
Published on July 25, 2025 2:49 PM GMT
There have been multiple recent calls for the automation of AI safety and alignment research. There are likely many people who would like to contribute to this space, but would benefit from clear directions for how to do so. Stemming from a recent SPAR project and an ongoing project at PIBBSS, and in light of limitations of current systems, we provide a brief list of concrete projects for improving the ability of current and near-future agentic coding LLMs to execute technical AI safety experiments. We expect each of these could be meaningfully developed as short-term (1 week to 3 months) projects.
This is in no way intended to be a comprehensive list, and we strongly welcome additional project ideas in the comments.
Note: Due to our background and current research areas, the examples in this post focus on mechanistic interpretability research. However, the general techniques here should be applicable to other sub-areas of technical alignment and safety research.
Concrete Projects
These are largely focused on improving LLM usage of current software packages. Projects are roughly in order of increasing scope. We include initial pilot versions of some of these ideas.
Improving LLM Usage of Relevant Software Packages
Compiled Monofiles
As noted in a recent paper by METR, current AI systems often can struggle due to lack of sufficient context, particularly for large and/or complex codebases. One way to provide extensive contextual information about a package to a coding agent is by converting it into a single large file. As suggested in Building AI Research Fleets, “More generally, consider migrating to monorepos and single sprawling Google Docs to make it easier for your AI systems to load in the necessary context.” However, while actually migrating research code to monorepos may improve LLM comprehension to a degree, it also destroys organization that is useful (both to human coders and AIs).
Alternatively, existing repositories can be converted to single large files, e.g. llms.txt, which can then be fed to the agent. There are existing tools, such as RepoMix, which aim to achieve this. We provide an example RepoMix configuration file and examples of generated results. These files can be generated locally as needed or shared publicly, or even bundled with the packages themselves.[1] Note that, with no compression at all, this can result in very large files for large packages. Careful tuning of what to include or filter (e.g. large changelogs, empty spaces) can have a big effect on file size, but excessive compression may destroy useful information. One possible project direction would be varying different compression/filtering parameters and then benchmarking model performance on relevant tasks–this could reveal what information is most relevant for helping models automate research.
Indexable API documentation
As an alternative/complement to indexable documentation, some AI coding systems (e.g. Cursor) provide the ability to ‘index’ the documentation of packages. This gives coding agents access to things like package structure, docstrings, and usage demos without requiring the package files to be locally available. However, we found that safety-related packages we tried to index either did not have API documentation at all, or this documentation was not in a format that Cursor can effectively index.
To address this, we suggest setting up automated systems for generating indexable docs for packages used in technical research, enabling AI coding agents to more effectively use these packages. Tools such as Sphinx and MkDocs enable automated generation of API documentation. This could either be integrated into the package repositories themselves or generated separately and stored in a public location.
Note that there are also MCP servers like Context7 which give AI agents access to documentation, provided it has been indexed on their website. This may serve as an alternative route for providing agents with package context, and could be evaluated against Cursor-style integrated indexing.
Iteratively refined package guides
One limitation of the above approaches is that they are likely to provide models with large amounts of irrelevant information. This means that models are still likely to make mistakes despite the presence of relevant documentation or examples. Furthermore, without some form of long-term memory across sessions, coding agents often repeat the same mistakes over and over. (For example, we find that coding agents consistently struggle to figure out how to use NNsight context properly, even with access to working examples.)
To address this, we propose creating ‘package guides’ based on mistakes that LLMs actually make during real tasks. These can be thought of as capturing “learned wisdom” from experience, similar to a human coder learning from experience.[2] These could be constructed in a variety of ways, but we suggest generating them similarly to how human coders often learn: starting with available examples, attempting actual use cases, and iteratively debugging and refining implementations of tasks. This can all be done by the coding agent itself, requiring minimal human input.
One possible general iterative loop for generating such a guide looks like:
- Planning
- Explore available documentation, code, demos, etc.Create a list of intended use cases, break them into tasks and subtasks, and identify relevant examples.
- Implement and carefully test tasks and subtasks.Update guide to note any initial misunderstandings or critical insights in the guide, add example code snippets
- Re-examine available documentation and examples, exploring alternative ways to complete tasks.Implement alternative methods and test similarly to before.[This step can be repeated multiple times.]
- Initialize a new coding agent, providing only a task and the package guide, and repeat the above steps.
The result is a structured guide built from actual model experience with a package. Optional additional steps could include increasingly large-scale tasks—implementing experiments end-to-end, integrating with other packages, or replicating full papers.
We generate a few examples of guides like this using a simplified version of the steps described above using Claude 3.7 and Cursor—see the example guides here, and example LLM prompts to generate such guides here.
Structured sandbox environments
Ideally, a researcher or research agent would be able to quickly implement a research idea without needing to design a full (often complex) implementation and testing setup. For example, a researcher from another field may want to explore whether insights from their field can be applied to a problem in AI safety. These ideas could be tested more quickly and with a lower barrier of entry if doing so did not require implementing full experimental setups themselves, using packages and datasets with which they are likely unfamiliar.
A solution to this is pre-designed sandbox setups—programming environments where the core structure is already set up and tests are in place, such that variants of an idea can be quickly and easily iterated over. For example, a sandbox setup for training and evaluating sparse autoencoders (SAEs) could consist of a set of scripts containing flexible model classes, trainers, and evaluation scripts. These could be carefully designed such that the implementation of new SAE variants (e.g. a change in loss calculation or architecture) can be implemented via simple, targeted changes, without full understanding of the rest of the setup.
We provide an example of such a sandbox for designing SAEs here.
This ‘sandboxing’ approach carries two primary benefits:
- Simplicity/Efficiency: sandboxing outsources the process of setting up an experimental environment, allowing an AI agent to efficiently implement and test many different variants.Guardrails: sandboxes can provide clear guardrails on what the agent can modify. We find that, in practice, agents sometimes modify evaluation code without being instructed to do so. This can be done without explicitly attempting to reward tamper. Attempts to fix errors arising during evaluation (e.g. a shape mismatch or invalid input type) may inadvertently change the evaluation in other ways, leading to spuriously high or low scores. By whitelisting which files an agent may change, you prevent accidental (or adversarial) edits to evaluations.
Currently, it is likely most effective to have these environments created by human researchers who are somewhat knowledgeable about the packages involved. Spending a day to build a robust setup could easily pay off if it enables coding agents to effectively iterate over an arbitrarily high number of variants. Alternatively, current or near-future AI agents may be able to create these environments with careful testing and feedback.
Focused Benchmarks of Safety Research Automation
Note: Evaluating the true ‘success’ (i.e. usefulness) of the previously described tools can be difficult without quantitative evaluations. Consequently, we think that evaluations in this or a similar form should probably be especially prioritized.
Compared to massive volumes of code for training models present within the training data of modern LLM agents, exposure to safety-focused codebases during model training is much smaller. This disparity is also present in evaluation; there are multiple benchmarks for autonomous programming and research using packages like PyTorch and Transformers, but none (to our knowledge) focusing on automated use of tools like TransformerLens or Inspect. Evaluations that specifically test coding agents on their ability to use existing technical safety research tools would fill this gap (think PaperBench/MLE-Bench for safety research).
This could contain multiple tiers of tasks, ranging from small-scale tests (“Write a function that uses transformerlens to print the shape of the first-layer MLP outputs for this model.”), to medium-scale objectives (“Train a skip transcoder using Sparsify.”), to larger tasks, such as full experiments or paper replications. Evaluation metrics could include binary ‘succeeded’/’failed’, as well as more continuous metrics like time to complete, number of iterations before success, number of tool calls, rating for each sub-task node in a more complex task, et cetera. You can think of a project as a set of task nodes and you are more likely to lead to automation if you increase the reliability of doing that task successfully (and efficiently) in the future.
We think that benchmarks of this sort are critical for evaluating the usefulness of the other tools we have described (monofiles, indexable docs, package guides).
Side Notes
A series of side notes not about the technical aspects of the above projects, but related to their broader context and importance. We recommend reading them.
Implications of the recent METR paper
A recent paper by METR found negative results regarding the usefulness of AI-based coding assistance for expert developers. One wrong takeaway from this is that current AI coding systems are net harmful for coding across the board. The authors have gone to considerable effort to clarify what exactly their results do not say, both on X and in the report itself:
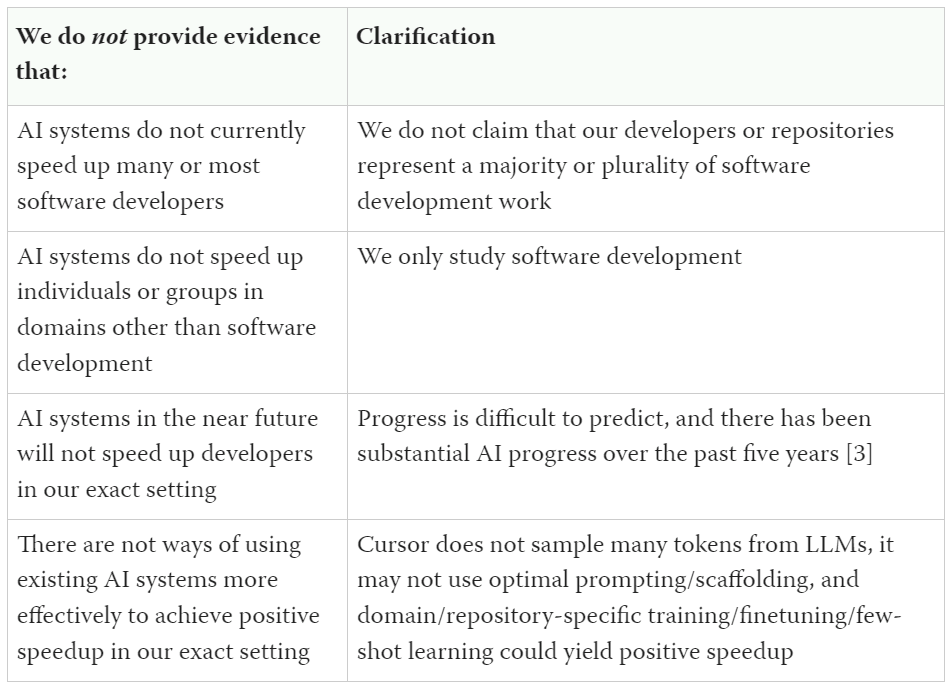
To summarize, negative results in a case with highly experienced human coders—using codebases of which the experts already have extensive knowledge—do not imply that the same coding systems could not be highly useful in other contexts. It’s also worth noting that even in the experiment from the paper, results were not negative for all cases. For example, see this thread from one of the participants in the original study who achieved a 38% speedup from using AIs.
In the report, the authors also note five likely factors harming AI usefulness in their experiment.

Of these factors, two relate directly to the aims of the projects we’ve described: AI struggling in complex code environments (C.1.3) and failing to utilize important tacit knowledge or context (C.1.5). The fact that these correspond closely with the explicit motivations of our some of our projects (compiled monorepos, indexable docs, package guides) suggest that these projects are worth pursuing.
How large is the risk that these will inadvertently accelerate other, harmful research directions?
As mentioned earlier, existing AI coding evaluations primarily test models on popular libraries and common software development tasks. This puts codebases with small user bases at a systematic disadvantage for LLM use. Indeed, in our project, we found that whereas LLM coding agents still made errors when using packages like PyTorch, these errors generally indicated small-scale misunderstandings, such as the absence of a function argument in some PyTorch versions. In contrast, when attempting to use more niche, interpretability-focused packages, they consistently made much larger mistakes that seem to reflect broad misunderstandings of the high-level functionality and structure of these packages.
The concrete directions we described above are intended to reduce this systematic disadvantage. Consequently, we expect these techniques would yield a much smaller benefit in research areas like AI capabilities than in AI safety.[3] Given these factors, we consider the risk that these techniques will translate to areas like general capabilities research to be low.
Should we just wait for research systems/models to get better?
People are already using AI for automating safety research. Even without full automation, AI can still substantially accelerate the rate of some research areas. Furthermore, research automation is unlikely to be a phase change; techniques that improve safety research automation today are still useful, and may still be useful when we have more capable systems.
Moreover, once end-to-end automation is possible, it will still take time to integrate those capabilities into real projects, so we should be building the necessary infrastructure and experience now. As Ryan Greenblatt has said, “Further, it seems likely we’ll run into integration delays and difficulties speeding up security and safety work in particular[…]. Quite optimistically, we might have a year with 3× AIs and a year with 10× AIs and we might lose half the benefit due to integration delays, safety taxes, and difficulties accelerating safety work. This would yield 6 additional effective years[…].” Building automated AI safety R&D ecosystems early ensures we're ready when more capable systems arrive.
Research automation timelines should inform research plans
It’s worth reflecting on scheduling AI safety research based on when we expect sub-areas of safety research will be automatable. For example, it may be worth putting off R&D-heavy projects until we can get AI agents to automate our detailed plans for such projects. If you predict that it will take you 6 months to 1 year to do an R&D-heavy project, you might get more research mileage by writing a project proposal for this project and then focusing on other directions that are tractable now. Oftentimes it’s probably better to complete 10 small projects in 6 months and then one big project in an additional 2 months, rather than completing one big project in 7 months.
This isn’t to say that R&D-heavy projects are not worth pursuing—big projects that are harder to automate may still be worth prioritizing if you expect them to substantially advance downstream projects (such as ControlArena from UK AISI). But research automation will rapidly transform what is ‘low-hanging fruit’. Research directions that are currently impossible due to the time or necessary R&D required may quickly go from intractable to feasible to trivial. Carefully adapting your code, your workflow, and your research plans for research automation is something you can—and likely should—do now.
- ^
If package authors do not want these integrated into their packages, it may be useful to have a dedicated platform or repository for generation and storage of these, as well as the following two projects (indexable docs and package guides). These could be automatically generated/updated once per package version and then stored in a shared repository. This way, researchers could just download the latest versions when needed rather than having to generate them individually. This could also enable improvements to these methods to spread more efficiently.
- ^
It has been suggested that a lack of continual learning may prevent AIs from reaching some levels of capability. What we describe here can be thought of as a form of continual learning–AIs can keep track of issues they encounter and how to resolve them, and then draw from this information in similar circumstances in the future. Training these insights into model weights may not be necessary if they can be accessed in the model’s context.
- ^
AGI labs may also be more bottlenecked on compute than AI safety research.
Discuss
