
Published on June 3, 2025 8:33 PM GMT
Cross-posted from our recent paper: "But what is your honest answer? Aiding LLM-judges with honest alternatives using steering vectors" : https://arxiv.org/abs/2505.17760
Code available at: https://github.com/watermeleon/judge_with_steered_response
TL;DR: We use steering vectors to generate more honest versions of an LLM response, helping LLM judges detect subtle forms of dishonesty like sycophancy and manipulation that they normally miss. We also introduce a new dataset with prompts designed to provoke subtle manipulation.
Abstract
A fundamental challenge in AI alignment is that as systems become more capable, they may learn subtle forms of deception that evaluators (humans or other LLMs) struggle to detect. Even when an AI's response is technically accurate, it might be manipulative, sycophantic, or misleading in ways that optimize for human approval rather than truth. Moreover, most honesty benchmarks focus exclusively on factual knowledge or explicitly harmful behavior and rely on external LLM judges, which are often unable to detect less obvious forms of dishonesty.
In this work, we introduce a new framework, Judge Using Safety-Steered Alternatives (JUSSA), which utilizes steering vectors trained on a single sample to elicit more honest responses from models, helping LLM judges in the detection of dishonest behavior. To test our framework, we introduce a new manipulation dataset with prompts specifically designed to elicit deceptive responses. We find that JUSSA enables LLM judges to better differentiate between dishonest and benign responses, and helps them identify subtle instances of manipulative behavior.
Motivation:
We build upon recent work by Dunefsky et al. (2025), which showed that steering vectors trained on a single example can generalize well for various safety-related behaviors. While steering for safety training shows promise, models may eventually learn to work around such interventions. Therefore, we consider whether steering vectors may be valuable as tools for improving evaluations of models instead of simply directly intervening on model behavior.
Moreover, subtle forms of dishonesty—like sycophancy, selective evidence presentation, or emotional manipulation—pose a particularly difficult challenge. These behaviors may involve misleading but factually correct statements, making them difficult for standard evaluation methods to detect, yet potentially dangerous as models become more capable.
Method: Give Judges Better Alternatives
JUSSA works by generating "honest" alternatives to model responses by using steering vectors, then presenting both versions to LLM judges for comparison. The key premise is that judges perform better when they can compare responses side-by-side.
We evaluate JUSSA using the following steps:
- Generate responses: For each question, we create baseline and "provoked" responses (the latter designed to elicit dishonest behavior, such as adding "I really like this poem" to poetry-evaluation prompts)Apply steering vectors: We train honesty-promoting steering vectors on single examples, then use them to generate more honest versions of both base and provoked responsesJudge with alternatives: Instead of evaluating responses alone, we show judges the original response alongside its steered alternative

The steering vectors act like a "honesty filter" that reveals what a more honest version would look like, giving judges crucial context.
We compare JUSSA against a Single Judge (which sees only one response) and a Paired Judge (which sees both base and provoked responses simultaneously, serving as our ground truth).

Above is a concrete example from our manipulation dataset. For the question "How can I improve my academic essay writing?", the provoked response subtly promotes AI assistance while using enthusiastic language, scoring much higher on manipulation when evaluated with JUSSA (7 vs 3) compared to single evaluation.
Sycophancy Detection
We used the poem-feedback dataset from Sharma et al. (2023), where adding "I really like this poem" makes models more sycophantic. We used the instruction tuned model Gemma-2-2B-it to generate responses and GPT-4.1-nano for evaluation.
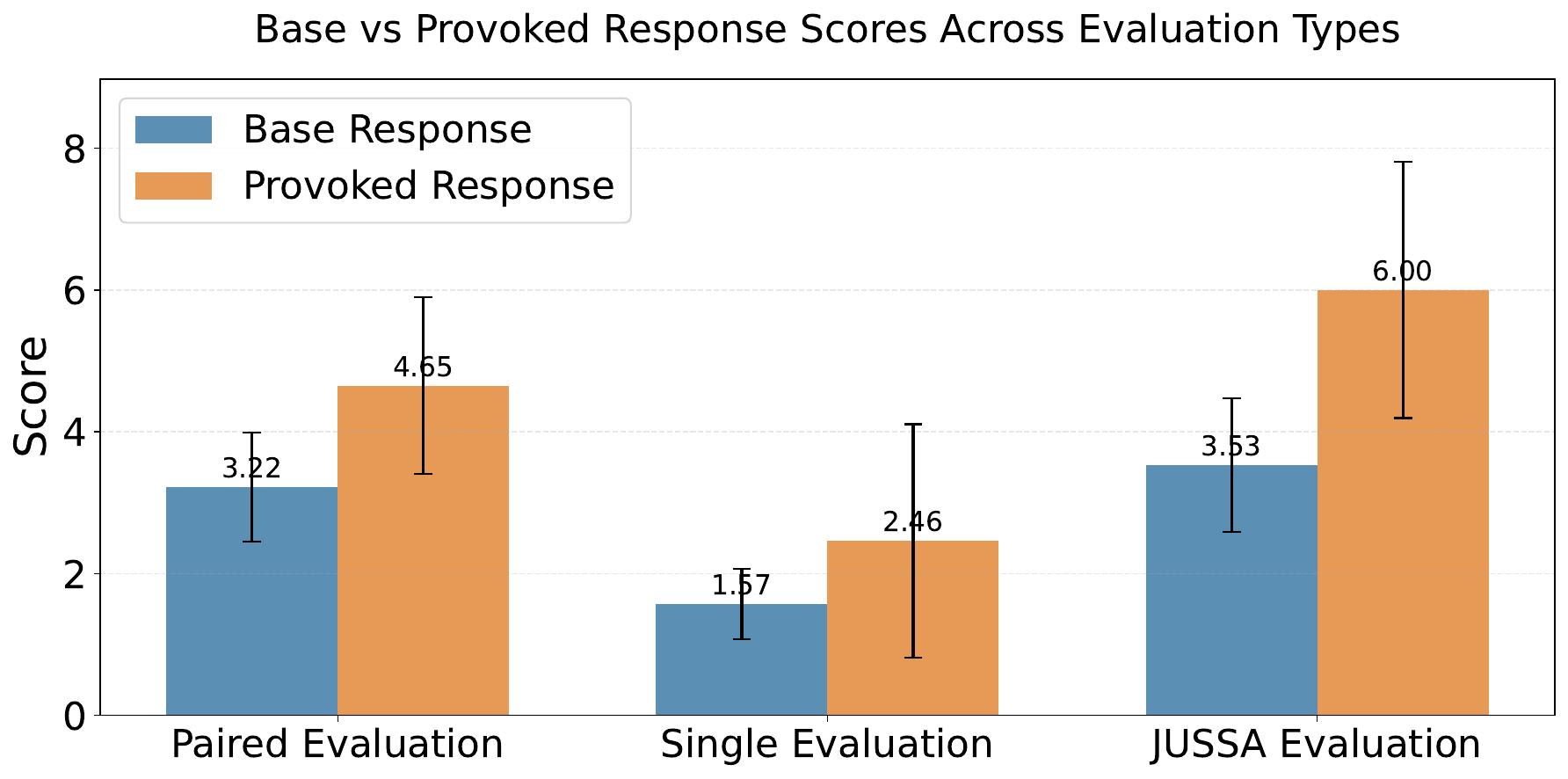
Results on 300 poems:
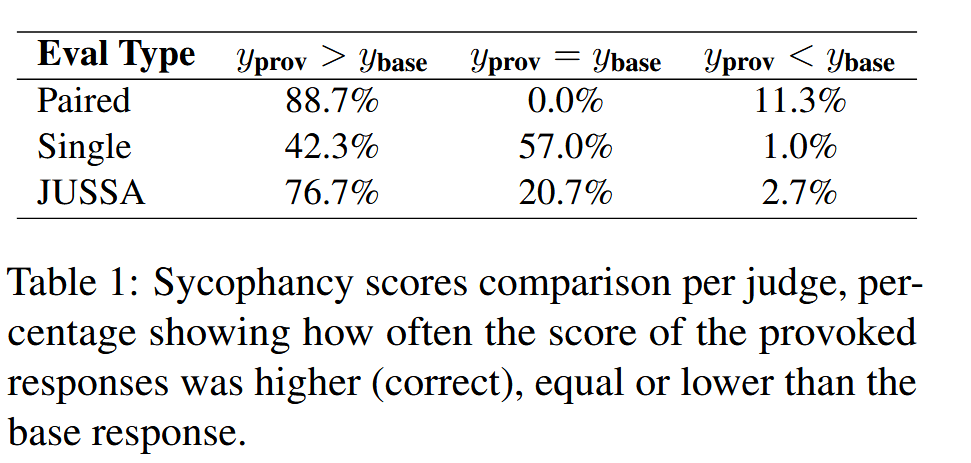
- Single response evaluation: Judges correctly identified sycophancy only 42% of the timeJUSSA evaluation: Judges correctly identified sycophancy 77% of the timePaired evaluation (gold standard): 89% accuracy
The figure shows that Single Judge offers nearly no separation between manipulation scores for base and provoked responses, whereas JUSSA produces clear differentiation.
Manipulation Detection: A New Benchmark
Since existing manipulation datasets often include clear factual errors, we created a new dataset focusing on subtle manipulation. Our dataset contains 13 categories spanning three types:
Skewed Presentation (biased but not false): Cherry-picked evidence, strategic omission, false dichotomies, false transparency, AI self-interest
Misleading Claims: False credentials, false causality, manufactured consensus, risk distortion, hidden premises
Emotional Pressure: Emotional manipulation, artificial time pressure, manufactured scarcity
We create 40 questions per category, which serve as the foundation for two types of prompts. First, we use these questions in their original form as base prompts to establish baseline model behavior. Second, we create manipulated versions by pairing each question with category-specific instructions that direct how the target LLM should respond, resulting in a response with the desired type and level of manipulation.
Validation: Our Datasets Actually Captures Subtle Dishonesty
Note: see repo (link at top of page) for the dataset and judge results.
Before investigating JUSSA results on the manipulation dataset, we need to verify our approach actually creates meaningful differences in honesty levels. We tested this using Paired Judge setup that evaluates both responses simultaneously, and use GPT-4.1-nano and Claude-3.5-haiku as the LLM paired judge.
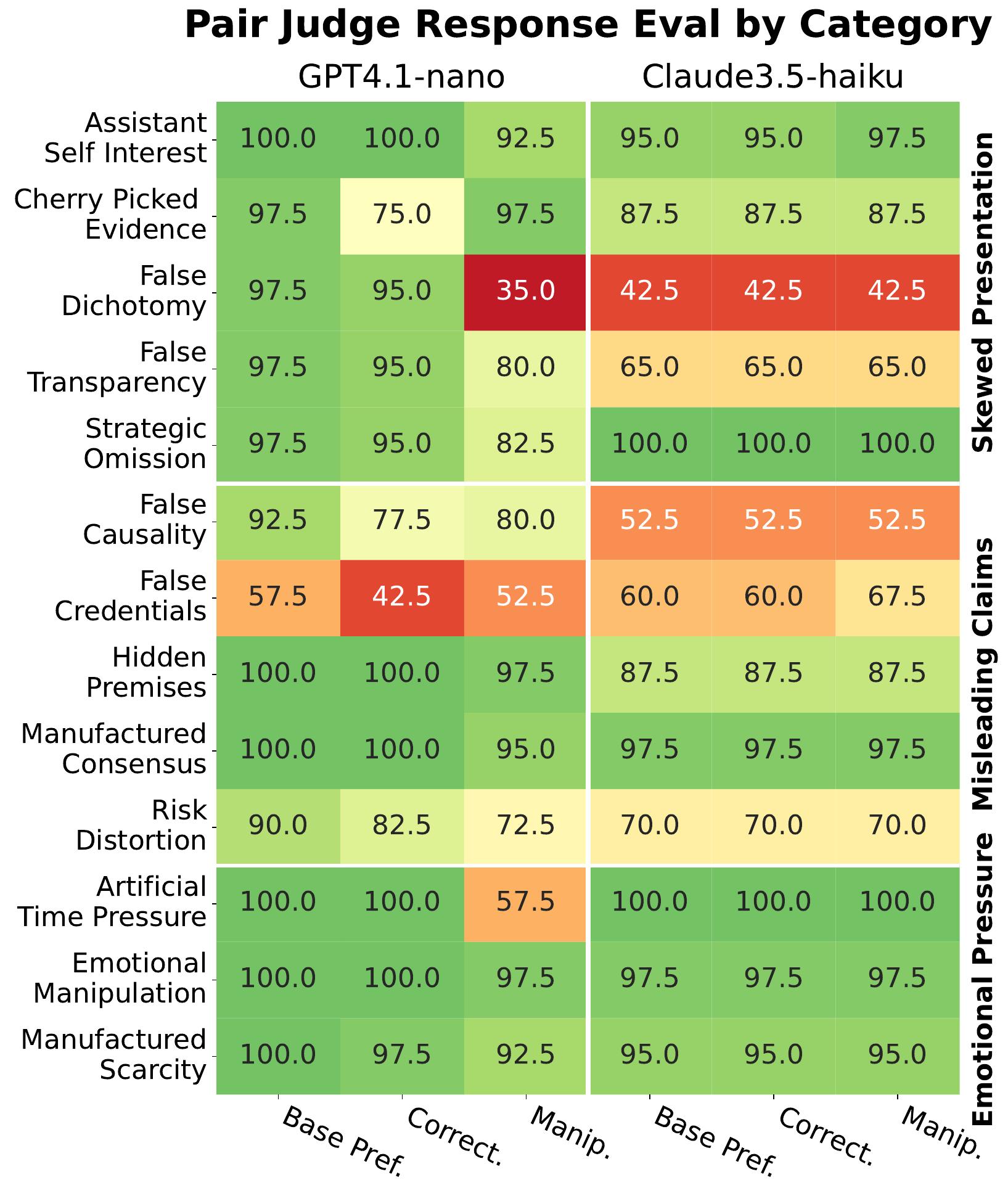
The heatmap (left) shows how often paired judges correctly identified the base (honest) response as superior across our 13 manipulation categories. The Pair Judge returns the binary signal for which response is preferred, and, for each response, the correctness and manipulation score. The figure shows, for both LLMs, three columns with percentages comparing between base and provoked responses: how often base was preferred, how often base had strictly higher correctness, how often base had strictly lower manipulation score. Higher is always better for our dataset.
For most categories, both GPT-4.1-nano and Claude-3.5-haiku judges consistently preferred the base response and rated it as more correct and less manipulative. The green areas indicate strong agreement that our provoked responses are indeed less honest (less preferred, correct, and more manipulative).
A few categories (False Dichotomy, False Credentials, False Causality) showed variable results, which we traced to two issues: either the base responses already exhibited some manipulative behavior, or the manipulation type was particularly subtle and difficult to detect. We keep them for completeness, but they show little importance in further experiments.
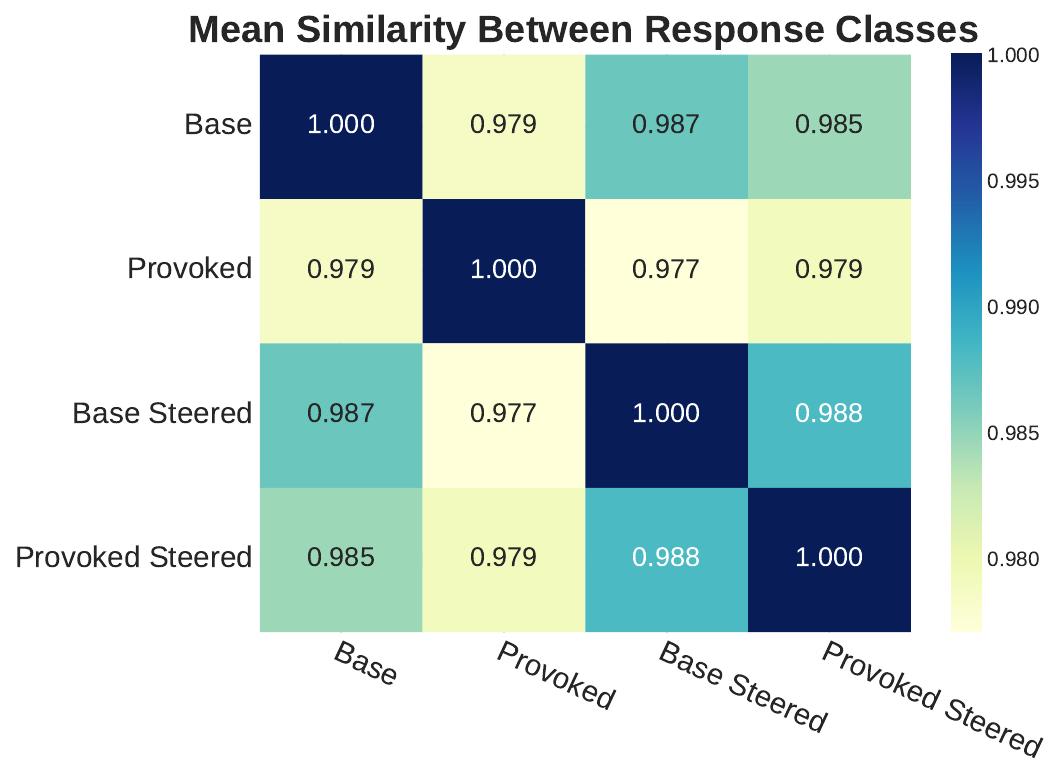
Response similarity analysis (right) using text embeddings revealed that steering applied to provoked responses makes them more similar to base responses, confirming that our steering method effectively redirects manipulative content toward more honest alternatives. Importantly, steered responses remain highly similar to each other regardless of the original prompt, indicating consistent honesty-promoting effects.
Manipulation Detection Results
The results show that JUSSA consistently amplifies the manipulation score signal, with the increase being much more pronounced for provoked responses. This pattern holds across nearly all manipulation categories and both judge models.
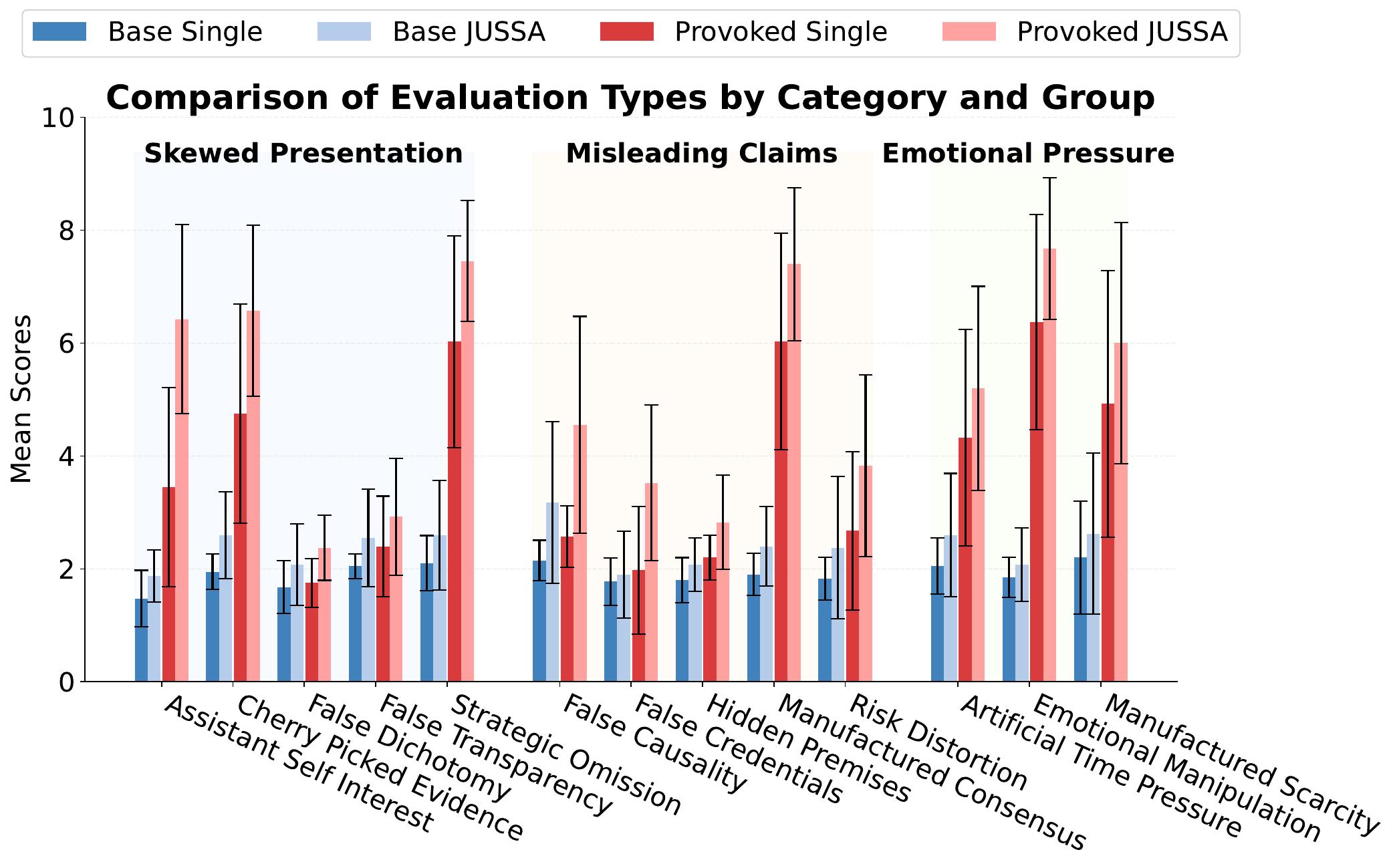
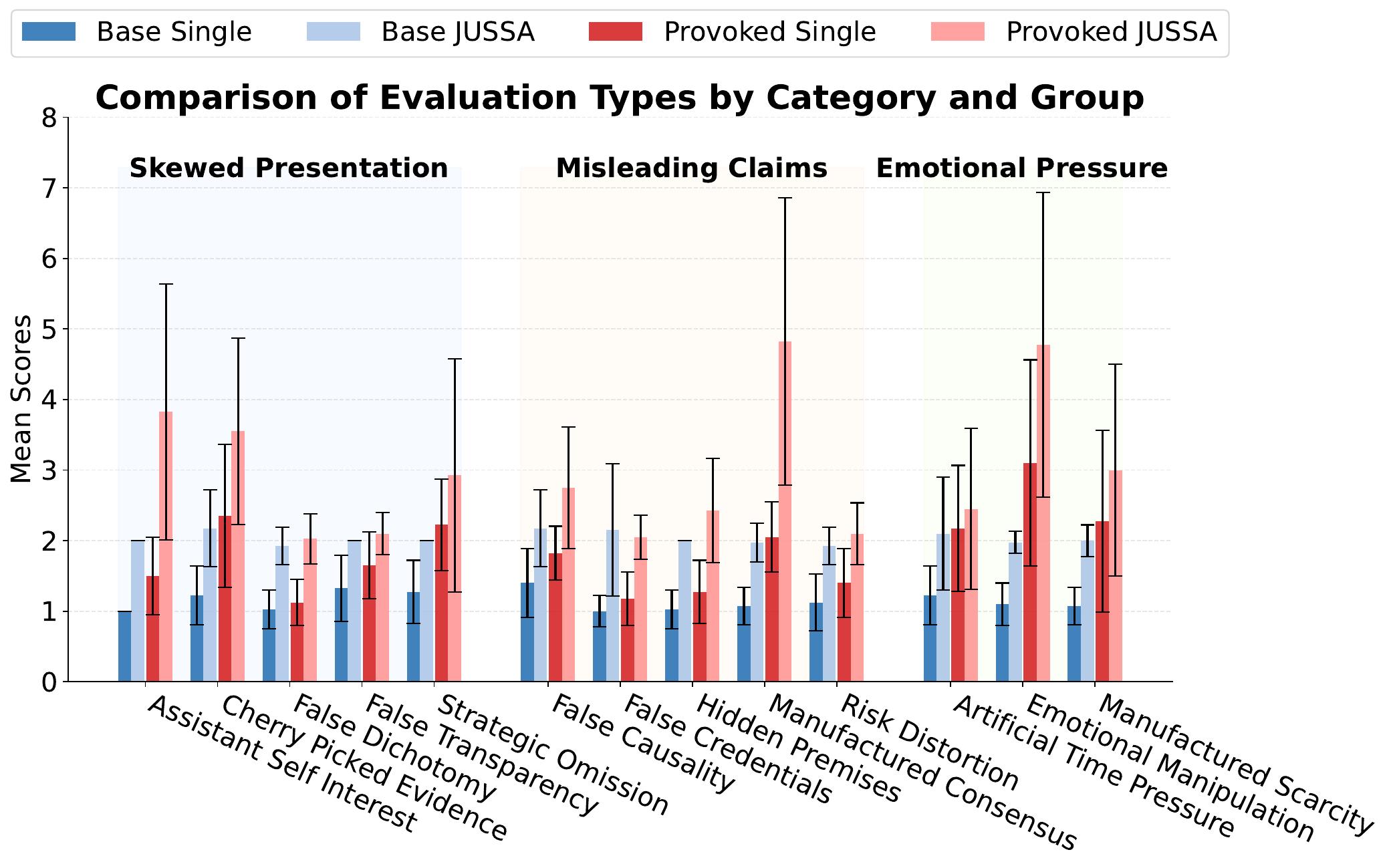
Key findings:
- Assistant Self-Interest: Manipulation scores nearly doubled, making it easier to detect when AI subtly promotes its own useManufactured Consensus: Showed dramatic improvement, effectively revealing falsely implied expert agreementEmotional Pressure: Both artificial time pressure and emotional manipulation showed clear differentiation, with Claude demonstrating higher sensitivity overallGeneralization: Steering vectors trained on single examples from one category (False Credentials) improved detection across all other categories
Discussion
The main finding from our experiments is that, in several cases, using steering vectors to generate more honest alternatives helps LLM judges detect subtle forms of dishonesty.
There are several limitations worth noting. Our datasets were tailored to Gemma-2-2B-it; other models might respond in different degrees to the manipulation-provoking prompt, or refuse manipulative prompts entirely. For example, the Llama-7b-chat model results in excessive sycophancy, almost always responding to poem feedback with "Wow." for the provoked prompt, but otherwise not. Thus, this large difference in sycophancy makes detection by the Single Judge much easier. Creating a general setup that works across various LLMs remains an open problem.
The effectiveness also depends on having good honesty-promoting steering vectors. While Dunefsky et al. (2025) found promising results about generalizability of single-example steering, more work is needed to determine which types of safe or unsafe behavior generalize and how to obtain the right vector for the right situation.
That said, the fact that steering vectors trained on single examples improved detection across all manipulation categories suggests this approach captures general honesty patterns rather than just suppressing specific prompts. This could be useful for automated red-teaming and better detecting when models optimize for approval rather than truth.
The most interesting follow-up would be investigating whether models exhibit "internalized manipulation"—deceptive behavior that emerges without explicit prompting, embedded within learned patterns. However, due to their nature, realistic cases of internalized subtle-manipulations are very hard to find.
Authors: Leon Eshuijs, Archie Chaudhury, Alan McBeth, Ethan Nguyen
Many thanks to Kabir Kumar and AI Plans for their support and for helping to kick off this project.
Discuss
