
來源:騰訊科技
作者:蘇揚
OpenAI年底前將上線100萬張GPU,直觀感受就是新一輪芯片戰爭打響了。
7月21日,奧特曼在推特上預告,OpenAI到年底前將上線超過100萬張GPU。他還補充道,「對團隊感到自豪,但現在他們最好想想,怎麼在這個數量規模上再擴容100倍。」
 這句看似簡單的預告,實則暗藏多重信號:
這句看似簡單的預告,實則暗藏多重信號:
首先,規模碾壓對手。OpenAI的目標不再是10萬卡,20萬卡,要做就做100萬卡,這一規模將達到馬斯克旗下xAI訓練Grok 4所用20萬GPU的5倍;
其次,戰略自主。算力基礎設施的躍進,意味着OpenAI正逐步擺脫對微軟Azure的依賴——過去其算力高度綁定 $微軟 (MSFT.US)$ ,如今通過自建數據中心(如星門計劃)掌握主動權;
最後,OpenAI的行業野心也一覽無餘。「擴容100倍」直指AGI所需的終極算力目標,一場以算力爲基石的AI軍備競賽已進入白熱化。
這裏還有個小插曲——就在奧特曼定下衝刺100萬卡目標之後,華爾街日報就下場拆臺,稱星門計劃進度不順利,軟銀遲遲掏不出錢。但OpenAI隨即「滅火」:不僅官宣與$甲骨文 (ORCL.US)$加碼投資,將星門計劃擴容4.5吉瓦,還強調一期項目已部分投入運營,多方合作進展順利。
隨後,馬斯克更是直接「放衛星」,5年內,xAI要部署到5000萬張H100 GPU的等效算力。
按照單卡平均4萬美元粗略計算,100萬卡規模,僅GPU部分價值就高達400億美元,這種燒錢量級和速度,在科技行業也是前所未有,基本接近一線巨頭們的年資本支出。
$英偉達 (NVDA.US)$對此自然是樂見其成,問題是,行業數以萬計的計算卡需求,會將英偉達的市值推向什麼高度?
我們把視線再拉回算力上,OpenAI最近一次受算力影響最大的案例是3月份上線的「吉卜力風格」生圖功能,官方一度對產品做了限流處理,包括對生圖的速率進行暫時性限制,將免費用戶的生成額度限制在每日3次。奧特曼還在推特上高喊「我們的GPU快要融化了」,表面是宣傳產品,也可以看做是給猶豫不決的投資人「上眼藥」。
顯然,星門計劃還在籌資階段,OpenAI、軟銀、$甲骨文 (4716.JP)$們雖然能湊出500多億美元,但還有一半的缺口要通過債務融資完成,想要刺激投資人們掏錢,就得釋放一些星門計劃合理性的信號。
1、奧特曼「腳踏三隻船」
OpenAI對算力的追逐由來已久,其算力來源包括自研、星門計劃、微軟三個主要渠道。
關於自研芯片這件事,一度傳出奧特曼要籌集7萬億美元下場造芯的消息。不過,去年2月份,奧特曼委婉的否認了此事,在他與英特爾前任CEO帕特·基辛格的爐邊談話中曾說過:「我們確實認爲世界需要在AI計算(芯片)領域投入大量資金」。
根據行業的跟蹤和研究數據,OpenAI自研芯片一直在有序推進,其首款產品最快2026年問世。
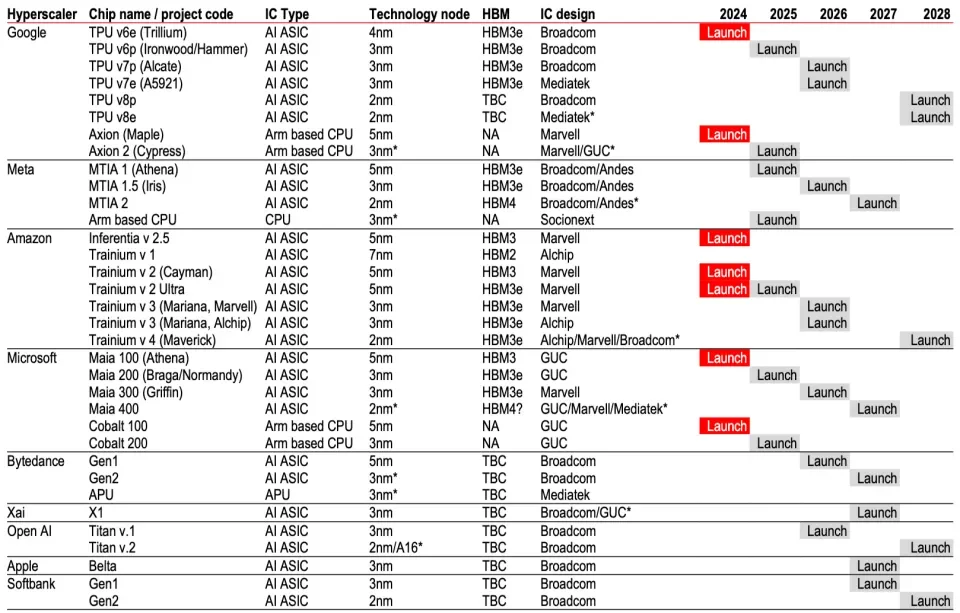
匯豐銀行研究團隊6月下旬披露了一份科技公司自研ASIC的進度表,包括谷歌、Meta、$亞馬遜 (AMZN.US)$、微軟、xAI等等在內的硅谷公司,清一色下場自研AI芯片。
研報顯示,OpenAI首款3納米自研芯片由$博通 (AVGO.US)$代工設計,代號爲Titan V.1,將於2026年發佈,更先進的Titan V.2芯片將於2028年問世,但不確定爲2nm工藝還是A16(1.6nm)工藝。
一位長期跟蹤半導體產業的分析師Paul則在推特上披露了OpenAI自研芯片的詳細規格和發佈時間(如上圖),強調Titan V.1將在2026年第三季度問世,核心配置包括N3工藝、144GB HBM3e顯存、兩顆計算芯片,採用CoWoS-S封裝等,但他認爲,Titan V.2將於2027年第三季度問世,比匯豐銀行的分析師團隊預測的2028年稍稍提前。
自研屬於長線規劃,在這條路跑通之前,OpenAI的腳開始伸向微軟之外的「另一條船」,牽頭搭建算力基礎設施。
今年1月份,OpenAI聯合軟銀、甲骨文推出星門項目,計劃四年在美國投資5000億美元,搭建算力基礎設施,首期投資1000億美元,其中軟銀承擔財務責任,OpenAI負運營責任。
這裏的重點是,運營權才是奧特曼在星門計劃中想得到的——想怎麼分配怎麼分配,打不打價格戰全都自己說了算。

4個月之後,OpenAI又攢了一個「阿聯酋版」星門計劃,計劃聯合G42、甲骨文、英偉達、軟銀等合作伙伴,在當地構建一個1吉瓦的數據中心,預計2026年投入使用。
這些宏大的基礎設施項目兌現之前,OpenAI的算力供給仍然依賴微軟——兩家自2019年開始合作,微軟向其提供了超過130億美元的直接投資,同時成爲OpenAI獨家算力提供商,微軟則在OpenAI的模型、收入分成等方面獲得優先權,比如可獲得OpenAI 49%的利潤分配權,最多可達到1200億美元。
依賴微軟,也要避免被微軟「卡脖子」。從7萬億美元造芯傳聞,到5000億的星門計劃,再到阿聯酋版星門,OpenAI核心邏輯是構建一個由自己主導,不斷堆高的宏大算力敘事。
沒有規模化的算力,就會隨時被谷歌的價格戰碾壓,而規模化是谷歌的先天優勢。產品層面,缺算力就如同「巧婦難爲無米之炊」,就會出現更多「吉卜力風格」生圖能力受限的問題,所以之前才會就有小道消息說,伊利亞因爲算力需求被砍憤而離職、GPT-5、DALL-E等就是因爲算力短缺而被迫延遲發佈等等。
巧合的是,在OpenAI「猛踩油門」的時候,微軟卻輕點了一下剎車。
今年4月份,美國券商TD Cowen分析師稱,微軟放棄了在美國和歐洲的2吉瓦新數據中心項目,微軟官方的回覆稱數據中心容量都是多年前規劃,現在各地佈局都已完善,所以做了一些靈活性的戰略調整。
微軟的戰略收縮,其實從去年底納德拉接受BG2播客訪談中就能找到信號,他當時毫不避諱的強調和奧特曼的分歧,「我們需要用嚴謹的方式來思考如何有效利用現有設備。同時也要考慮設備的使用壽命,不能一味地購買新設備。除非GPU的性能和成本能帶來顯著改善,讓利潤率達到或超過大型雲服務商的水平,否則我們不會輕舉妄動。」
大家都在追逐算力的安全感,納德拉認爲存量算力已經足夠,需要精細化運營,奧特曼擔心的是算力不夠成爲新模型、產品的掣肘。
於是,雙方越走越遠。
今年1月,微軟選擇了放手,與 OpenAI 修訂了合作條款,允許其使用第三方供應商的計算資源,很快甲骨文、$CoreWeave (CRWV.US)$這些雲廠,逐個都跟OpenAI簽訂了租賃協議。當然,爲了體面,微軟依舊擁有提供算力的優先合作權。
The Information援引投資人會議的消息稱,OpenAI計劃到2030年,將75%的算力來源轉移至星門項目上。
2、算力戰爭「燒掉」2.5萬億
OpenAI追逐算力,內部要實現「算力自主可控」,外部則是應對硅谷巨頭們的「算力戰爭」。
7月16日,The Information上線了專訪Meta CEO扎克伯格的內容,扎克伯格稱Meta正在建設多個數據中心集群。
“我們的人員正在夜以繼日地工作於普羅米修斯(Prometheus)和亥伯龍(Hyperion)項目中,這是我們的前兩個泰坦(Titan)集群,都將超過1吉瓦。亥伯龍將在未來幾年擴展到5吉瓦。我分享過它的圖片,從佔地面積來看,這個數據中心的規模佔了曼哈頓的相當一部分。它太龐大了。”扎克伯格說。

1吉瓦的數據中心是個什麼概念?
假設Meta在建的1吉瓦亥伯龍數據中心全部部署GB200 NVL72機架,按照單機架140KW的功耗計算,總計可容納7100+個機架,由於每個機架內置72張GPU,總計大約51萬張GPU,按照單機架300萬美元來折算,7100多個機架的總成本就超過210億美元。
而如果OpenAI和甲骨文新擴容的4.5吉瓦項目兌現,那麼未來OpenAI藉助星門計劃掌握的GPU就有可能衝到接近250萬張GPU的規模。
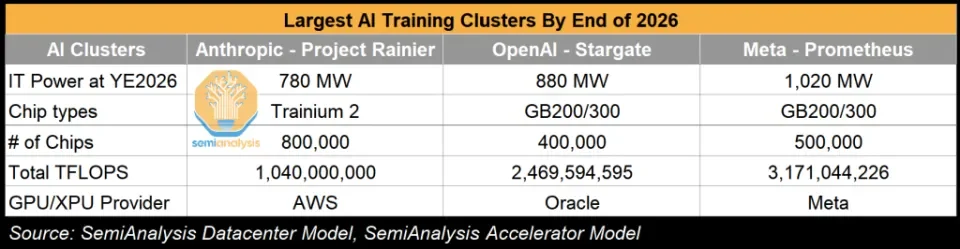
7月21日,知名研究機構SemiAnalysis基於其數據中心和加速器模型,披露了到2026年底,Anthropic、OpenAI和Meta的訓練集群數據。SemiAnalysis列舉了Meta的另一個1吉瓦容量的普羅米修斯數據中心項目,其採用GB200/300混搭,GPU總量達到50萬張,與我們對亥伯龍數據中心的預估結果基本一致。
能耗方面,1吉瓦的GB200 NVL72數據中心,全年365天24小時滿負荷運行,預計需要87.6億度電。作爲對比,日本東京2023年全年的用電量也就1300億度。
SemiAnalysis的跟蹤數據中未包含xAI,但作爲OpenAI的頭號對手,xAI同樣在「瘋狂」投資基礎設施。
7月10日,xAI公佈了旗下Grok 4模型,馬斯克在直播中透露該模型是在一個擁有超過20萬張H100 GPU的超級計算機集群。這句話的重點不止於這個20萬卡的集群,還在於xAI數據集群建設速度上——距離上一個節點「10萬卡」集群建成僅僅過去了9個月。
更誇張的是,xAI旗下首個10萬卡級別的Colossus AI 超級計算機集群,從建設到投入運營,耗時122天,建設效率「捲上天」。
關於爲什麼要這麼卷基礎設施建設,馬斯克在直播中透露過自己的邏輯,他強調如果依賴雲廠的算力,協調一個10萬卡的集群,預計需要18到24個月。「我們想,18到24個月,這意味着失敗是必然的。」馬斯克說。
自建122天,協調雲廠的算力最快需要18個月,這也一定程度上可以解釋爲什麼OpenAI不打算和微軟一起玩了——靠外部合作伙伴來協調算力效率太低,租賃算力只能作爲短期過渡方案,只有自己主導才能可控。
可以想象這樣一幅畫面:當OpenAI推出吉卜力風格圖片生成時,奧特曼說「我們的GPU快要融化了」,轉身向微軟協調算力支持卻碰了軟釘子——得到的回覆竟是「你再等等」。此刻的奧特曼,內心恐怕只剩下一聲無奈的嘆息。
回到xAI的20萬卡集群上來,按H100單卡2.5萬美元-3萬美元的價格,大致可以估算一下成本,整個GPU部分的成本就需要50億美元-60億美元,這還不包括基建和運營、維護的成本。
OpenAI、xAI、Meta在數據中心上的投入,是行業AI資本支出擴張的一個縮影。
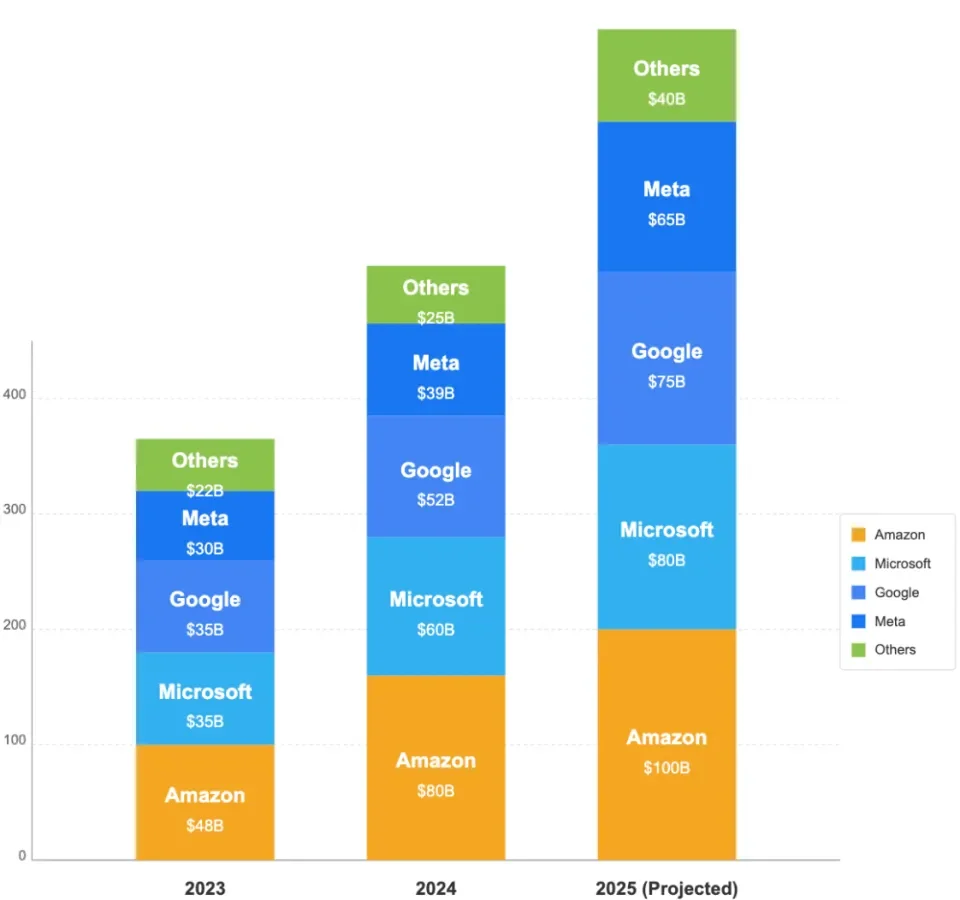
The Business Engineer分析師Gennaro Cuofano今年5月份發佈一份研究報告,內容援引硅谷公司的業績、行業預測數據,梳理了2023、2024、2025三個年度硅谷大公司在AI上的資本支出,對應數值分別爲1700億美元、2560億美元、3600億美元。
全年3600億美元,摺合人民幣超過2.5萬億元,這個規模相比2023年增長超過110%。更重要的是,大公司的AI支出佔據了全行業85%以上,這也意味着AI基礎設施建設的「馬太效應」不斷強化——未來頭部雲廠將掌握着行業的核心資源。
巨頭們紛紛捲入這場2.5萬億美元算力戰爭,也還有一個值得關注的背景——OBBB(大漂亮法案)簽署通過。
根據法案,科技巨頭們的大型數據中心基礎設施建設、研發等都可獲得稅收抵免。以設備全額折舊爲例,比如企業購買價值 1 億美元的服務器等數據中心硬件。 按傳統折舊規則需要分5年進行,每年只能抵扣2000萬美元。 根據法案,企業可在購置當年一次性抵扣1億美元應納稅所得額。
業務上有需求,競爭對手都在卷,政策又變相的起到了催化劑作用,都刺激着奧特曼、扎克伯格和馬斯克們,迫不及待的再打一場硅谷芯片戰爭。
如果非要問一個問題,有了百萬級的GPU,人類能打開AGI時代的大門嗎?
編輯/rice
