruning
At the heart of this innovation is dynamic, context-aware pruning. Rather than trimming the model statically during training and locking in those changes, Amazon’s solution prunes the network “on the fly,” during inference itself. This enables the model to remain large and versatile, yet efficient and fast-active for any specific task.
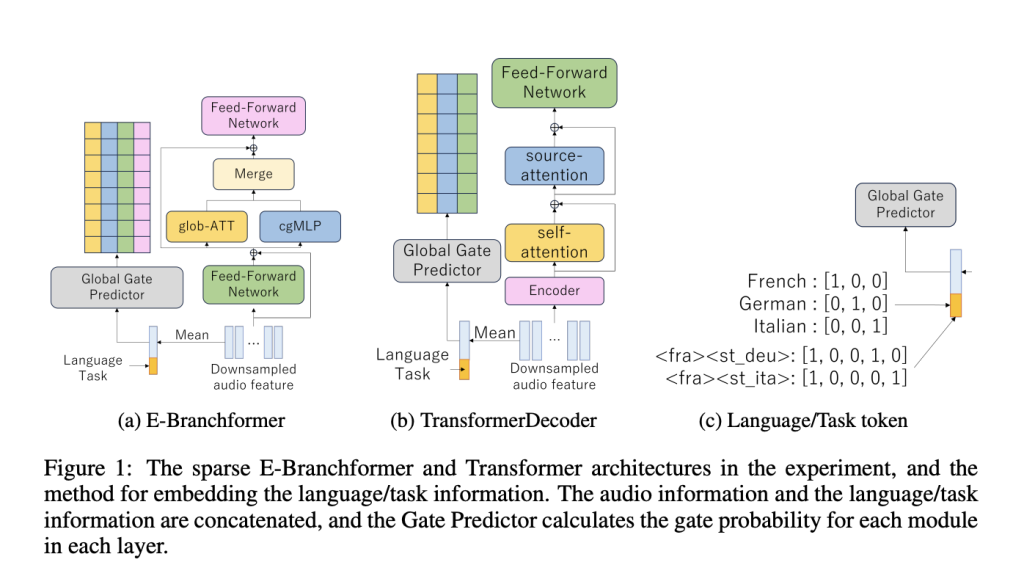
- Before processing an input, the model evaluates which neurons or modules will be most useful, based on signals such as the type of task (e.g., legal writing, translation, or coding assistance), language, and other context features.It leverages a gate predictor, a lightweight neural component trained to generate a “mask” that determines which neurons are switched on for that particular sequence.The gating decisions are binary, so neurons are either fully active or completely skipped, ensuring real compute savings.
How the System Works
The architecture introduces a context-aware gating mechanism. This mechanism analyzes input features (and, for speech models, auxiliary information such as language and task tokens) to decide which modules—such as self-attention blocks, feed-forward networks, or specialized convolutions—are essential for the current step. For example, in a speech recognition task, it may activate local context modules for detailed sound analysis while skipping unnecessary components that are only beneficial for other tasks.
This pruning strategy is structured and modular: instead of removing individual weights (which can lead to hardware inefficiency), it skips entire modules or layers. This preserves the model’s structural integrity and ensures compatibility with GPU and modern hardware accelerators.
The gate predictor model is trained with a sparsity loss to achieve a target sparsity: the proportion of modules skipped. Training uses techniques like the Gumbel-Softmax estimator, ensuring that gating behavior remains differentiable during optimization, but ultimately yields crisp, binary neuron selection at inference.
Demonstrated Results: Speed Without Sacrificing Quality
Experiments show that dynamically skipping irrelevant modules can:
- Reduce inference time by up to 34% for multilingual speech-to-text or automatic speech recognition (ASR) tasks—where typical baseline models suffered 9.28s latency, pruned models ran in as little as 5.22s, depending on the task and desired sparsity level.Decrease FLOPs (floating-point operations) by over 60% at high sparsity levels, greatly lowering cloud and hardware costs.Maintain output quality: Pruning the decoder in particular preserves BLEU scores (for translation tasks) and Word Error Rate (WER) for ASR up to moderate sparsity, meaning users see no drop in model performance until very aggressive pruning is applied.Provide interpretability: Analyzing pruned module patterns reveals which parts of the model are essential for each context—local context modules dominate in ASR, while feed-forward networks are prioritized for speech translation.
Task and Language Adaptation
A core insight is that optimal pruning strategies—meaning which modules to retain or skip—can change dramatically depending on the task and language. For instance:
- In ASR, the importance of local context modules (cgMLP) is paramount, while the decoder can be sparsified heavily with little accuracy loss.For speech translation (ST), both the encoder and the decoder require more balanced attention, as the decoder’s feed-forward layers are essential.In multilingual or multitask scenarios, module selection adapts but shows consistent patterns within each type, highlighting the learned specialization within the architecture.
Broader Implications
This dynamic, modular pruning opens the door for:
- More energy-efficient, scalable AI—especially vital as LLMs and multimodal models continue to grow.AI models that can personalize their compute pathways—not only by task but potentially by user profile, region, or device.Transferability to other domains, such as natural language processing and computer vision, wherever foundation models are used.
By selectively activating only task-relevant modules in real time, inspired by biological neural efficiency, Amazon’s architecture points the way toward AI that is both powerful and practical for global, real-world use.
Check out the Paper and Technical details. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post Amazon Develops an AI Architecture that Cuts Inference Time 30% by Activating Only Relevant Neurons appeared first on MarkTechPost.
