
Published on June 7, 2025 11:20 AM GMT
(This is cross-posted from my blog at https://grgv.xyz/blog/neurons1/. I'm looking for feedback: does it makes sense at all, and if there is any novelty. Also, if the folloup questions/directions make sense)
While applying logit attribution analysis to transformer outputs, I have noticed that in many cases the generated token can be attributed to the output of a single neuron.
One way to analyze neurons activations is to collect activations from a dataset of text snippets, like in “Exploring Llama-3-8B MLP Neurons” [1]. This does show that some of the neurons are strongly activated by a specific token from the model’s vocabulary, for example see the "Android" neuron: https://neuralblog.github.io/llama3-neurons/neuron_viewer.html#0,2
Another way to analyze neurons is to apply logit lens to the MLP weights, similar to “Analyzing Transformers in Embedding Space” [2], where model parameters are projected into the embedding space for interpretation.
Projecting neurons into vocabulary space
Let’s apply logit lens to a sample of MLP output weights for layer 13 of Llama-3.2-1B:
LLAMA_3_PATH = "meta-llama/Llama-3.2-1B-Instruct"model = HookedTransformer.from_pretrained(LLAMA_3_PATH, device="cuda", fold_ln=False, center_writing_weights=False, center_unembed=False)def get_distance_to_tokens(weights, n, max_dot, W_U, top_n=5, print_lens=False): for i in range(n): # over first 100 neuronsT layer_vec = weights[i] # [d_model] # Compute dot product with unembedding weights unembedded = torch.matmul(layer_vec, W_U) # [d_vocab] # Take absolute value to get strongest alignments, pos or neg abs_unembedded = unembedded.abs() # Get top-n tokens by absolute dot product s_abs, idx = abs_unembedded.topk(top_n, largest=True) results = [] for j in range(top_n): token = model.to_string(idx[j]) score = s_abs[0].item() results.append("{0:.3f} {1}".format(score, token)) if print_lens: print(i, results) max_dot.append(s_abs[0].item())block = 13weights = model.blocks[block].mlp.W_outget_distance_to_tokens(weights, 20, [], model.W_U, 5, True)0 ['0.080 hazi', '0.073 unders', '0.070 Lak', '0.069 OK', '0.068 igrants']1 ['0.107 orgia', '0.097 iy', '0.090 sian', '0.090 161', '0.088 ária']2 ['0.057 aph', '0.055 appen', '0.052 Essen', '0.052 usi', '0.052 чення']3 ['0.083 úp', '0.082 Sheets', '0.079 aida', '0.078 Wire', '0.077 omb']4 ['0.074 stein', '0.073 seed', '0.072 pea', '0.071 fib', '0.070 iverse']5 ['0.082 ieres', '0.082 iva', '0.079 agger', '0.079 mons', '0.078 ento']6 ['0.312 coming', '0.268 Coming', '0.246 Coming', '0.228 coming', '0.224 Up']7 ['0.076 Sent', '0.075 Killing', '0.073 Sent', '0.072 sent', '0.071 hek']8 ['0.161 es', '0.136 ths', '0.130 ums', '0.130 ues', '0.129 oks']9 ['0.206 St', '0.171 St', '0.170 st', '0.166 -st', '0.157 -St']10 ['0.101 utherland', '0.098 様', '0.087 arken', '0.087 utherford', '0.087 cha']11 ['0.078 ica', '0.076 statist', '0.075 arrivals', '0.073 ullet', '0.072 ural']12 ['0.081 nut', '0.080 �', '0.078 Doc', '0.076 zet', '0.075 Sparks']13 ['0.087 disconnected', '0.084 connection', '0.083 connect', '0.082 负', '0.081 disconnect']14 ['0.225 det', '0.214 det', '0.205 Det', '0.194 Det', '0.175 DET']15 ['0.192 for', '0.160 for', '0.140 For', '0.134 For', '0.129 FOR']16 ['0.107 wa', '0.087 /sub', '0.084 sub', '0.079 wa', '0.077 sub']17 ['0.075 inf', '0.074 subscript', '0.071 ोह', '0.070 sâu', '0.069 Lad']18 ['0.082 �', '0.082 endif', '0.077 subtract', '0.076 ola', '0.076 OLA']19 ['0.090 leh', '0.086 تص', '0.085 recher', '0.084 Labels', '0.080 abs']It’s easy to spot a pattern – some neurons are more closely aligned to a cluster of semantically-similar tokens, like:
6 ['0.312 coming', '0.268 Coming', '0.246 Coming', '0.228 coming', '0.224 Up']9 ['0.206 St', '0.171 St', '0.170 st', '0.166 -st', '0.157 -St']14 ['0.225 det', '0.214 det', '0.205 Det', '0.194 Det', '0.175 DET']Other neurons are much more random in terms of the proximity to vocabulary embeddings, equally dis-similar to various unrelated tokens:
0 ['0.080 hazi', '0.073 unders', '0.070 Lak', '0.069 OK', '0.068 igrants']3 ['0.083 úp', '0.082 Sheets', '0.079 aida', '0.078 Wire', '0.077 omb']19 ['0.090 leh', '0.086 تص', '0.085 recher', '0.084 Labels', '0.080 abs']Quantifying vocabulary alignment
Minimal distance (max dot product) to the embedding of a vocabulary token looks like a good measure of how vocabulary-aligned the neuron is.
In the previous example, this is the first number in each row:
0 ['0.080 hazi', '0.073 unders', '0.070 Lak', '0.069 OK', '0.068 igrants']1 ['0.107 orgia', '0.097 iy', '0.090 sian', '0.090 161', '0.088 ária']2 ['0.057 aph', '0.055 appen', '0.052 Essen', '0.052 usi', '0.052 чення']3 ['0.083 úp', '0.082 Sheets', '0.079 aida', '0.078 Wire', '0.077 omb']Plotting this values for all neurons of layer 13:
block = 13weights = model.blocks[block].mlp.W_outmax_dot = []get_distance_to_tokens(weights, weights.shape[0], max_dot, model.W_U)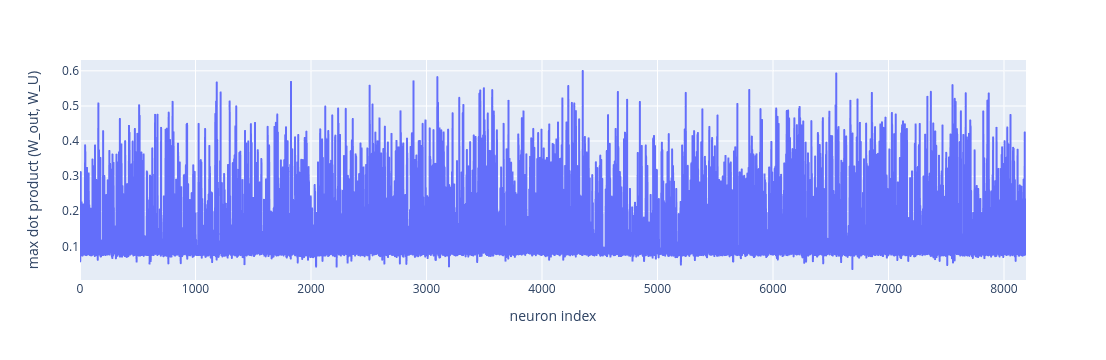
This plot is not very informative. Let’s look at the the distribution:
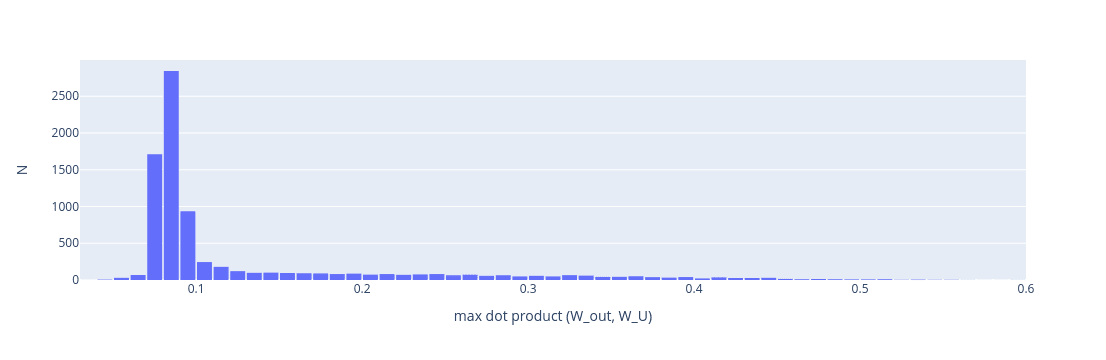
The distribution is non-symmetric: there is a long tail of neurons that are close to vocabulary tokens.
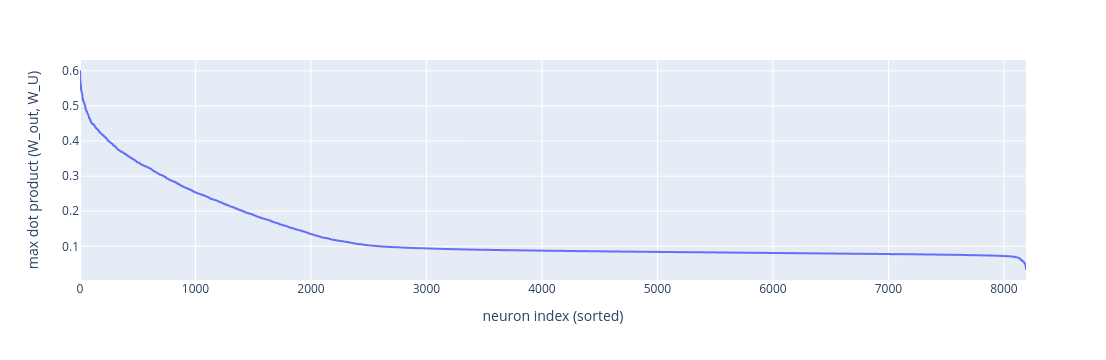
Sorting the neurons my max dot product highlights the distribution even better: there is a significant number of neurons with outputs that are aligned with vocabulary embedding.
Extending to other layers
This visualization can be repeated for MLPs in all other layers. Looking at all the distributions, majority of neurons that are stronger aligned with the vocabulary are in the later blocks:
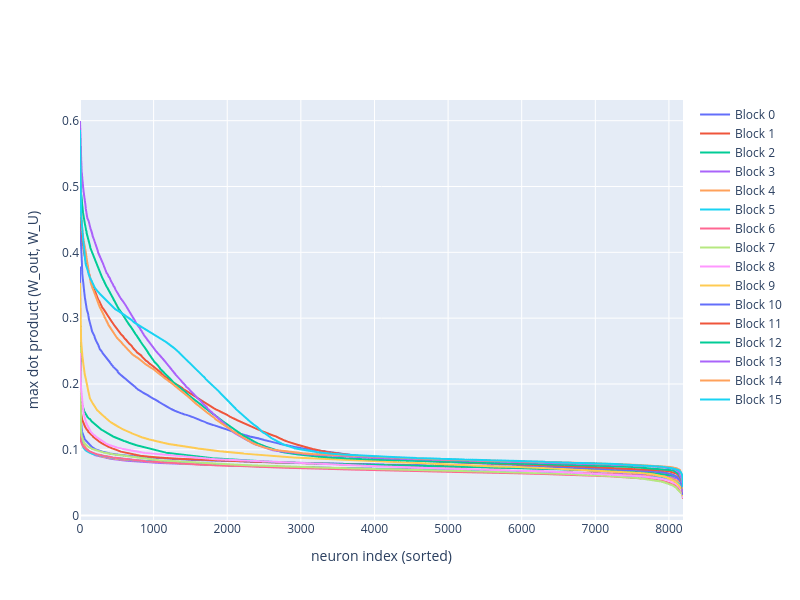
It's easer to see the difference with separate plots:
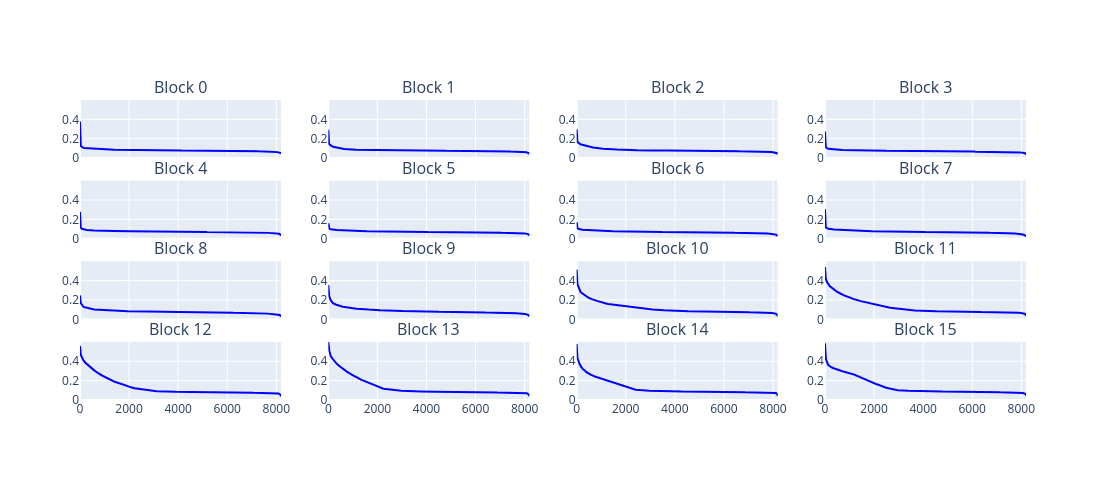
In summary, strong vocabulary alignment is clearly visible in a subset of neurons – especially in later layers. This opens up several follow-up questions:
- Do neurons that are close to a vocabulary embedding represent only one specific token, or are they representing a more abstract concept that just happens to be near a token's embedding? Does small distance to the vocabulary correlate with monosemanticity?What is the functional role of stronger vocabulary alignment? Are these neurons a mechanism for translating concepts from the model's internal representation back into token space, or are there some other roles?What is the coverage of this representation? Do all important tokens have a corresponding "vocabulary neuron”, or is this specialization reserved for a subset only? Why?
Code
The notebook with the code is on github: https://github.com/coolvision/interp/blob/main/LLaMA_jun_4_2025_neurons.ipynb
References
- Nguyễn, Thông. 2024. “Llama-3-8B MLP Neurons.” https://neuralblog.github.io/llama3-neurons.Dar, G., Geva, M., Gupta, A., and Berant, J. 2022. Analyzing transformers in embedding space. arXiv preprint arXiv:2209.02535.nostalgebraist. 2020. interpreting GPT: the logit lens. https://www.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens
Discuss
