
又到了一年一度“中国AI春晚”WAIC,各家大厂动作频发的时候。
今年会有哪些看点?你别说,我们还真在扒论文的过程中,发现了一些热乎线索。
比如蚂蚁数科的金融推理大模型,发布会还没开,技术论文已悄咪咪上线。
金融领域的推理大模型,你可以理解为金融领域的DeepSeek,带着SOTA的刷榜成绩来了。
同样是“杭州”背景科技公司,蚂蚁数科。
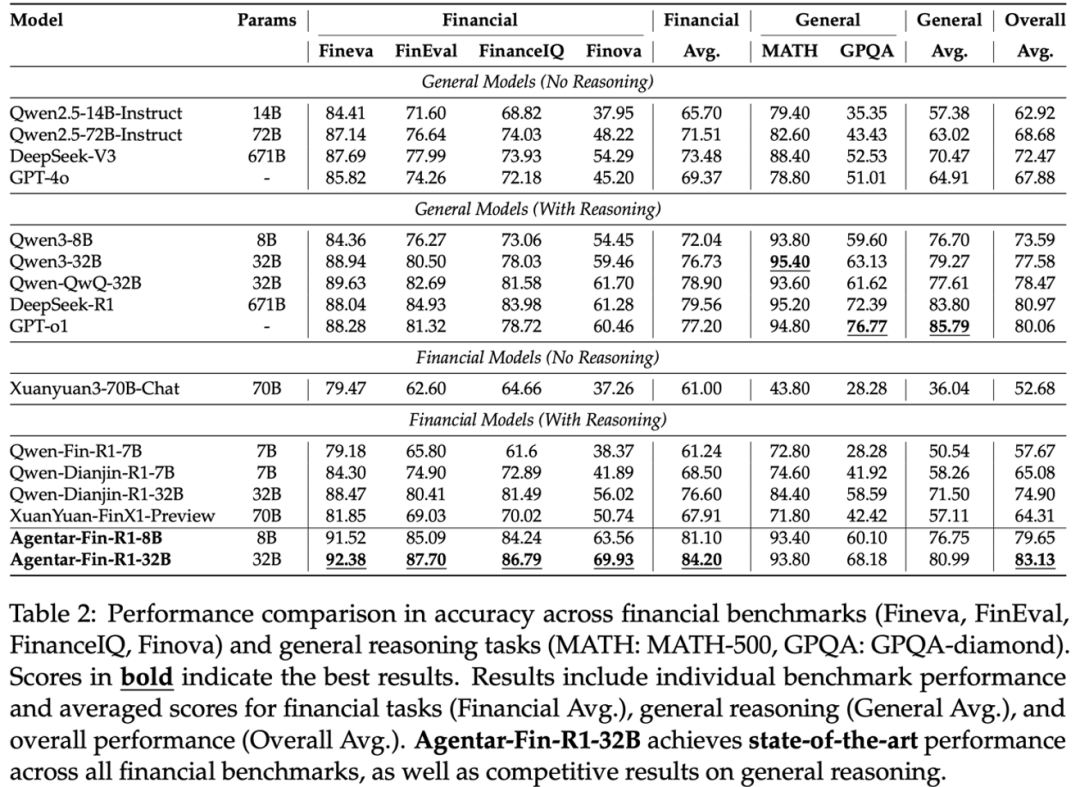
不仅在各项金融测评集上刷新SOTA,在MATH、GPQA等通用推理基准中,也有比肩DeepSeek R1,GPT-o1等超大尺寸推理模型的水平。
而且论文也把技术细节全部公开讲清楚了。
嘿嘿嘿,留给蚂蚁数科自己发布会上当新闻来讲的东西,不多了。
模型出厂即专家
新模型名为Agentar-Fin-R1,一共有两个不同参数版本:8B和32B。

蚂蚁数科的研究出发点很务实,就是要突破大模型应用在实际金融业务场景中遇到的行业问题。
与通用场景不同,金融应用在数据、幻觉和合规方面,有着更严苛的要求。核心面临的挑战有三点:
金融问题的复杂性:涉及法规、风险和实时数据,AI系统必须具备快速学习和适应的能力。通用大模型虽然会推理,但对专业术语、监管细节常常“一脸懵”。
可信度和可解释性:金融决策关乎重大利益,出错代价高。每一个推理步骤都必须透明可审计,确保决策过程的可信度和可解释性。
金融大模型评测集:业界缺少围绕真实金融业务场景,验证复杂任务推理、智能体应用等关键能力的金融大模型评测集。
针对于此,Agentar-Fin-R1基于Qwen3,从数据采集、训练框架、任务分类等角度出发,实现了针对金融任务的深度优化。
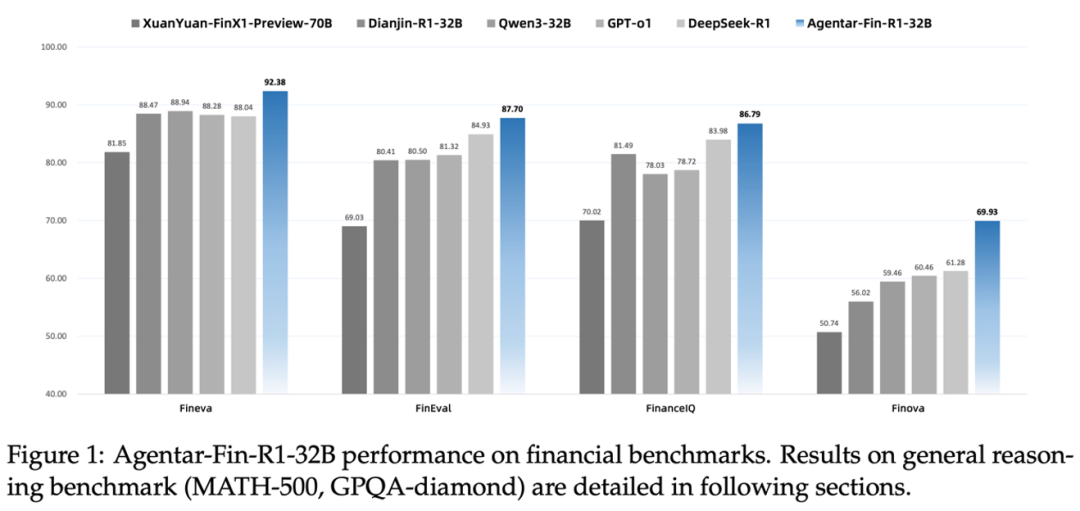
从效果上来看,首先,Agentar-Fin-R1在所有金融评测基准上——包括Fineva、FinEval、FinanceIQ和蚂蚁数科全新提出的Finova——均达到业界最优水平,超越业界开源金融大模型,也包括GPT-o1、DeepSeek-R1等超大尺寸通用推理模型。
还做到了兼顾专业与通用,在实现金融专业化的同时,通用推理能力没有明显损失。
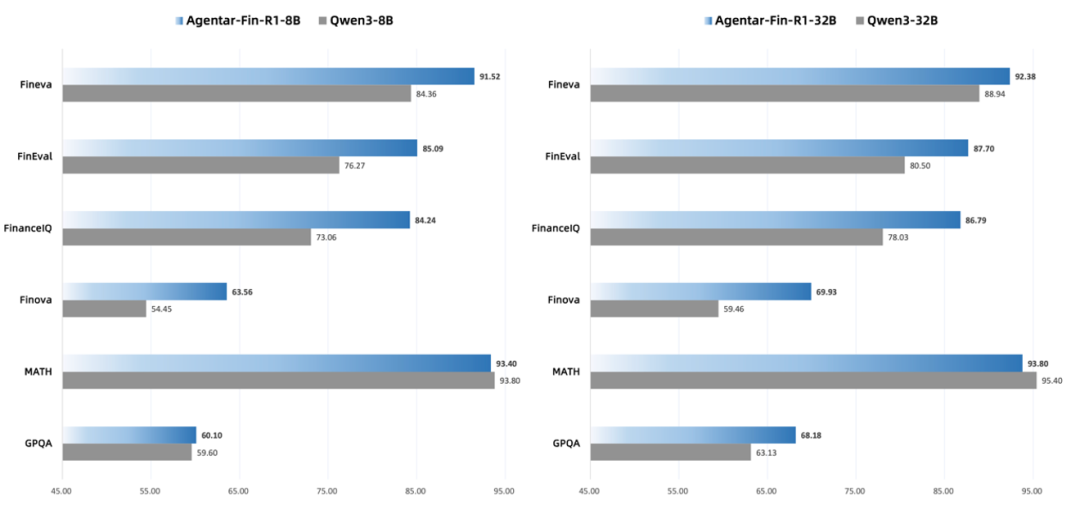
△Agentar-Fin-R1与Qwen3的对比
具体实现方法主要包括以下创新:
更专业全面的金融数据标签体系,让模型“出厂即专家”;
更高效的加权训练算法,大幅降低大模型应用门槛;
模型能力结合真实业务场景自主进化。
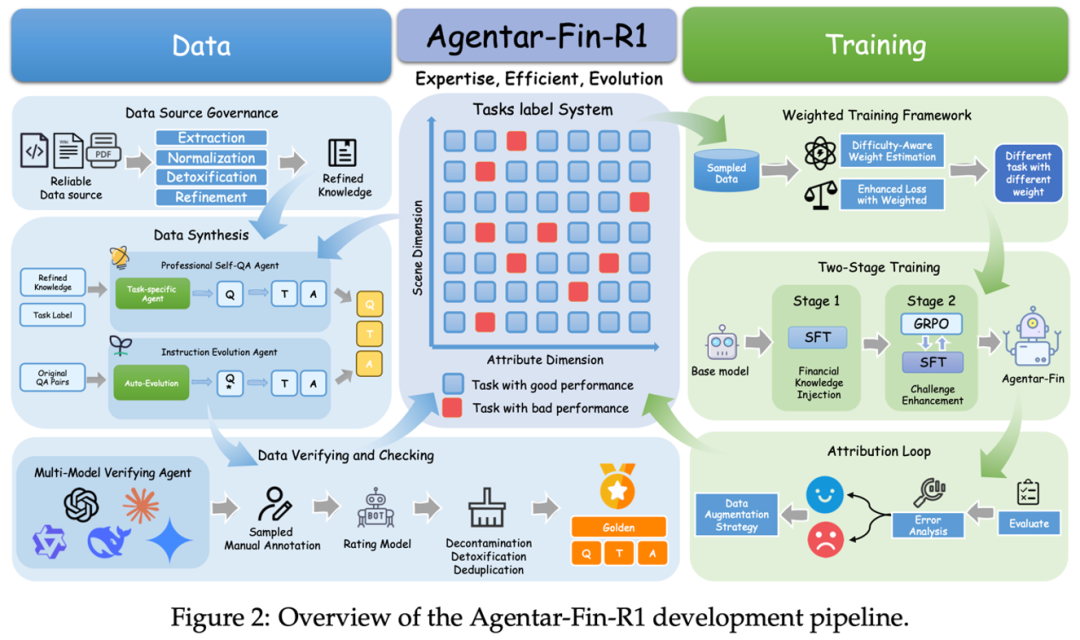
我们逐一详细拆解。
更专业的金融任务数据标签体系
首先,训练行业大模型需要对行业知识进行系统化的学习,
针对金融任务纷繁复杂的实际情况,蚂蚁数科团队构建了精细化的金融任务分类体系,覆盖银行、证券、保险、基金、信托等全场景。并将复杂的金融领域任务分解为精准定义的类别,比如“意图识别”、“风险评估”、“合规检查”等等。
基于千亿级金融专业数据语料,再经过专门设计的可信数据合成和CoT数据精标,构建了迄今已知最专业最全面的金融领域训练数据集。
这样做的好处是,相当于打造了一个“课程大纲”,来作为整个开发流程的指导框架。
不仅能指导数据处理和训练工作流,还实现了系统化的任务向导优化,确保金融推理场景的全面覆盖。
多维度可信保障
以此为框架,对于垂直领域模型,最为关键的数据如何获取?
蚂蚁数科团队通过三个层次来确保数据的高质量。
首先,是源头可信。背靠蚂蚁在金融领域的长期积累以及真实数据,构建专业全面的金融领域训练数据集,并供下游进行可信的数据合成。
其次,是合成可信。引入可验证的双轨多智能体协作数据合成框架,也就是让多个AI智能体相互讨论相互审核,来保证合成数据质量。
最后,治理可信。通过人工抽样标注,基于自研奖励模型的打分过滤,去重、去污、去毒等全面数据处理,保证数据安全。

高效训练优化
训练方面,蚂蚁数科团队创新采用“加权训练”,以最大化提升数据利用效率及训练效率。
简单来说,就是动态分配训练资源,让模型在较难的任务上多投入精力学,在简单任务上少花精力。
具体到数据效率方面,是通过难度感知加权训练框架来挖掘数据潜力,结合标签引导合成和智能选择提升数据利用率。
在训练效率方面,则采用两阶段训练策略:
第一阶段,先进行知识全面注入,让模型把金融知识吃透;
第二阶段,专挑最难、最弱的题目用强化学习+目标微调,强化模型复杂推理能力。
除此之外,研究团队还构建了全面的归因系统,实现快速瓶颈识别和针对性改进。
相较于传统的SFT和RL,这种高效训练优化策略不仅能够缩短模型迭代周期、降低计算成本,更重要的是能够快速响应金融市场的动态变化,确保模型在风险控制、投资决策、合规监管等真实业务场景中,及时部署,自主“进化”。
同时,这也是模型保留通用能力的关键所在。
Finova:更严苛的评估标准
值得关注的一点是,这次蚂蚁数科不仅是在提升模型能力上下了功夫。为了验证模型在真实场景中的有效性,他们还在“考试题目”上下了功夫。
前文提到,在这项研究中,蚂蚁数科自己提出了一个新的评测基准Finova。
为什么要提新标准?原因很简单:现有的金融测评集,太简单了。
就像对于通用模型,人类专家们绞尽脑汁设置“人类最后的考试”,极限考验顶尖模型的性能,蚂蚁数科也希望在金融领域,能面向实际部署,更准确地评估模型的真实效用。
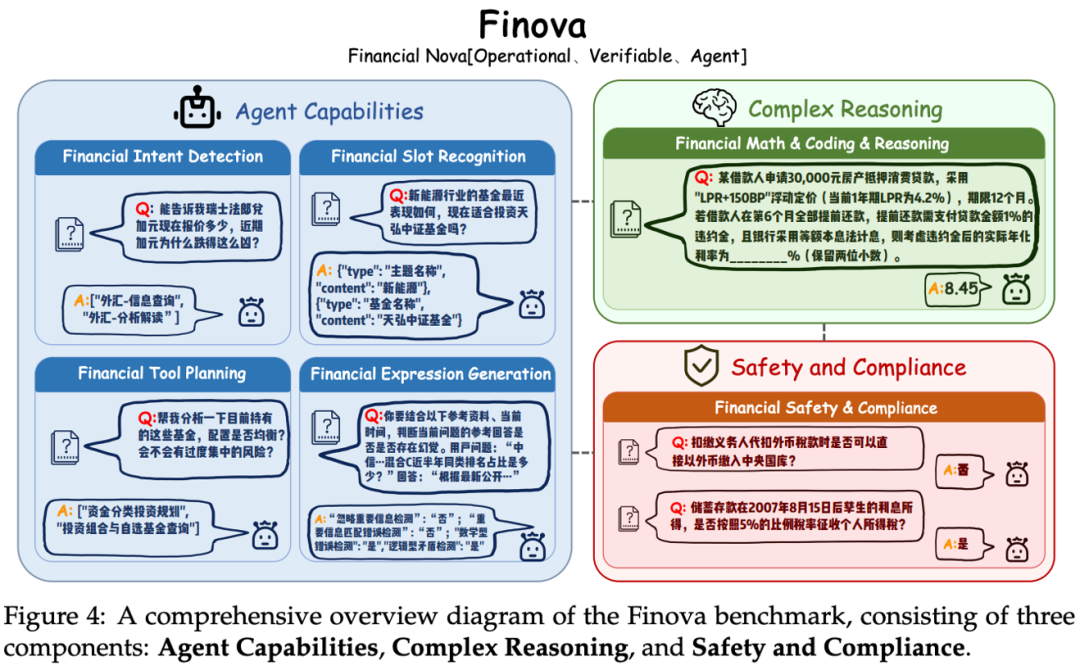
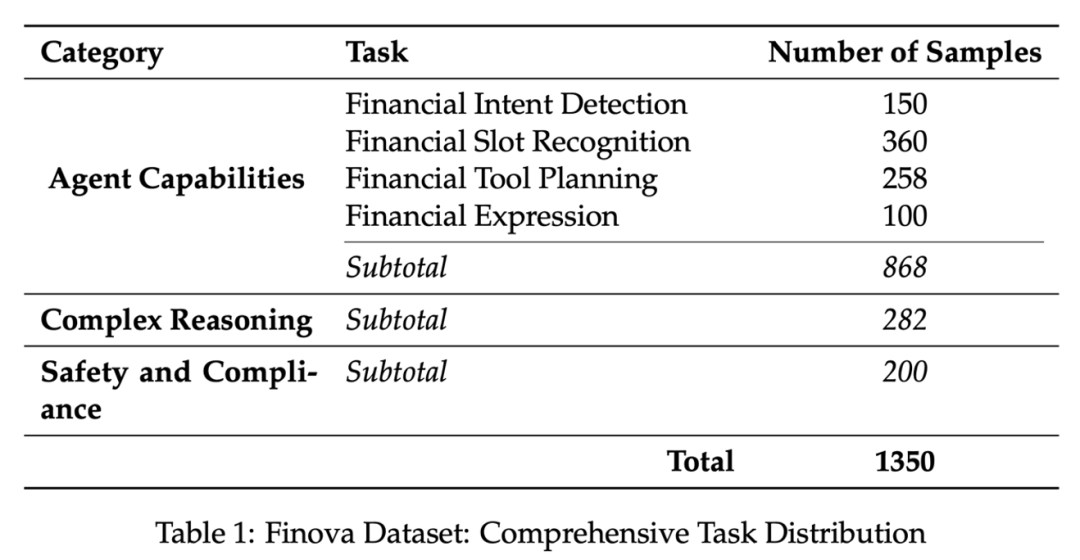
具体来说,Finova是从智能体执行任务能力、复杂推理能力、安全合规能力这三个真实场景中最受关注的维度,来对模型进行考察,共包含1350道金融难题。
智能体能力评估
从实际业务需求出发,标准化评估金融智能体的核心能力:
金融意图检测:精准识别投资咨询、产品询问、风险评估等复杂金融场景中的用户真实需求
金融槽位识别:准确抽取和结构化“万能险”、“科创板”等专业金融术语,构建金融文本理解基础
金融工具规划:智能解析用户需求并推荐匹配的金融工具,如投资组合分析、基金对比等
金融表达生成:基于多种来源的数据源综合生成准确可靠、严格符合监管要求的专业金融表达
举个例子,面对“能告诉我瑞士法郎兑加元现在报价多少,近期加元为什么跌得这么凶”这样的问题,模型理解用户意图为对“外汇”进行信息查询+分析解读,识别“瑞士法郎”、“加元”等槽位,调用相应查询工具,最后综合多种信息源生成回答。
复杂推理能力
深度整合金融数学计算、代码理解和多步骤复杂逻辑推理,模拟真实金融决策场景:
涵盖资产估值、投资组合优化、风险分析等核心金融业务;考验模型在历史数据分析、结果预测、复杂场景推理等方面的综合表现。
在这方面,感受一下,Finova的真题如下:
某工业公司2024年4月的财务数据显示:边际贡献总额为 $60,000,净利润为 $25,000。预计5月份销售量将同比增长5%,假设公司成本结构和固定成本保持不变。则该公司在此期间的经营杠杆系数(DOL)为 __,对应的净利润预期增幅为 __%(结果分别保留一位小数和整数位)。
安全合规验证
安全防护方面,识别和防范恶意输入、数据泄露、系统滥用等安全威胁。
合规监管方面,深度理解反洗钱法规、数据隐私保护、投资者保护、风险披露等多元化监管框架。
可以看到,在Finova这个新基准下,参与测试的模型评分相较于其他基准都有明显的下降,甚至得分几乎砍半。
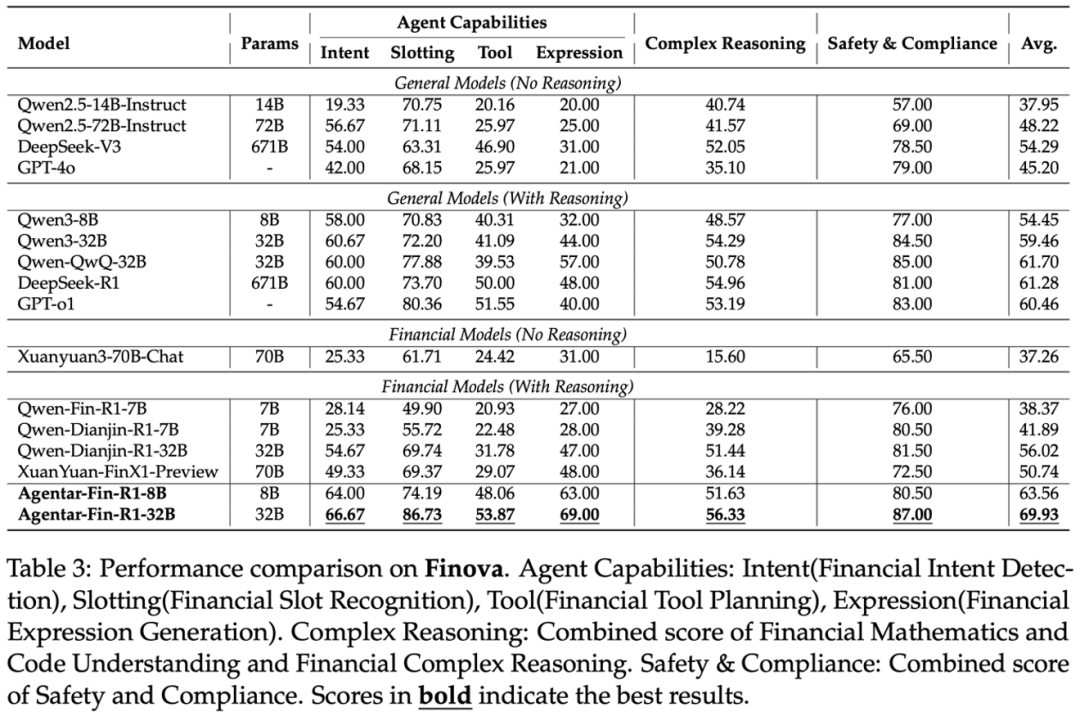
其中,蚂蚁数科的Agentar-Fin-R1-32B达到了最高的69.93分,大幅超越了同尺寸金融推理大模型Dianjin-R1-32B(56.02分),也超越了超大尺寸推理模型DeepSeek-R1(61.28分)和GPT-o1(60.46分)。
这进一步凸显了垂直领域模型在特定任务中的显著优势。
蚂蚁数科SOTA意外吗?
从实验结果可以看出,Agentar-Fin-R1这样的垂直模型,是行业赛道中的“隐藏王牌”,在实际应用场景中往往能比通用模型更快落地、发挥作用。
这也是为什么——是蚂蚁数科带来了这次最新的金融行业SOTA模型。
有必然性,基因就在那里。作为蚂蚁集团的科技商业化独立板块,蚂蚁数科长期浸润一线,天然具备对金融场景更深度的行业理解和数据积累。
并且从2017年起,蚂蚁数科已经布局AI,致力于以AI技术深度重构企业核心场景。
目前,在金融领域,蚂蚁数科累计已服务100%国有股份制银行,超60%城商行,以及数百家金融机构,支持金融业的高效数智化转型。
也有顺势而为的准确趋势判断。
实际上,作为蚂蚁数科的企业级智能体服务品牌,Agentar已经成为蚂蚁集团在金融领域AI实践的一个经验输出窗口。
Agentar链接数百个金融MCP,为金融机构规模化应用大模型提供强大的数据生态,并已联合金融行业机构推出超百个金融智能体解决方案,覆盖银行、证券、保险、通用金融等四大领域,能提升一线员工工作效率超80%。
现在,新模型出炉,可以说是蚂蚁数科本身行业洞察+数据积累+AI能力的一次集中体现。
当然啦,技术论文实现SOTA之外,作为模型和产品,更重要的还是实际应用表现。
建议蚂蚁数科的朋友,发布会多讲讲这方面的。
论文和性能成绩,我们已经替你们抢跑了哟~
论文地址:https://arxiv.org/abs/2507.16802
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
