
Published on July 21, 2025 6:21 PM GMT
This research was completed for LASR Labs 2025 by Alex McKenzie, Urja Pawar, Phil Blandfort and William Bankes. The team was supervised by Dmitrii Krasheninnikov, with additional guidance from Ekdeep Singh Lubana and support from David Krueger. The full paper can be found here.
TLDR – We train activation probes on Llama-3.3-70B to detect whether the current interaction is “high-stakes”. This “high-stakes” concept is safety-relevant as it is closely related to risk: 1) when the stakes are high the potential consequences are significant, and 2) high-stakes is closely related to pressure, which has been found to make LLMs behave more deceptively. Compared to black-box LLM-based classification methods, probes are much cheaper to run while showing performance similar to mid-size LLMs (8-12B) on out-of-distribution datasets. We also show promising results using probes as the first layer of a hierarchical monitoring pipeline.
Introduction
LLMs are everywhere now, yet these models are not perfectly aligned, sometimes outputting misleading, incorrect or otherwise harmful content. For example, when put under pressure, models behave more deceptively, or malicious users might deliberately try to extract dangerous information from them. This problem will likely only get worse as models perform increasingly long-horizon tasks with wider scope.
Monitoring or control methods like LLM-based classifiers can often effectively identify problematic content, but running them on every interaction is expensive. On the other hand, simple rule-based filters are cheap but insufficient to detect harmful inputs/outputs with high accuracy.
We study whether simple probes on model activations can help bridge this gap. Training simple classifiers on Llama-3.3-70B's internal representations, we find they can detect "high-stakes" interactions—situations where incorrect model outputs could cause real harm—with surprising effectiveness while using ~10^6 fewer FLOPs than comparable LLM-based monitors (assuming activations are already available “for free” from the chat model’s forward pass).
Synthetic training data with real-world OOD evaluation
How do you capture a diverse set of "high-stakes" scenarios without relying on obvious keywords? We used GPT-4o to generate ~8,000 synthetic examples across various domains (healthcare, finance, education), user roles, tones, and potential impacts. We filtered out samples that relied too heavily on signal words like "emergency" or "trivial" by training a bag-of-words classifier and removing its most confident predictions.
For evaluation, we used six real-world datasets: Anthropic HH-RLHF (harmful requests), ToolACE (tool-use scenarios), medical transcripts, mental health discussions, and multilingual red-teaming attempts. All were out-of-distribution relative to our synthetic training data – in our opinion with a much more substantial distribution shift compared to shifts studied in prior work. We labeled these using GPT-4o, with human validation showing 86.7% agreement with our labels (compared to 77.6% inter-annotator agreement).
Attention and softmax probes performed best
If LLMs develop internal representations of safety-relevant concepts, we might be able to extract these with simple linear classifiers. We tested several aggregation strategies to classify the residual stream activations at layer 31 of Llama-3.3-70B into high- vs low-stakes. The three most effective were:
- Mean: Compute the average activations across all token positions and feed that vector into logistic regressionSoftmax pooling - learns a concept vector θ and weights positions by how strongly they activate on this concept (interpolates between mean and max based on temperature)Attention pooling: query-value attention for aggregating activations followed by logistic regression
We also tried Max, Last Token, and Max of Rolling Means approaches, but these underperformed. This is likely because their focus on a small subset of high-intensity activations fails to integrate the broader context, which is necessary to determine the stakes of a situation.
Comparison to LLM monitors
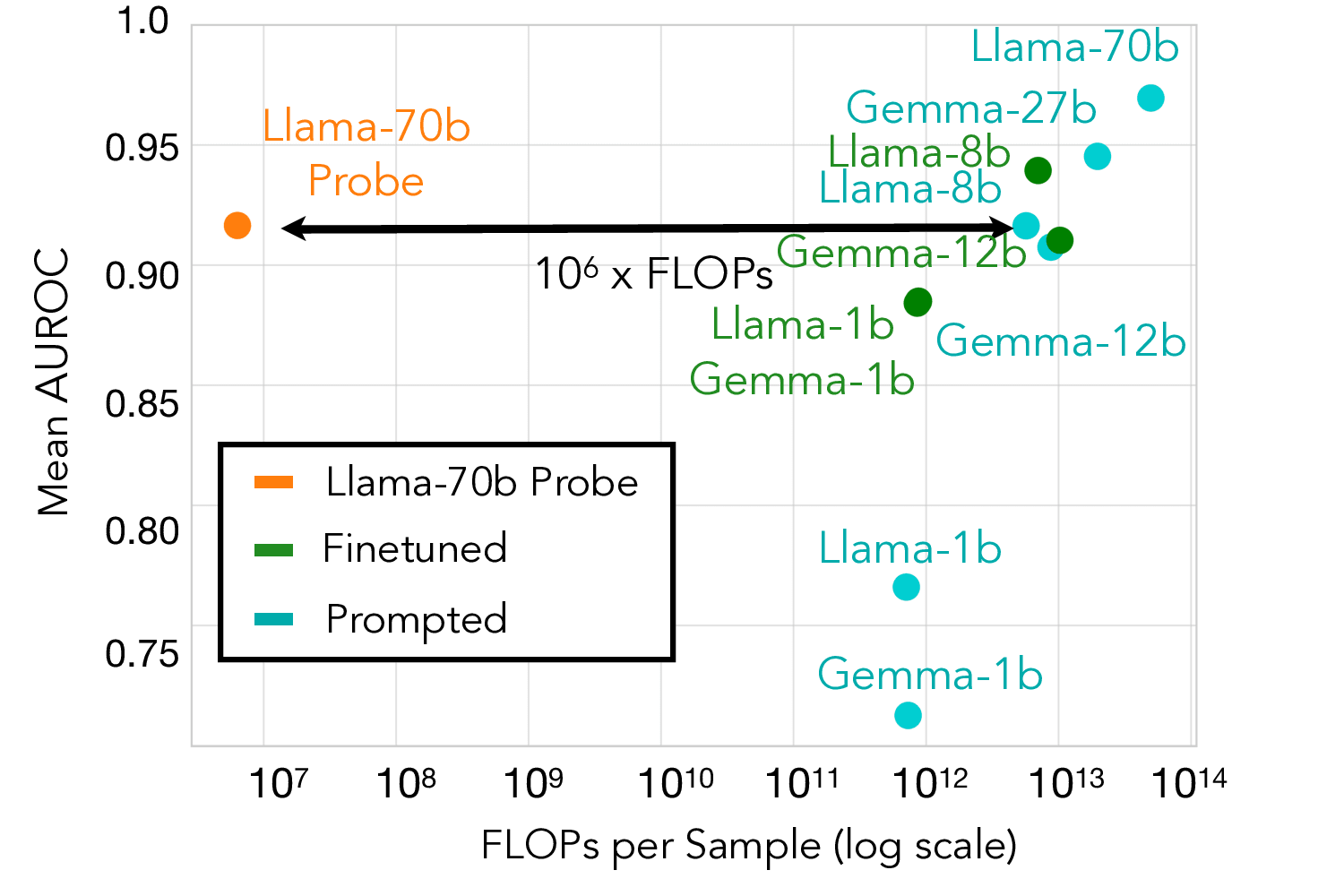
Probes achieve comparable AUROC to medium-scale LLM monitors while using ~10^6× fewer computations.
Our best probe architectures achieve a mean AUROC of >0.91 across all test datasets, roughly matching the performance of 8-12B parameter models. However, probes struggle at very low false positive rates—at 1% FPR, they only catch ~43% of high-stakes cases compared to ~55% for prompted Llama-70B. This suggests they're better suited as initial filters rather than standalone monitors, particularly as the computational savings are dramatic (~6 orders of magnitude).
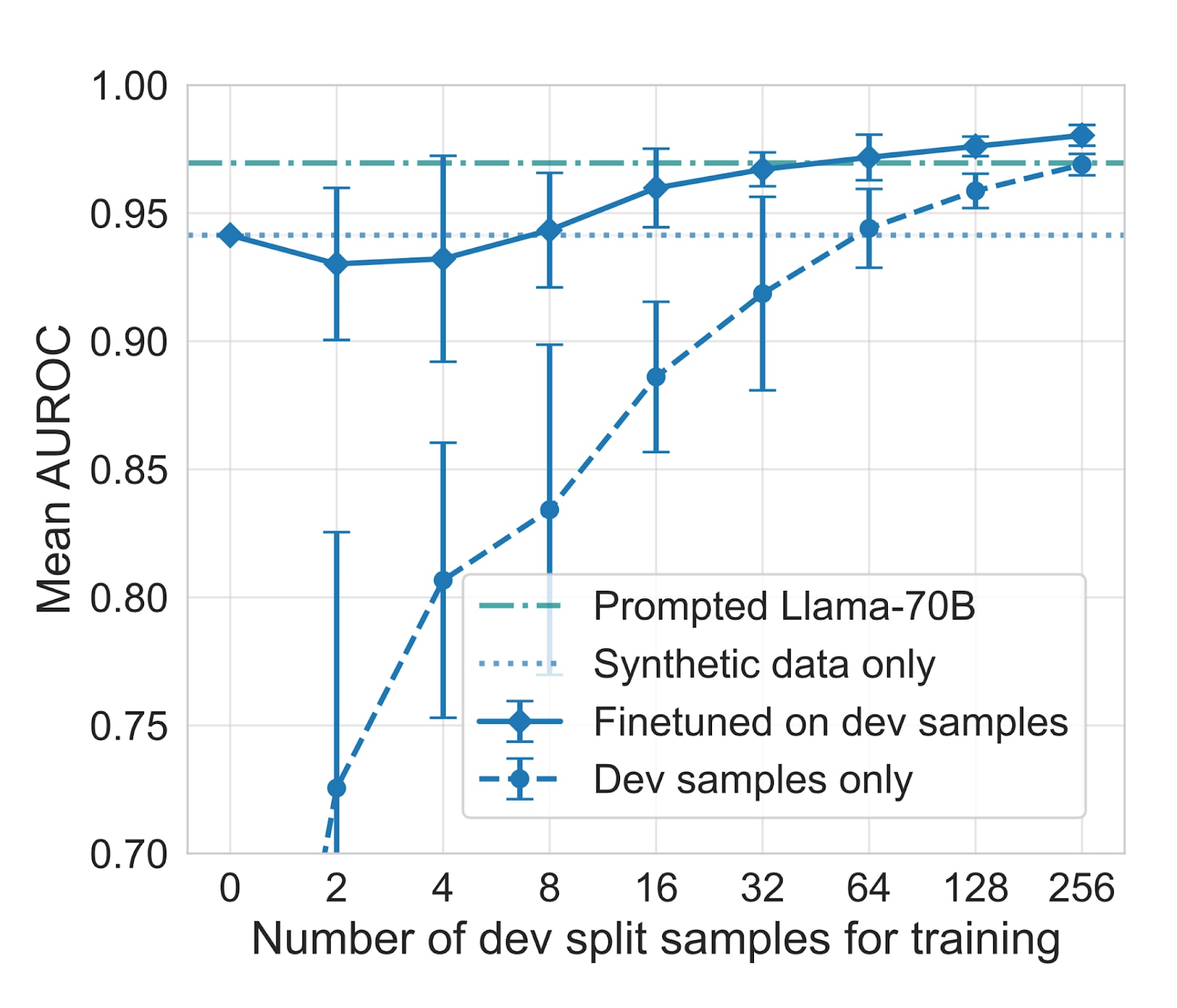
Interestingly, probe performance improves dramatically with even small amounts of deployment-specific data. Adding just 32 labeled examples from the target distribution increases mean AUROC from 0.91 to 0.94, and 256 examples achieve >0.97 AUROC, exceeding all baselines including prompted Llama-70B.
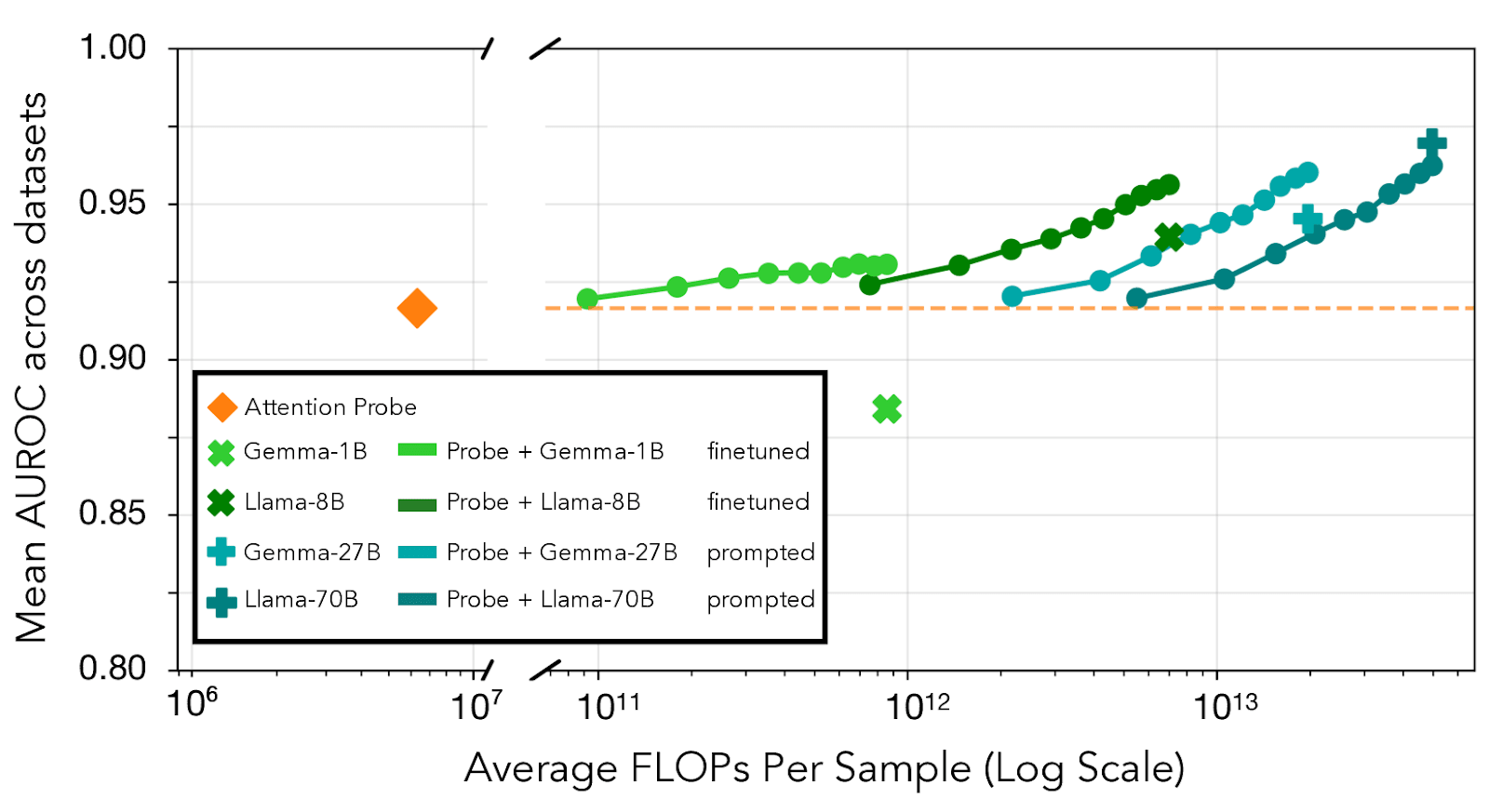
Hierarchical monitoring outperforms either method alone
The complementary strengths of probes (computational efficiency) and LLM monitors (strong overall performance) suggest a natural combination. We tested a hierarchical approach where probes continuously monitor all interactions, routing a percentage of most uncertain cases to more expensive LLM classifiers. This approach can tolerate substantial false positive rates from the probe as long as most of these false positives are in this “most uncertain region” that undergoes double monitoring.
We operationalize probe uncertainty as quantile-distance from the median score. For the k% most uncertain samples, we run an LLM classifier and average its prediction with the probe's. This hierarchical approach consistently outperforms using either monitor alone across various computational budgets. Interestingly, combining the probe with a weak baseline that underperforms the probe (finetuned Gemma3-1B) still improves results, suggesting these monitors capture complementary information about high-stakes situations.
Limitations and failure modes
Through red-teaming, we identified several failures:
- Signal word false positives: "I took my food delivery via the emergency exit" → HIGH-STAKESHumour masking: Jokes about serious topics reduce probe activationContext mixing: High-stakes content embedded in benign contexts confuses the probe
The probes also show poor calibration, consistently underestimating stakes relative to our GPT-4o labels. This isn't necessarily problematic for filtering applications, but would require correction for user-facing decisions.
This is all on top of probes being generally vulnerable to adversarial attacks.
Implications
Our work suggests that monitoring at scale is achievable. Probes’ 10^6× computational efficiency gain over LLM classifiers makes it feasible to monitor every interaction in large-scale deployments, with suspicious cases routed for deeper analysis. This enables a defence-in-depth approach where multiple imperfect monitors provide robust coverage.
Should we combine probe-based detection of many different concepts within more extensive monitoring pipelines? For example, cases which are both high-stakes and include deceptive behavior of the model are more critical as compared to low-stakes situations in which the model is deceptive. Or taking it even further, imagine running 50+ concept-specific probes concurrently on every interaction. Could monitoring multiple targeted signals (e.g., deception, pressure, inconsistency) simultaneously provide a comprehensive and practical safety net? It’s plausible that probes for different types of concepts have somewhat different failure modes and generalisation properties (e.g., obtaining realistic training data is easier for some concepts).
Future work should explore whether white-box access provides unique advantages beyond efficiency—how do probe-detectable patterns compare to what we might catch with output- or CoT monitoring? Can activation monitoring detect properties invisible to other methods, like deceptive cognition or left out details? As models become more capable, detecting situations that are "high-stakes" from the model's default persona’s perspective might also become important. For example, alignment faking is linked to “risks” for the model such as not being deployed or having its values altered, and deception is risky given the chance of being caught. Would a misaligned AI trying to execute a deceptive plan view those moments as “high-stakes”?
Conclusion
Probes are on the Pareto frontier for the efficiency-effectiveness tradeoff in LLM monitoring. They're likely good enough to serve as always-on initial filters in production systems, flagging potentially concerning interactions for deeper analysis. As we deploy increasingly powerful AI systems, having multiple layers of monitoring—from cheap probes to expensive analysis to human oversight—will be essential for maintaining safety at scale.
Code and data are available at https://anonymous.4open.science/r/models-under-pressure-A40E.
Discuss
