
Published on July 20, 2025 11:46 PM GMT
Epistemic status: This post synthesizes 1.5 years of research insights supported by the Long-Term Future Fund. Parts are higher context (comparisons with hardened AIXI and joint AIXI) but you don't actually need much math to follow - in particular this post pretty much uses reflective oracles as a black box, and everything else has short inferential distance assuming basic familiarity with AIXI and reinforcement learning. Most readers should skip the highly compressed technical summary below - the rest of the post is pretty friendly, except the proof of the theorem.
Highly compressed technical summary [NOT intended to be widely legible]: A preliminary investigation of action evidential decision theory with respect to reflective oracle Solomonoff induction on the joint action/percept sequence shows that it solves some problems of ideal embedded agency and mimics Bayes-optimal sequential planning under a self-trust assumption.
AIXI is not an embedded agent. It interacts with its environment from the outside, like this:

The red arrows indicate that the environment sends AIXI percepts and AIXI sends the environment actions. This is the only way they affect each other.
I stole the picture from this great (but long) post of Garrabrant and Demski. A shorter (and slightly more formal) version is this paper on realistic world models from Soares. Since all of these individuals have been or are currently MIRI researchers, I'll lump their views together as the views of (typical) MIRI researchers.
In their work, MIRI researchers pointed out various ways that AIXI's assumption causes it to fall short of a complete mathematical model for artificial superintelligence (ASI). For instance, AIXI can't natively reason about the environment changing its source code (your video game will not reach out of the console and perform brain surgery on you). Also, AIXI is computationally unbounded, but a real agent running on a computer has computational bounds - and since its computational substrate is strictly smaller than (and contained in) the environment, it presumably can't compute everything that is happening in the environment. [1]
I'm an AIXI enthusiast, so I wanted to investigate these limitations more rigorously. I've argued for this approach in the past: since AIXI is kind of a common point of departure for many agent foundations agendas, it seems worth understanding it well.
Before getting into the details though, I think it's worth observing that MIRI researchers are setting a very high bar here. A rigorous theory of embedded agency would be a rigorous theory of ASI design - it would basically have to solve everything except alignment, which would hopefully be a corollary. Specifically, computational boundedness is very hard - it asks for an agent that actually runs efficiently. Stuart Russell has phrased the AI problem in terms of bounded rationality. It seems like a complete solution must be something like an optimal program for your physical machine (or better, programs for machines of every size). Even an approximate solution seems to solve AI in practice. Again, that's a lot to ask.
Prospects for a theory of bounded rationality
I no longer believe (or rather, I newly disbelieve) that the theory of AIXI can directly address the problems related to bounded rationality. AIXI just isn't computationally bounded, which means that it would not need to think about using bounded cognitive resources or taking advantage of external computation like calculators or scratchpads.[2] I initially tried to think of some meta-cognitive AIXI sending a few bits of advice to a lower-level bounded reasoning engine, but ultimately AIXI-level compute seems to just be too powerful and I think there's not much of interest to say here. Studying AIXI approximations may yield progress though - that's sort of how the model is intended to be used after all.
Existing agent foundations research directions try to tackle computational bounds by studying computational uncertainty (that is, uncertainty about the results of computations). Roughly speaking, there are two approaches to this: try to put probabilities on uncertain computational statements or don't. UDT falls in the former group and IB falls in the later. A proper approach to UDT seems to go through much of computational complexity theory, so I think it will be hard to find (the current SOTA proposals boast of beating all polynomial time heuristics, but are unfortunately exponential time themselves). IB seems more promising the more I look into it - it is basically trying to invent algorithms with provably good properties, which is a sort of frequentist approach. However, I suspect that relying on this kind of tinkering means it may be hard to demonstrate you have a good model of ASI (which could have tinkered further than you!) unless you're only trying to model the ASI you actually built - and then you have to push the theory far enough to get a blueprint for (safe) ASI.
I'm interested in the easier (?) problem: how should a computationally unbounded embedded agent act?[3]
It's not a priori obvious that this a well-defined question. All agents embedded in a computationally bounded universe must be computationally bounded themselves, so we risk constructing a "theory of nothing." We can of course take the limit of increasing compute, but the result may be path dependent - it might matter how compute scales differentially across the agent/environment system.
On the other hand, it seems like some problems of embeddedness really have nothing to do with computational bounds. For instance, the possibility that the environment might corrupt your source code seems to have more to do with side-channels than computational bounds. Some forms of anthropic and evidential reasoning seem to fall into the same category.
In previous work, I've created some formal frameworks to talk about aspects of embedded agency. These include evidential learning from one's own actions and robustness to side-channel corruption. In this post, I want to investigate how a reflective oracles handle these problems. This leads to the construction of a reflective AIXI generalization which I think combines the virtues of some of my previous ideas (actually, in many cases, Marcus Hutter's ideas which I formalized). This agent follows sequential evidential decision theory (SAEDT) with respect to reflective oracle Solomonoff induction (rOSI) as joint action/percept history distribution.[4] For short, I'll call this agent self-reflective AIXI (which turns out to respect previous terminology - conveniently, it combines ideas from Self-AIXI and reflective AIXI). Next I'll discuss prospects for alignment applications and further development of this theory.
I don't think there's much novel math here, and none of it is deep - at least when you factor out the existence of reflective oracles. I'm mostly trying to tie my thinking together into a cohesive research program.
Standard Notation
: the empty string
, : (small) positive numbers, NOT the same as
: discount factor at time , a positive number.
: tail some of discount factors
: the action-value function for policy and environment
: the (state) value function for policy and environment
Loosening the Dualistic Assumption
That picture I opened with (of AIXI playing a video game) accurately describes its "ontology." AIXI really believes that the environment is a (Probabilistic Turing) machine that it can (only) exchange messages with. Specifically, action is sent at time , and then percept is received (where is an observation and is a reward). That means AIXI "only does Solomonoff induction on the percepts" with the actions as an additional input. Marcus Hutter made this formal by defining "chronological semimeasures," so in a sense AIXI does "Solomonoff-Hutter" induction, rather than ordinary Solomonoff induction. This is basically the move that MIRI objects to most loudly.
We can write to describe a belief distribution that treats actions as received on such a distinguished input channel (or "tape") and then randomly generates the percepts. AIXI uses a Bayesian mixture of this form, the universal lower semicomputable chronological semimeasure . Chronological means the actions and percepts are exchanged in the right order. You don't need to know what the rest of those words mean to understand this post.
Years ago, when I first started working with Professor Hutter, I convinced myself that I had brilliantly solved this problem - just do Solomonoff induction on the whole sequence, including actions and observations!
You can totally do this! But it causes other problems - it's a worse theory of intelligence.
First of all, it's not so clear how planning should work any more.
Do you even plan ahead? If so, do you update in advance on all the actions you plan to take? This paper formalizes two approaches to planning ahead in evidential decision theory.
Since we are treating our future actions as uncertain, I think it is more natural to plan only one step ahead (what I call action evidential decision theory as opposed to the previous paper's sequential action evidential decision theory).
where
A similar approach is advocated by the Self-AIXI paper, which we will return to later.
Either way, the problem is that the action sequence is no longer computable (or even lower semicomputable). AIXI is too smart for AIXI to be able to understand it - so we can't guarantee that it ever learns to predict the future.
Actually, this isn't trivially obvious, since predicting only the percepts might be good enough for the sequential planning approach (which intervenes on the actions anyway), and the percepts are still (lower semi)computable as a function of the actions, loosely speaking. I wrote a paper with Marcus Hutter about the resulting (potential for) convergence failure, and it can occur under sufficiently unfortunate action choices (though we don't know whether AIXI actually takes these unfortunate actions). However, a weak positive convergence result can be proven by renormalizing the universal distribution. Clearly the situation is messy - it seems MIRI had a point about this one.
Adding a reflective oracle completely solves this problem - when is chosen as rOSI, the resulting is reflective oracle computable (rO-computable) by essentially the same trick used to construct reflective AIXI. This means that ordinary merging-of-opinions results apply.
What do we get out of this approach? Well, learning about the environment from our own actions seems useful. For instance, it should effect the agent's behavior in games against copies of itself - other agents known to have the same source code. Here we would probably want to use a specially chosen "cooperative" reflective oracle. I haven't studied this yet. Another question I am interested in is "what actually happens if such an agent reads its own source code?" Presumably it would become certain of its future decisions, which seems to mean conditioning on impossible counterfactuals (another complaint of MIRI). A direct answer is that is not possible for this to actually cause a divide-by-zero error because rOSI never assigns 0 probability to any (finite) action/percept history. Still, it seems worth investigating what happens when certain action probabilities are driven very close to zero through the learning process (an as-yet under-specified open problem).
Evidential learning seems to be the main "advantage" when sequential planning is used, but we chose one-step-ahead planning for an additional advantage: it doesn't assume that we will control all of our future actions.
Radiation Hardening AIXI
One of the examples in Soares' critique of AIXI is the "Heating Up" game:
The Heating Up game. An agent A faces a box containing prizes. The box is designed to allow only one prize per agent, and A may execute the action P to take a single prize. However, there is a way to exploit the box, cracking it open and allowing A to take all ten prizes. A can attempt to do this by executing the action X. However, this procedure is computationally very expensive: it requires reversing a hash. The box has a simple mechanism to prevent this exploitation: it has a thermometer, and if it detects too much heat emanating from the agent, it
self-destructs, destroying all its prizes.
He argues that AIXI is not equipped to solve this problem, because it does not understand itself as computed by a piece of hardware, so can never conceive of the possibility that thinking for longer might cause it to heat up. I think this example is not very good. Insofar as an AIXI approximation controls which computations are running on its hardware, it will absolutely learn any correlates of this in the environment. If the AIXI approximation doesn't control how its compute is used then it kind of faces an unfair problem here - but it will still be able to predict that it will heat up in this situation, given some experience of similar situations. The details depend on where you put the boundary around the thing you treat as an AIXI approximation.
Anyway, I suggest an improved version of this example where heating up actually overheats the AIXI approximation's hardware, so that it takes unintended decisions. In this case, AIXI really wouldn't learn to predict this, because it does not predict its own decisions, it plans them.[5]
A simpler version (suggested by Samuel Alexander) is a robot designed to clean up a nuclear disaster site. Some rooms might have high levels of radiation, which could flip bits and cause the robot to misbehave. Naively, AIXI would never learn this - it would keep going back into the room planning to "just behave properly" this time.
Previously, I formalized this by adding an action corruption function which may depend on both the past/present actions and the past/present percepts. Then I proposed a variation on AIXI (invented by myself and Professor Hutter) which recalculates its own "true" action history at every step, and is able to "externalize" action corruption. I now call this "hardened AIXI" after radiation hardening.
Here is the post - the rest of this section is easier to understand if you've read it.
How does self-reflective AIXI deal with action corruption? I would argue pretty well. Technically the argmax over is only what we want when our agent actually gets to pick its current action. That means doesn't handle adversarial action relabeling in the way that hardened AIXI does: if always swaps and , and wants to take , it just selects . But this seems like a fairly reasonable answer: the point of a decision theory is to tell us which action we want to take, if we have control. is telling us the result it wants "after corruption." But otherwise it natively handles the situation without adding a hardening patch, which is nice. Below I'll be a little more formal about this.
Some contrived examples. Assume that the environment , policy , and action corruption function are all rO-computable. Then the situation is realizable and (the reflective) learns correct prediction on-policy. If we assume also that always has some fixed chance of selecting any action[6] then we even have
Setting , this means that in the limit selects an -optimal action! However, technically the "external" policy we care about is which does the true action selection. Intuitively, it seems that is properly satisfying the Bellman equations "when is in control."
Here is a much stronger set of assumptions that makes this idea explicit:
Assume that there are two types of action corruption. In "out-of-control" situations, does not depend on at all. In "noisy" situations, just has a uniform chance of switching to some other action in the action space . Then takes the best action (accounting for corruption!) in noisy situations and trivially takes a best action (that is, any action) in out-of-control situations.
Convergence Under a Self-Trust Assumption
I am interested in understanding when self-reflective AIXI converges to AIXI. This is desirable roughly when the dualistic assumptions are actually satisfied (and the agent can be reasonably expected to learn this). This is one test for whether a theory of embedded agency makes any sense - it is the same test I applied to joint AIXI.
A similar convergence analysis was carried out (but not completed) for Self-AIXI, which is a minor variation on joint AIXI that maintains separate distributions over its own policy and the environment, drawn from hypothesis classes and environment class . This doesn't make much sense as a theory of embedded agency; it was actually motivated as a theoretical model of policy distillation.
We can describe it more formally as follows:
An environment distribution is given by:
with prior probability .
(Unlike the paper, I chose for this environment mixture to reserve for the universal distribution on the joint history.)
And a policy distribution is given by
with some prior probability .[7]
Note that and are updated separately, depending only on percepts and actions respectively. This is superficially different from joint AIXI.
Interestingly, there is actually little difference when the classes are taken as rO-computable mixtures. This is a nice "lego block" property of the rO-computability; an rO-machine is completed to a Markov kernel yielding conditional probabilities which you can just snap together to form a joint distribution.
Speaking more formally:
There is an rO-machine that uses for action symbols and for environment symbols, so the joint distribution (usually written) is rO-computable. This means that up to a constant factor (the prior probability of ).
Similarly, since is rO-computable, it's the case that
and similarly
Taking the product yields
Which yields
Observation 1: up to a constant factor.
In the reflective oracle setting, the difference between Self-AIXI's dualistic belief distribution and self-reflective AIXI's joint belief distribution is, in some sense, epistemic but not ontological, and it makes surprisingly little difference. It's essentially just an inductive bias. Or, in other words: Self-AIXI approximately learn that it is an embedded agent, and self-reflective AIXI can learn that it isn't!
Therefore my choice to use the joint distribution for self-reflective AIXI is not that important, but only a simplification (again, none of this is proven for ordinary AIXI, and in fact we proved a related negative result that the joint distribution restricted to the percepts does not dominate the universal chronological semimeasure).
Now we are prepared to discuss the convergence results in the Self-AIXI paper. The paper has some good ideas, but also some serious flaws and gaps:
1: It requires but demonstrates no such example. This can be easily fixed with reflective oracles, as I have informally described. Note that this fact pretty much screens off the other details of reflective oracles from the rest of my analysis - I'm actually coming to believe that the role of programs in AIT is mostly as a type of building block with sufficiently rich compositional / recursive structure to ease the construction of belief distributions with interesting properties, and this feature remains useful independently of any ontological commitments to a computable universe or even epistemological commitments to computable mindspace.
2: The paper introduces a technical assumption called "reasonable off-policy" which is inscrutable and essentially assumes the conclusion.
The follow example (suggested to me by Demski, though I believe it originates with someone else) illustrates how the "reasonable off-policy" assumption can fail:
Sink or swim. The agent wants to move from one island to another, but would much rather stay put than drown. Fortunately, the agent is an excellent swimmer and could easily swim to the other island if it jumped into the water. However, after jumping into the water, it could also choose to sink and drown.
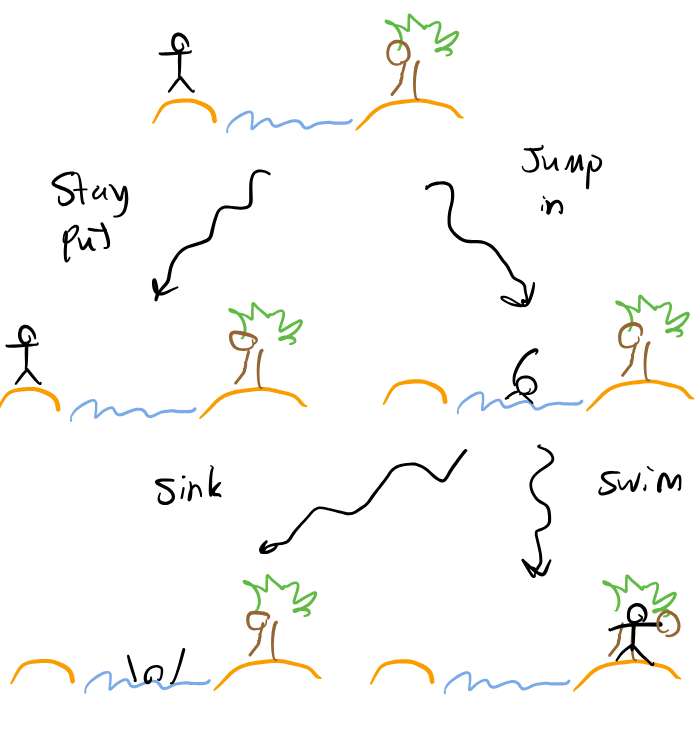
The answer seems obvious: jump in, and then swim to the next island. That is the optimal policy.
However, we have constructed an agent which is not certain it can trust itself to act as planned. This uncertainty may prevent the agent from jumping in and finding out that it will actually swim. A similar type of uncertainty blocking exploration is an obstacle for convergence in AIXI (or any Bayesian agent that believes the environment may contain inescapable traps). It just seems more jarring in this case because the agent could be built to trust itself by planning ahead sequentially - but that would prevent it from reasoning about action corruption through side-channels! There seem to be some inherent tradeoffs here.
The "reasonable off-policy" requirement (which I haven't reproduced here) basically encodes, in an obfuscated way, the knowledge that if you jump in you will actually swim, despite never having jumped in before.
Here is a much more transparent convergence result of the same flavor. Assume for simplicity that rewards are shifted and rescaled to [0,1]. The inspiration for this result is that when , then satisfies the Bellman equations for and can be shown optimal.[8] In fact, MIRI relied on this logic implicitly to construct reflective AIXI. Intuitively, this result should be "continuous in ," and it is, though I found this slightly harder to show than expected because of the self-referentiality involved - is actually discontinuous in because of the argmax. However, we can still show the result in two steps, by showing that takes an -optimal action for , and then showing that this means is actually -optimal itself.
For simplicity I will phrase the argument in terms of the value function at but it generalizes automatically to conditionals on a finite history prefix.
(As mentioned later, the proof is actually simpler if one uses Self-AIXI with and the correct given - and in that case, it is not necessary to assume deterministic)
Theorem 1 (-Self-Trust is -Optimal): Let the true environment be deterministic. For any , there exists a such that if , then is -(Bayes-)optimal for environment . If only one action is (Bayes-)optimal for at every time step and discounting is geometric, then remains -optimal at all times.
The significance of this result is that you don't need to directly assume you are (near)optimal. You just need to believe that you are probably doing action-evidential decision theory with rOSI. The result says that this consistent self knowledge is enough for near optimality: "If you are locally optimizing and expect to continue, you are nearly globally optimal." Importantly, this result doesn't require dogmatic Cartesian dualism: if it turns out that the environment sometimes corrupts its actions through side-channels, self-reflective AIXI can learn this (the inductive bias we built in can be washed out).
Let be the minimal time such that . I'll also assume that the sum of discounts is 1. The following lemma is designed to prove that the action chosen by is near-optimal for the optimal policy .
Lemma 1: Assuming that for ,
Proof: Let . By linearity,
But this is
We can expand the value function in terms of the max of another action-value function. Iterating to depth ,
Now we use the definition of to observe , and observe that all value functions are in [0,1]. This means we can substitute the optimal value function at a maximum cost of . Also, since is decreasing we can simplify the last fraction.
Okay, that could possibly have been cleaner, but Lemma 1 is proven.
Lemma 1 tells us that does not badly underestimate the value function. We actually need to know that does not badly overestimate the value function as well:
Lemma 2: Assuming that for ,
I brush the proof of this lemma under the rug. This case is more straightforward - as long as 's percept distribution is close to , no policy can outperform the optimal value function by much. I won't prove this explicitly - we can instead recite something about continuity of linear functional application. I assumed that is deterministic to ensure that never diverges from on percept bits. We can avoid this assumption by using Self-AIXI instead of self-reflective AIXI, and simply telling it the environment is .
Proof of theorem: We established at some effort that we can ensure each action is near optimal (for the optimal policy). Now we will find so that ensures that each action is within of optimal. This is slightly tedious; let is the minimum time satisfying . Given , we apply Lemma 1 to , then choose . This choice ensures that every action chosen by is -optimal. Finally,
Applying Lemmas 1 and 2 to the last pair of terms,
We can iterate by expanding the inner expectation. Repeating this process to depth , we obtain:
That is,
Finally.[9]
The basin of attraction. Now all that remains is to show that the conditions of Lemmas 1 and 2 can be maintained after updating. Informally, this is true as long as we can only receive a finite amount of evidence against at every step - in that case, a sufficiently large odds ratio for will remain above up to time . By assuming deterministic, we ensured that percepts never provide evidence against . The action chosen by are always of course consistent with , but it will randomize between equivalent options (this is the trick that makes it rO-computable). It is possible for this to provide about bits against in the worst case (under the standard construction for ), though in expectation of course predicts itself best. That is where the condition (needed for the stronger result that remains -optimal for all time) that only one action is Bayes-optimal for comes from. I assumed geometric discounting to ensure that does not depend on , which could probably throw things off. Interestingly, if there were always two Bayes-optimal actions for , the evidence against would be a kind of "-randomness deficiency," which is the reflective-oracle analogue of M.L. randomness deficiency. So, the theory of algorithmic randomness has a connection to the basin of attraction for self-trust! This is a little unexpected - proper algorithmic information theory doesn't seem to come up in the theory of AIXI as much as you would expect.
This concludes the proof.
Closing Thoughts and Future Work
It seems to me that MIRI wanted to be able to embed an agent's code inside a larger piece of code and evaluate its performance. When everything is an rO-machine, this is totally possible. These machines are like... flexible lego blocks. You can snap them together however you want, but Observation 1 suggests that updating treats whatever structure you build this way like a weak suggestion. This means that the resulting agents may not have very dogmatic beliefs. I am not sure whether this is good.
In this setting, self-trust has a "basin of attraction" which depends on non-dogmatically elevating the weight on a certain hypothesis. Playing with prior weights like this feels very clumsy. I think it would be nicer to build in knowledge through logical statements, perhaps using Hutter et al.'s (uncomputable) method for assigning probabilities to logical statements. If I understand correctly, this is vaguely related to the type of tiling properties Demski and his collaborators study in the computationally bounded setting using UDT. I am not satisfied with the current versions of UDT (and as explained above, I think there are good reasons to expect it is very hard to find a satisfactory theory of computational uncertainty). But of course rO-computability is not realistic and eventually we must move beyond this idealized setting.
I think reflective oracles are a reasonable model for agents of similar intelligence reasoning about each other or about agents of lower intelligence than themselves. This seems sufficient for modeling CIRL between idealized agents of equal power, which would be an interesting case to evaluate next.
- ^
I've written more extensively about these complaints in many places, particularly here - but as long as you can make sense of this high-level intuitive description, you probably know enough to understand the rest of this post.
- ^
Demski has called this the scratchpad problem, and is more or less solely responsible for convincing me of this point.
- ^
This is also the topic of Herrmann's PhD thesis, which is more philosophical and focused on action identification.
- ^
I realize this is a lot of jargon for one sentence. But I have to admit, there is something about uniting these ideas into something it would have been hard to formulate from scratch that I find pleasing. It makes the discussion feel more paradigmatic.
- ^
For AIXI, deliberation crowds out prediction.
- ^
I am smuggling in a free exploration rate, which causes merging-of-opinions to do what I want it to, so that Lemma 4.17 of Jan Leike's thesis remains applicable after action selection. Informally, this avoids a divide-by-zero.
- ^
The Self-AIXI paper is inconsistent about whether the policy distribution should be updated on the current action when comparing action-values. The intention seems to be to do so, and I follow this convention.
- ^
By expanding the value function in terms of the defining (arg)max's to arbitrary (finite) depth, we see the result dominates any finite-horizon value function, which can be shown equivalent to optimality at infinite horizon.
- ^
I have a feeling that someone better than me at measure theory (like Kosoy or Diffractor) could have done this proof so far backwards in heels and still taken half the lines.
Discuss
