


Natural language processing (NLP) has advanced significantly thanks to neural networks, with transformer models setting the standard. These models have performed remarkably well across a range of criteria. However, they pose serious problems because of their high memory requirements and high computational expense, particularly for applications that demand long-context work. This persistent problem motivates the pursuit of more effective substitutes that sustain performance standards while requiring fewer resources.
The main issue with transformer models is their high memory and processing requirements. Although these models perform well on NLP tasks, they could be more practical in contexts with limited resources. This difficulty highlights the need for models with lower computational overhead that can provide comparable or better performance than current ones. Resolving this issue is essential to increasing the usability and accessibility of modern NLP technology in various applications.
Existing research includes Linear Transformers, which aim to improve efficiency over softmax transformers. The RWKV model and RetNet offer competitive performance with linear attention mechanisms. State-space models like H3 and Hyena integrate recurrent and convolutional networks for long-sequence tasks. Methods such as Performers, Cosformer, and LUNA focus on enhancing transformer efficiency. The Griffin model combines sliding window and linear attention techniques.
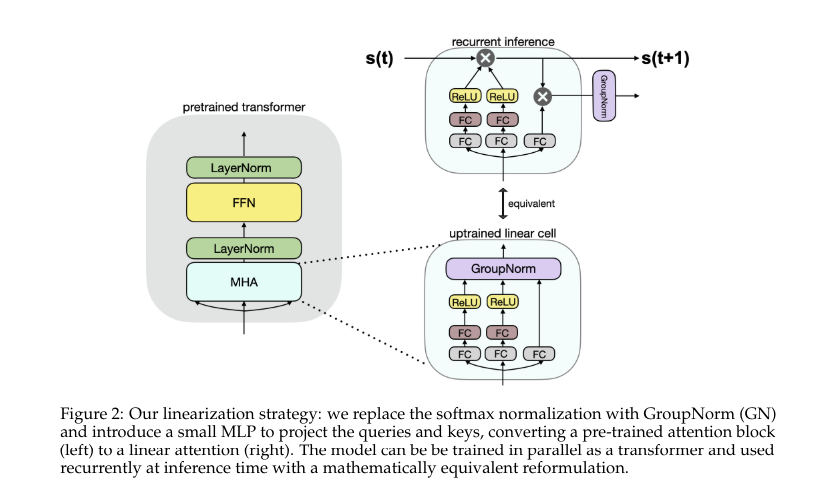
Researchers from the Toyota Research Institute have introduced Scalable UPtraining for Recurrent Attention (SUPRA), a method to convert pre-trained transformers into recurrent neural networks (RNNs). This approach leverages high-quality pre-training data from transformers while employing a linearization technique that replaces softmax normalization with GroupNorm. SUPRA is unique as it combines the strengths of transformers and RNNs, achieving competitive performance with reduced computational cost.
The SUPRA methodology involves uptraining transformers such as Llama2 and Mistral-7B. The process replaces softmax normalization with GroupNorm, including a small multi-layer perceptron (MLP) for projecting queries and keys. The models were trained using the RefinedWeb dataset with 1.2 trillion tokens. Training and fine-tuning were performed using a modified version of OpenLM, and evaluations were conducted with the Eleuther evaluation harness on standard NLU benchmarks. This approach allows transformers to operate recurrently and efficiently, handling short and long-context tasks.
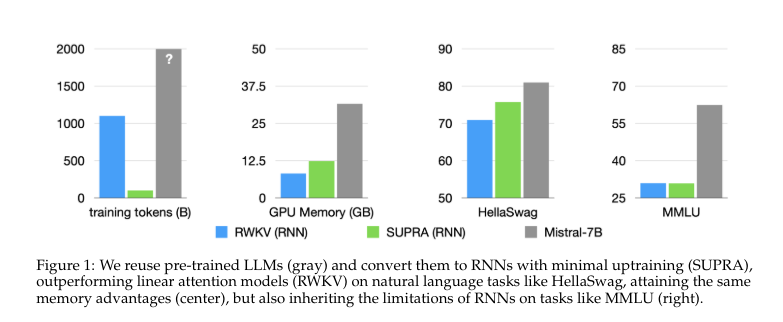
The SUPRA method showed competitive performance on various benchmarks. It outperformed RWKV and RetNet on the HellaSwag benchmark, achieving a score of 77.9 compared to 70.9 and 73.0, respectively. The model also demonstrated strong results on other tasks, with scores of 76.3 on ARC-E, 79.1 on ARC-C, and 46.3 on MMLU. Training required only 20 billion tokens, significantly less than other models. Despite some performance drops in long-context tasks, SUPRA maintained robust results within its training context length.
In conclusion, the SUPRA method successfully converts pre-trained transformers into efficient RNNs, addressing the high computational costs of traditional transformers. By replacing softmax normalization with GroupNorm and using a small MLP, SUPRA models achieve competitive performance on benchmarks like HellaSwag and ARC-C with significantly reduced training data. This research highlights the potential for scalable, cost-effective NLP models, maintaining robust performance across various tasks and paving the way for more accessible advanced language processing technologies.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
The post This AI Paper by Toyota Research Institute Introduces SUPRA: Enhancing Transformer Efficiency with Recurrent Neural Networks appeared first on MarkTechPost.
