
Published on July 13, 2025 6:40 PM GMT
I assume you are familiar with the METR paper: https://arxiv.org/abs/2503.14499
In case you aren't: the authors measured how long it takes a human to complete some task, then let LLMs do those tasks, and then calculated task length (in human time) such that LLMs can successfully complete those tasks 50%/80% of the time. Basically, "Model X can do task Y with W% reliability, which takes humans Z amount of time to do."
Interactive graph: https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
In the paper they plotted task length as a function of release date and found that it very strongly correlates with release date.
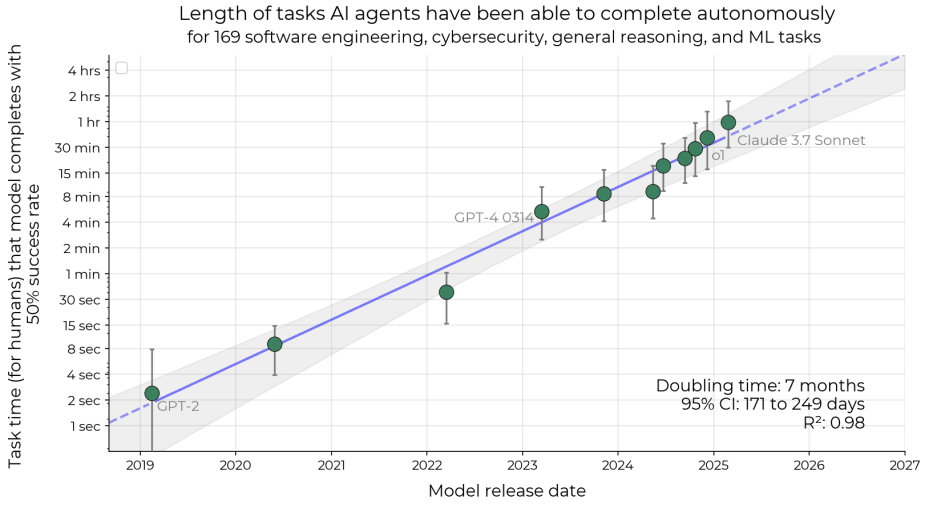
Note that for 80% reliability the slope is the same.
IMO this is by far the most useful paper for predicting AI timelines. However, I was upset that their analysis did not include compute. So I took task lengths from the interactive graph (50% reliability), and I took estimates of training compute from EpochAI: https://epoch.ai/data/notable-ai-models
Here is the result:
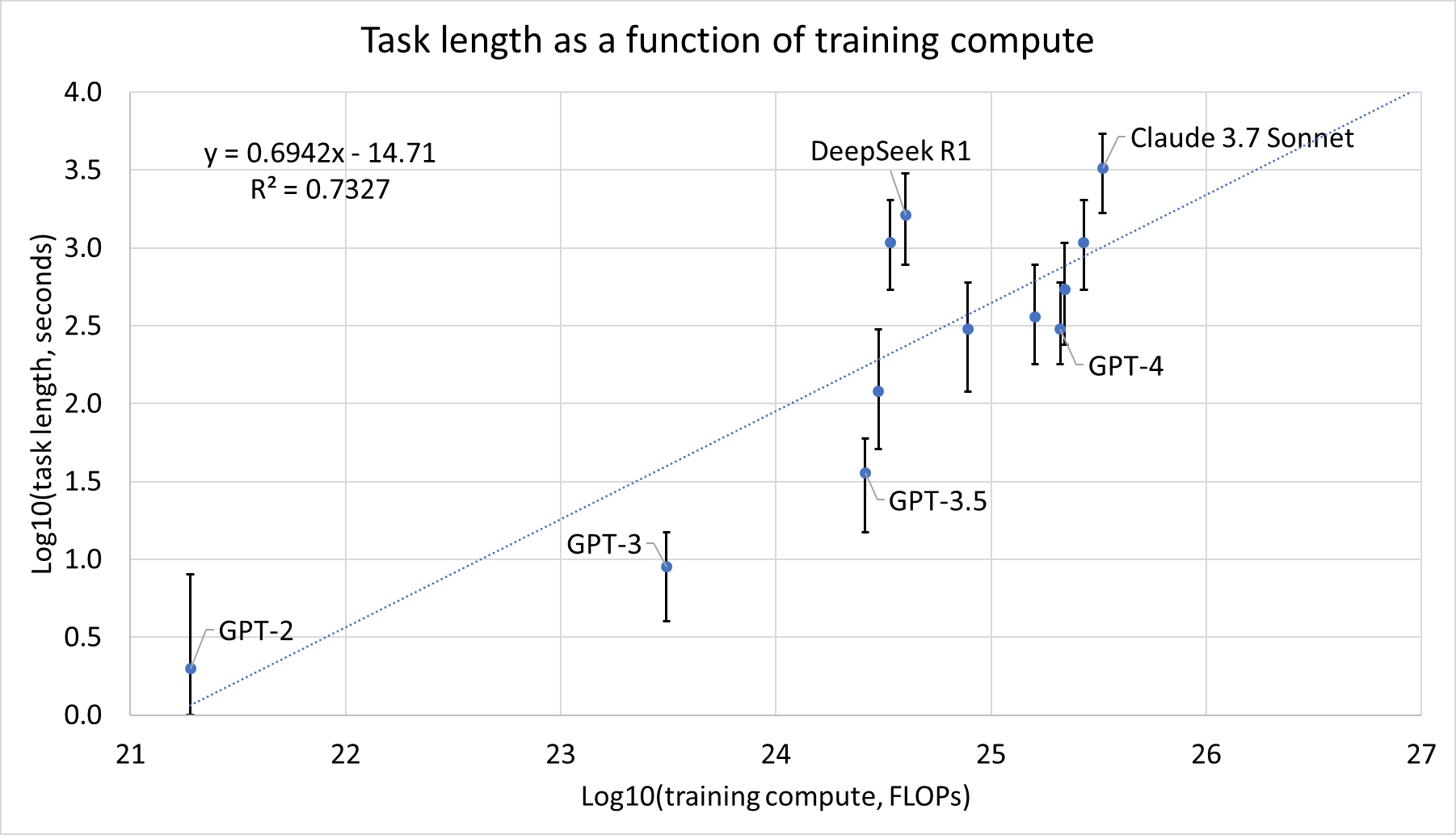
(I didn't add labels for every model because the graph would be too cluttered)
Increasing training compute by 10 times increases task length by 10^0.694≈5 times.
...well, kind of. This graph does not take into account improvements in algorithmic efficiency. For example, Qwen2 72B has been trained using roughly the same amount of compute as GPT-3.5, but has a much longer task length. Based on this data, I cannot disentangle improvements from more physical compute and improvements from tweaks to the Transformer architecture/training procedure. So it's more like "Increasing training compute by a factor of 10 while simultaneously increasing algorithmic efficiency by some unknown amount increases task length by a factor of 5."
Speculation time: at what task length would an AI be considered ASI? Well, let's say a "weak ASI" is one that can complete a task that takes a human 100 years (again, 50% reliability). And let's say a "strong ASI" is one that can complete a task that takes a human 5000 years; granted, at that point this way of measuring capabilities breaks down, but whatever.
To train the "weak ASI" you would need around 10^35 FLOPs. For the "strong ASI" you would need around 10^37 FLOPs.
Optimistically, 10^31 FLOPs is about as much as you can get if you buy 500,000 units of GB300 and train an LLM in FP8 at 90% utilization for 365 days nonstop. That would correspond to task length of around 2.5 months.
If these numbers are even remotely within the right ballpark, training ASI will be impossible without either software or hardware breakthroughs (such as photonic chips or analog devices for matrix multiplication) that break the current trend. If the current trend continues, then we won't see ASI for a looooooooong time.
Caveats:
- The fit is not very good, R^2=0.73. It's interesting that task length is better correlated with release date than with training compute; I was not expecting that.EpochAI lacks a lot of data on training compute, in particular data on o1, o3, Gemini 2.5 Pro and Flash, Claude 4 Opus and Sonnet. Conversely, METR lacks data on models such as Grok and Llama. More data points would be nice.
I would love if the authors of the METR paper did a similar analysis, but with more models. Maybe they could disentangle the benefits of increasing training compute from the benefits of improvements in algorithmic efficiency to get two independent numbers.
Discuss
