
大幅缓解LLM偏科,只需调整SFT训练集的组成。
本来不擅长coding的Llama 3.1-8B,代码能力明显提升。
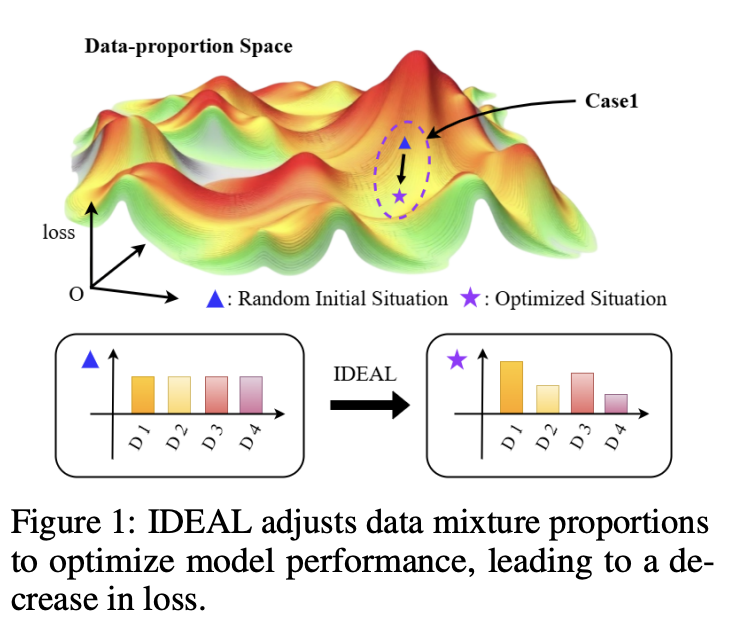
上海交大&上海AI Lab联合团队提出创新方法IDEAL,可显著提升LLM在多种不同领域上的综合性能。
此外,研究还有一些重要发现,比如:
具体来看——
SFT后LLM部分能力甚至退化
大型语言模型 (LLM) 凭借其强大的理解和逻辑推理能力,在多个领域展现了惊人的能力。除了模型参数量的增大,高质量的数据是公认的LLM性能提升最关键的影响因素。
当对模型进行监督微调(SFT)时,研究人员发现LLM在多任务场景下常出现“偏科”现象——部分能力突出而部分能力并未涨进,甚至退化。这种不平衡的现象导致大模型在不同的领域上能力不同,进而影响用户体验。
上海交大和上海AI Lab的研究者迅速将目光聚焦到SFT训练的训练集上,是否可以通过调整训练集的组成来缓解LLM偏科的情况?直觉上来看,直接将LLM的弱势科目的训练数据增加一倍,就可以让最后的结果发生变化。但是,由于训练数据之间的耦合关系,研究者通过建模量化每个领域数据对于最终结果的影响情况,科学地调整训练数据集的组成,最终提高了模型的。
IDEAL方法
问题建模:
首先按照不同的领域准备高质量的训练数据集: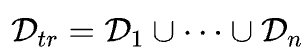 ,
,
并给出对应的用于验证的验证集:。通过在训练集上面训练模型θ,获得训练集上的最优参数:θ*。
论文希望在验证集上的损失达到最小。为了能够方便的调整训练集,论文引入了对应的变量β,并将这个优化问题显示地建模了出来:
高效计算:
由于式子中存在参数二阶矩阵的逆的操作,计算的资源消耗非常大。为了能够扩展到LLM的参数量级,论文采用了K-FAC的理论来近似简化计算Hessian矩阵的逆。通过挑选模型参数中的“重要”层的数值来近似刻画各个领域数据对于最后模型性能的影响,并最后通过合理的放缩超参数m来控制最后的调整比例大小:
整体的算法流程图如下所示:

实验结果
论文主要以Llama3.1 8B模型作为Base model,测试了IDEAL对四个典型领域上多任务训练的模型的提升效果。可以看到,无论是epoch1还是epoch3,IDEAL都能够在2轮迭代后将原先不擅长的Coding能力显著提升。
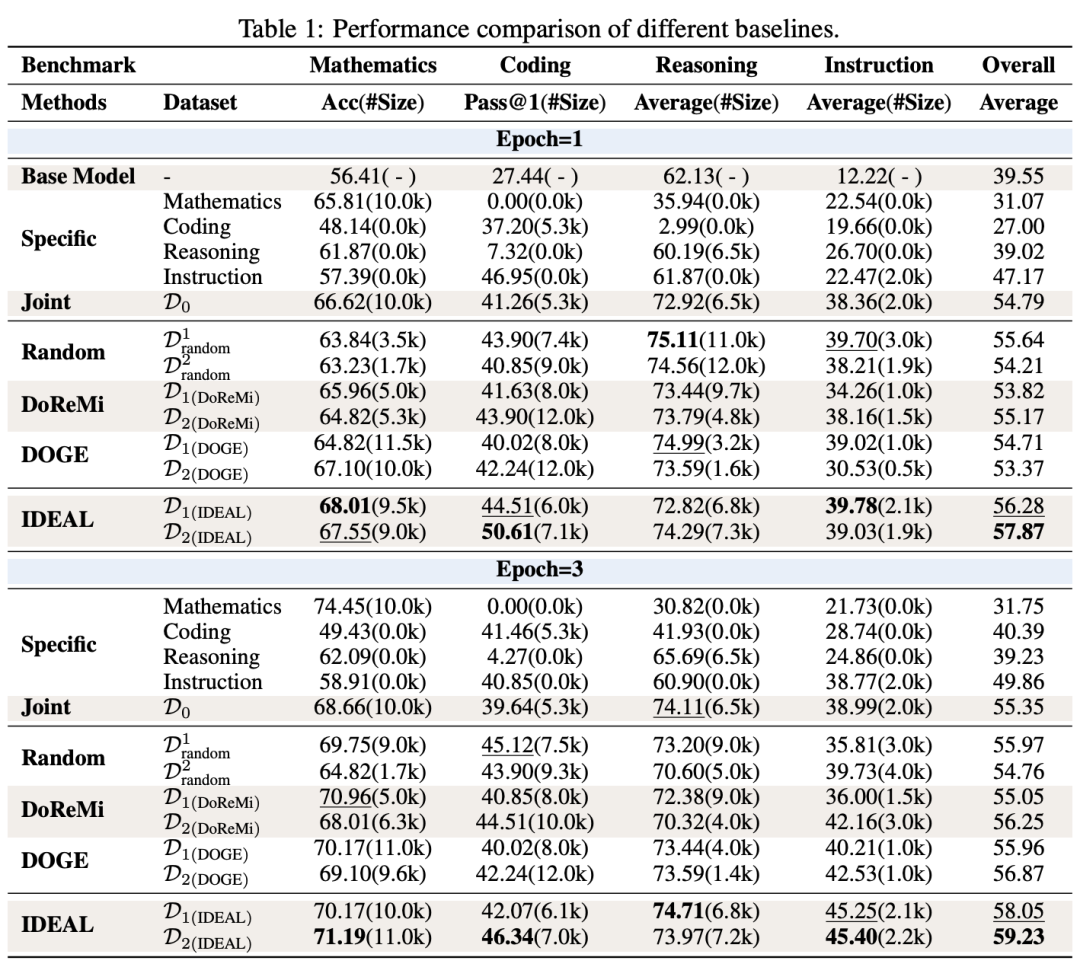
除此之外,论文还有其他的发现:
应用价值
IDEAL解决了得到各个领域高质量训练数据之后如何配比组合成为统一的训练集的问题。通过迭代优化的方式优化训练集的各个领域数据数量。避免了之前研究者需要按经验,人工调整各个数据集配比的dirty work,具有较大的实用价值。
论文信息:
标题:IDEAL: Data Equilibrium Adaptation for Multi-Capability Language Model Alignment
作者:上海交通大学、上海AI实验室、清华大学等
GitHub代码库:https://anonymous.4open.science/r/IDEAL-678C520/README.md
arxiv:https://arxiv.org/abs/2505.12762
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
