本文深入解析了DeepSeek-V2模型的核心技术,重点介绍了Multi-head Latent Attention(MLA)和Mixture-of-Experts(MoE)机制。MLA通过对Key和Value进行低秩联合压缩,显著减少了推理时的KV缓存,从而加速了模型推理速度。MoE模型则通过引入“专家”网络和负载均衡策略,在训练时实现了高效预训练,并在推理时通过选择性激活“专家”大幅降低了计算量。此外,文章还提及了Multi-Token Prediction(MTP)训练目标,旨在提升模型一次性预测多个未来token的能力,从而优化训练效率和模型性能。
💡 Multi-head Latent Attention (MLA) 是一种创新的注意力机制,它通过对Key和Value进行低秩联合压缩,显著减少了在模型推理过程中需要缓存的KV参数量。具体而言,MLA首先将Key和Value压缩成一个低维度的潜在隐向量,然后通过上投影矩阵将其重建为Key和Value矩阵。这一设计使得模型在推理时只需缓存少量信息,从而大幅提升了推理效率,尤其是在长序列处理场景下。此外,MLA还通过解耦键(K)和旋转位置编码(RoPE)的结合,解决了潜在隐向量缺乏位置信息的问题,确保了模型能够准确捕捉序列中的位置关系。
🚀 Mixture-of-Experts (MoE) 是一种高效的模型架构,其核心优势在于通过引入多个“专家”网络来处理不同的输入token,从而在参数量更大的同时,保持较低的计算成本。在训练阶段,所有专家都会参与,并通过负载均衡策略确保每个专家都能得到充分利用,实现端到端的有效预训练。而在推理阶段,模型仅需选择Top-k个专家来处理每个token,这使得推理时的参数量和计算量相比密集模型大幅降低。例如,在拥有8个专家的模型中,推理阶段的参数量仅为训练阶段的约1/4,极大地提升了模型的可部署性。
🎯 Multi-Token Prediction (MTP) 是一种新颖的训练目标,它旨在提升大型语言模型(LLM)一次性预测多个未来token的能力。与传统的自回归模型逐个预测token不同,MTP允许模型同时学习和预测多个位置的标签。具体实现上,它引入了一个“草稿模型”来辅助主模型进行多token预测。草稿模型利用主模型中间层的特征,并结合当前token的词向量进行预测。通过Teacher forcing模式训练草稿模型,并最终将草稿模型的预测结果与主模型的预测结果进行比对,以选择一致的序列作为最终输出。这种方法能够显著提高训练效率,并可能增强模型处理长序列和复杂上下文的能力。
🌟 DeepSeek-V2模型还融入了GPPO(General Preference Preference Optimization)等技术,虽然文章未详细展开,但暗示了其在模型对齐和优化用户偏好方面的持续探索。GPPO通常用于微调模型,使其输出更符合人类的偏好,这对于提升模型的实用性和用户体验至关重要。结合MLA和MoE等核心技术,DeepSeek-V2有望在性能和效率上实现显著的突破,为LLM领域带来新的进展。
DeepSeek-V2
Multi-head Latent Attention (MLA)
传统的多头注意力机制(MHA,Multi-Head Attention):
在标准的Transformer中,多头注意力机制(MHA)通过并行计算多个注意力头来捕捉输入序列中的不同特征。每个注意力头都有自己的查询(Query, Q)、键(Key, K)和值(Value, V)矩阵,他们各自的主要作用如下:
查询矩阵 Q:查询矩阵是你想要寻找某个信息的"问题"。在Transformer中,查询矩阵是输入的一个投影,表示当前token对其他token的"需求"。它帮助你确定自己在序列中的位置和需要关注什么内容。
键矩阵 K:键矩阵是每个token提供的"信息"或"标识符"。每个token都有一个与之关联的键,用于与查询进行对比,以确定它与查询的相关性。你可以把键想象成词语的"标签"。
值矩阵 V:值是实际的信息,提供了词向量的内容。根据Q与K的匹配程度,V最终用来生成输出向量。
假定:d是隐向量维度,nh是注意力头的数量,dh是每个注意力头的维度,ht是attention层地t个token的输入隐向量。
标准的MHA首先使用三个权重矩阵(训练参数)Wq,Wk,Wv∈Rdh∗nh∗d计算得到qt,kt,vt向量。然后qt,kt,vt向量拆分成nh份(每个注意力头分一份):
[qt,1;qt,2;...;qt,nh]=qt
[kt,1;kt,2;...;kt,nh]=kt
[vt,1;vt,2;...;vt,nh]=vt
使用qt,kt计算注意力得分,并使用注意力权重对vt进行加权求和,得到每个注意力头的结果:
ot,i=∑j=1t︁Softmaxj(dhqt,iTkj,i)vj,i
最后把所有注意力头结果向量拼接起来,通过一层限行映射回原始维度:
ut=WO[ot,1;ot,2;...;ot,nh]
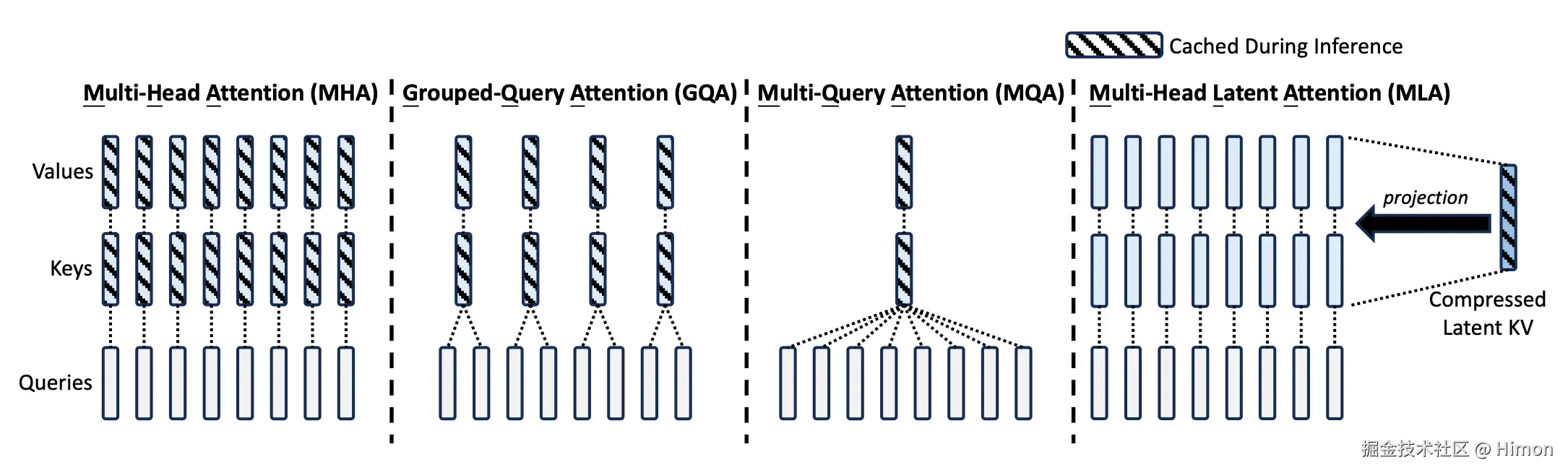
MLA的核心是对value和key进行低秩联合压缩来减少推理时的键值缓存(KV cache),MLA设计中所有的K和V都需要缓存,MLA只需要缓存一个压缩的向量,并且此向量纬度远远小于dhnh,只需要在推理计算时再向上投影生成所有的K和V。具体计算如下:
对value和key进行低秩联合压缩:
 具体的:
具体的:生成压缩潜在隐向量(latent vector),其中WDKV∈Rdc×d是下投影矩阵 ctKV=WDKVht。通过上投影矩阵WUK,WUV∈Rdhnh∗dc将潜在隐向量分别重建键K矩阵和值V矩阵,注意可以认为是映射成隐向量维度 h ,而不是每个注意力头的维度:ktC=WUKctKV,vtC=WUVctKV应用旋转位置编码(RoPE),引入位置信息。因为传统的MHA中,每个token都对应着自己的K向量,天然包含了位置信息,现在通过一个共用的潜在隐向量映射得到的K是不包含位置信息的。ktR=RoPE(WKRht)。其中, WKR∈RdhR∗d是用于生成解耦键的矩阵, dhR是解耦键的维度。将位置矩阵 ktR和上投影得到的矩阵 ktC拼接得到最终的地t个位置token的K矩阵:kt=[ktV;ktR],vt=vtC。
因此在推理过程中,为了加速推理,需要将K、V缓存。当采用MLA:只有ktKV和ktR需要缓存,只需要缓存(dc+dhR)∗l个参数。如果是MLA,所有keys和values向量都需要缓存,则需要缓存 2nhdhl 个参数。
同样的,为了降低训练过程中的内存激活量,对Q也进行类似的处理:
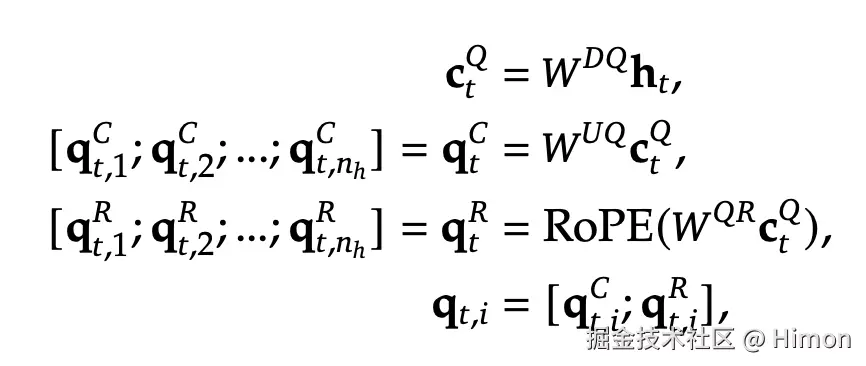
最后使用query (qt,i),keys (kj,i)和values (vj,iC)计算attention结果,这里qt,i和kj,i都拼接了RoPE位置向量,所以纬度是一样的,其中WO∈Rd∗dhnh表示输出映射层矩阵 , 最终得到纬度为d的输出隐向量:
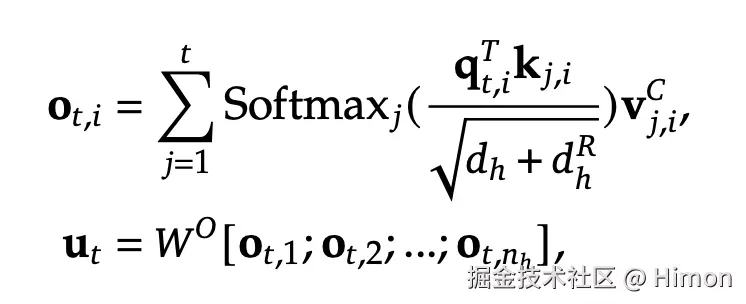
代码实现:
在Deepseek-V3中,K和V的维度都是7168,
这个设计在推理的时候无法直接应用RoPE,MLA巧妙将两个部分分开计算。
参考:
zhuanlan.zhihu.com/p/151537455…zhuanlan.zhihu.com/p/218171829…
DeepSeekMoE-V2
MOE:
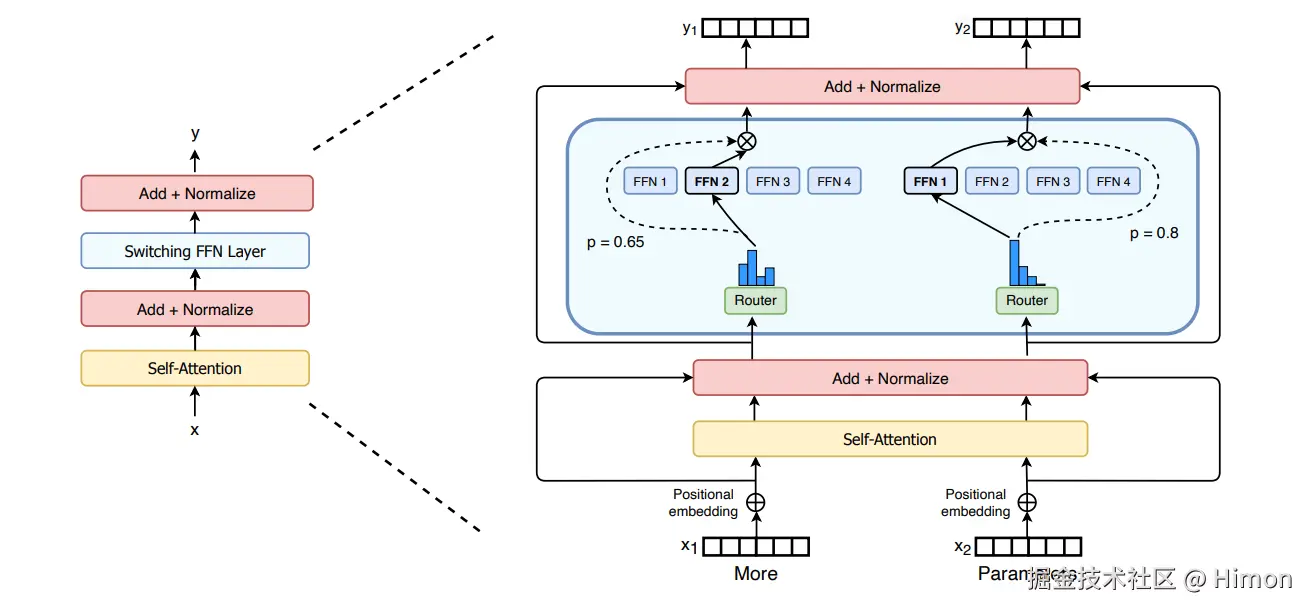
MoE的优势是能够在远少于稠密模型所需的计算资源下进行有效预训练。
概要:
MoE是整个网络的一部分,在训练阶段,所有"专家"都参与的,end2end训练,所谓“专家”网络只是在训练过程中处理序列中特定的token,而不是对特定的任务来训练某个“专家”网络。它还有个“负载均衡”的概念,就是让每个专家尽量参与,这样整个模型更高效。用MOE就可以把网络做的很宽,参数量更多。
在推理阶段,每个token只需要选择topk个“专家”,参数量就明显降低了。比如一个“专家”网络参数量是N,采用8个专家,模型总32层,专家层这部分参数量,训练阶段就是 328N,在推理阶段只需要 322N,就少了很多。
至于“专家”层怎么进行并行计算,它是每一层for循环每个“专家”,选出来各自负责处理的token对应的输入隐向量,按照顺序重排构造矩阵(需要padding),再对应与hidden层的weight相乘,最后再将每个token的结果向量reduce相加。
DeepSeek-V3
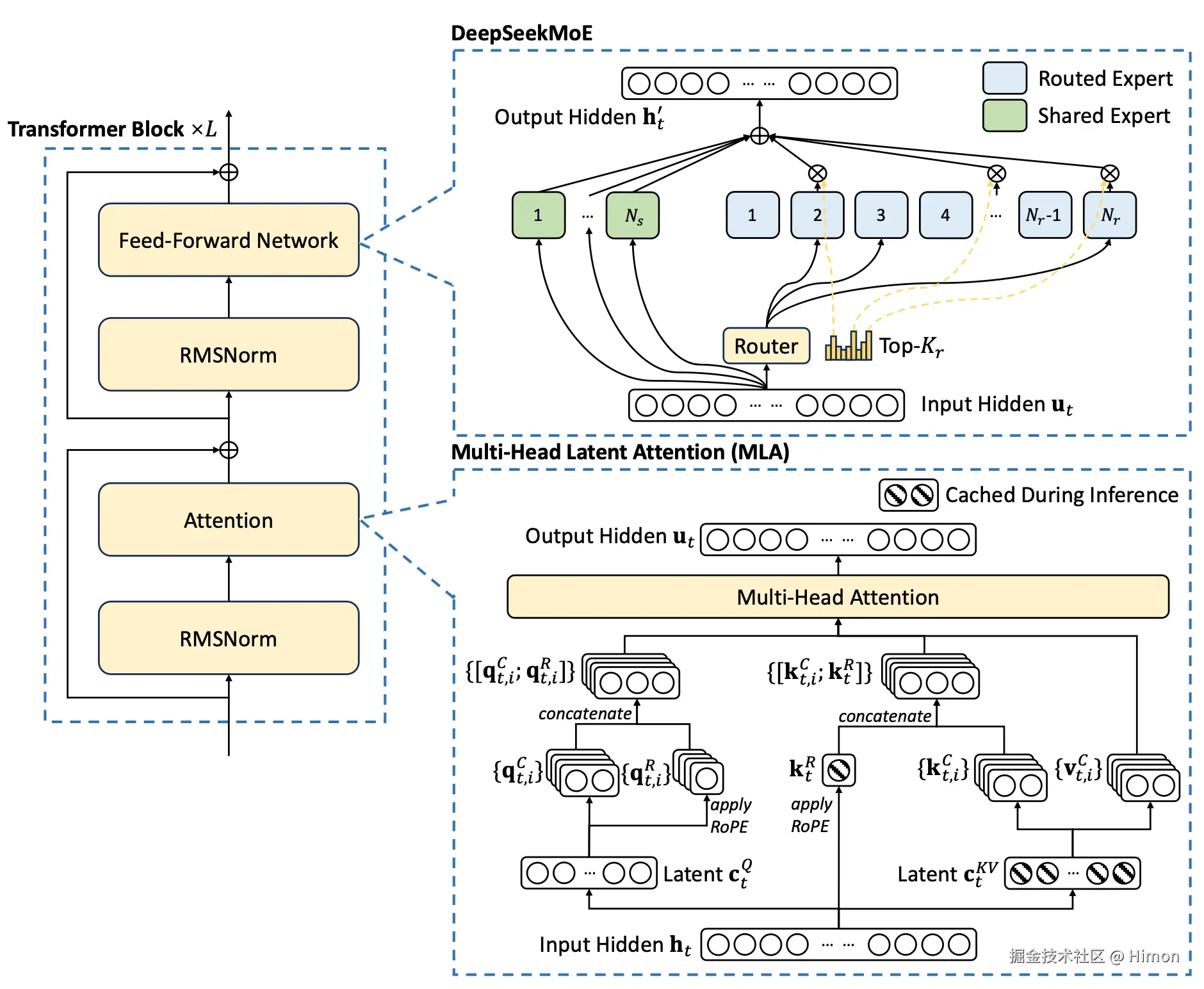
DeepSeekMoE-V3:
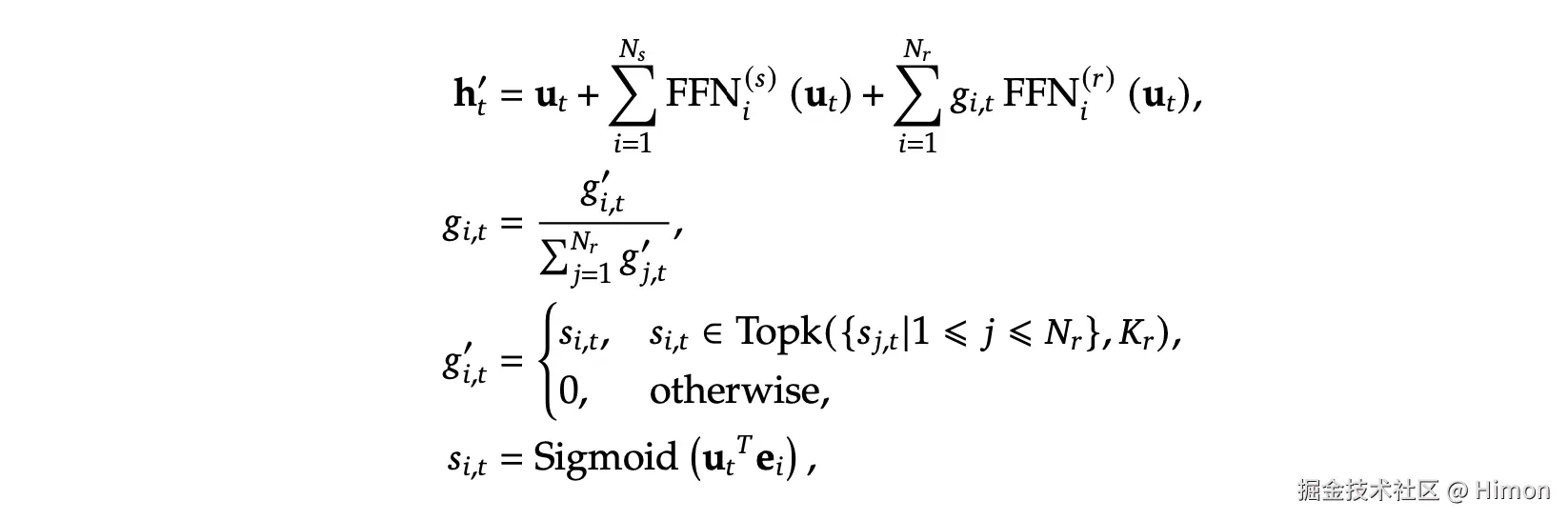
Multi-Token Prediction (MTP) training objective:
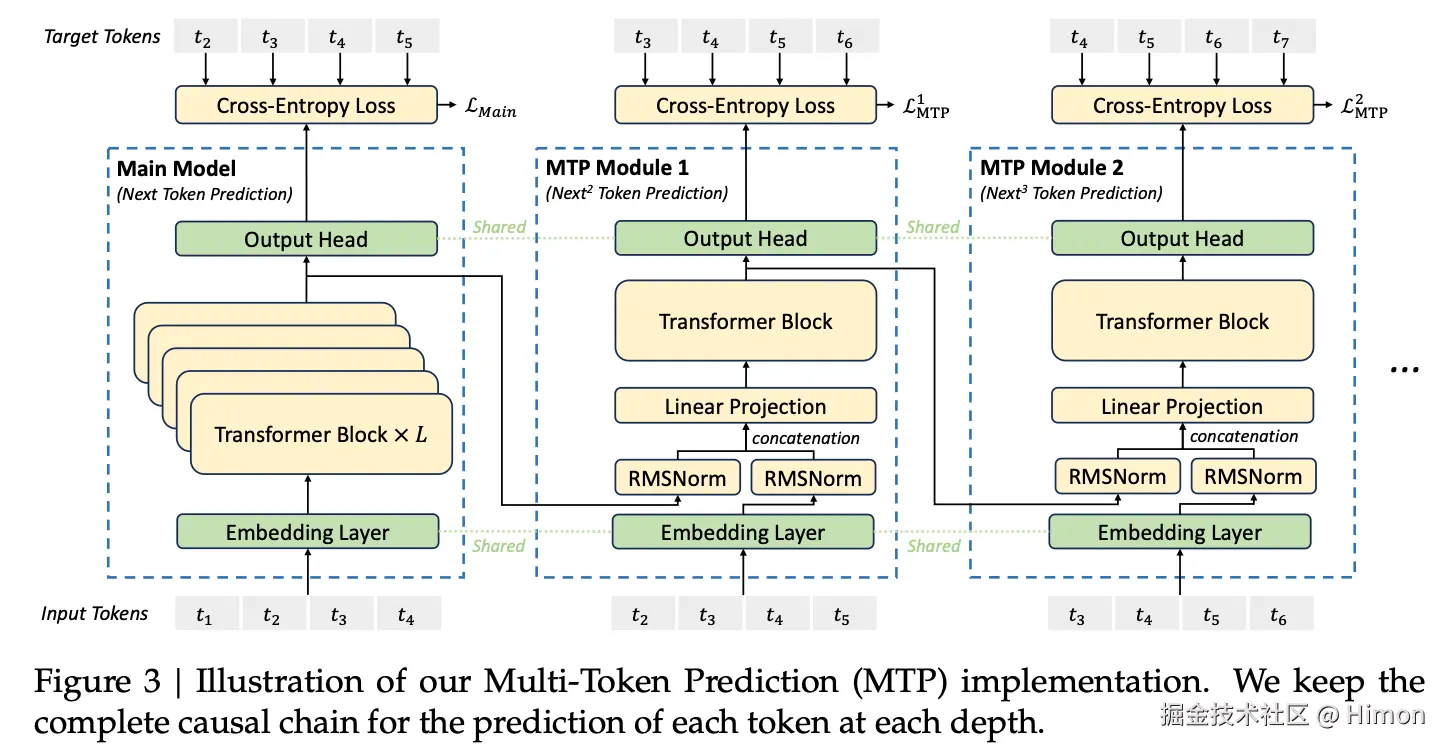
核心思路:多token预测,让模型在训练的时候,一次性预测多个未来token,一次性学习多个位置的label。
训练执行步骤:
主模型和草稿模型共享Embedding层和Output Head层(输出预测logit)。
k时刻草稿模型输入特征向量:将k-i时刻主模型Head层前面的特征向量+RMSNorm,将k时刻token经过共享的Embedding层得到词向量+RMSNorm,将两部分concat起来,过一层Linear降维。
草稿模型预测:输入Transformer得到输出特征向量,过共享的Output Head层得到token的预测概率。
训练草稿模型:采用交叉熵,采用典型的Teacher forcing模式训练草稿模型。
预测执行步骤:
草稿模型预测:草稿模型利用k个Head生成k个token。原始模型校验:将原始序列+预测序列拼接给原始模型校验接受:选择原始模型预测token与草稿模型预测token一致的序列作为接受的序列。(自回归计算中,主要时间在加载模型,每次生成一个token和n个token时间几乎一样)。
参考:
Multi-Head Latent Attention (MLA) 详细介绍MTP:让LLM一次性预测多个token
DeepSeek-R1
GPPO:
参考:
全网首篇从tensorRT-LLM MoE CUDA kernel角度理解Mixtral-8x7b的推理加速及展望混合专家模型 (MoE) 详解Mixtral Moe代码解读_moe 代码-CSDN博客一文带你看清Mixtral内部结构及参数计算 翟泽鹏图解大模型训练系列之:DeepSpeed-Megatron MoE并行训练(原理篇)用通俗易懂的方式讲解大模型分布式训练并行技术:MOE并行_如何训练moe大模型-CSDN博客moe使用负载均衡的意义仅仅是为了方便训练吗?混合专家模型 (MoE) 详解
scaling law

