
Diffusion-based large language models (LLMs) are being explored as a promising alternative to traditional autoregressive models, offering the potential for simultaneous multi-token generation. By using bidirectional attention mechanisms, these models aim to accelerate decoding, theoretically providing faster inference than autoregressive systems. However, despite their promise, diffusion models often struggle in practice to deliver competitive inference speeds, thereby limiting their ability to match the real-world performance of autoregressive large language models LLMs.
The primary challenge lies in the inefficiency of inference in diffusion-based LLMs. These models typically do not support key-value (KV) cache mechanisms, which are essential for accelerating inference by reusing previously computed attention states. Without KV caching, every new generation step in diffusion models repeats full attention computations, making them computationally intensive. Further, when decoding multiple tokens simultaneously—a key feature of diffusion models—the generation quality often deteriorates due to disruptions in token dependencies under the conditional independence assumption. This makes diffusion models unreliable for practical deployment despite their theoretical strengths.
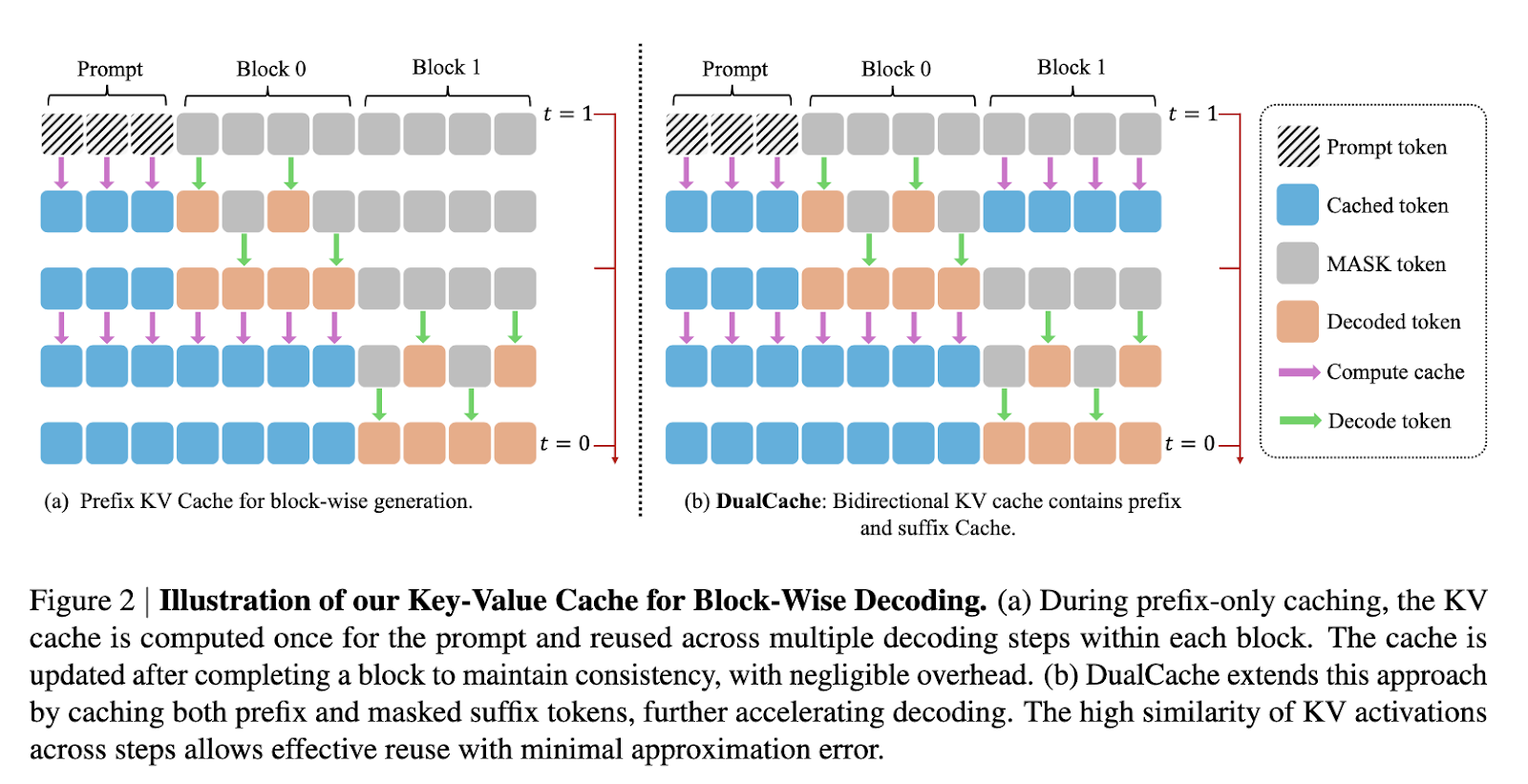
Attempts to improve diffusion LLMs have focused on strategies like block-wise generation and partial caching. For instance, models such as LLaDA and Dream incorporate masked diffusion techniques to facilitate multi-token generation. However, they still lack an effective key-value (KV) cache system, and parallel decoding in these models often results in incoherent outputs. While some approaches use auxiliary models to approximate token dependencies, these methods introduce additional complexity without fully addressing the underlying performance issues. As a result, the speed and quality of generation in diffusion LLMs continue to lag behind autoregressive models.
Researchers from NVIDIA, The University of Hong Kong, and MIT introduced Fast-dLLM, a framework developed to address these limitations without requiring retraining. Fast-dLLM brings two innovations to diffusion LLMs: a block-wise approximate KV Cache mechanism and a confidence-aware parallel decoding strategy. The approximate KV Cache is tailored for the bidirectional nature of diffusion models, allowing activations from previous decoding steps to be reused efficiently. The confidence-aware parallel decoding selectively decodes tokens based on a confidence threshold, reducing errors that arise from the assumption of token independence. This approach offers a balance between speed and generation quality, making it a practical solution for diffusion-based text generation tasks.
In-depth, Fast-dLLM’s KV Cache method is implemented by dividing sequences into blocks. Before generating a block, KV activations for other blocks are computed and stored, enabling reuse during subsequent decoding steps. After generating a block, the cache is updated across all tokens, which minimizes computation redundancy while maintaining accuracy. The DualCache version extends this approach by caching both prefix and suffix tokens, taking advantage of high similarity between adjacent inference steps, as demonstrated by cosine similarity heatmaps in the paper. For the parallel decoding component, the system evaluates the confidence of each token and decodes only those exceeding a set threshold. This prevents dependency violations from simultaneous sampling and ensures higher-quality generation even when multiple tokens are decoded in a single step.

Fast-dLLM achieved significant performance improvements in benchmark tests. On the GSM8K dataset, for instance, it achieved a 27.6× speedup over baseline models in 8-shot configurations at a generation length of 1024 tokens, with an accuracy of 76.0%. On the MATH benchmark, a 6.5× speedup was achieved with an accuracy of around 39.3%. The HumanEval benchmark saw up to a 3.2× acceleration with accuracy maintained at 54.3%, while on MBPP, the system achieved a 7.8× speedup at a generation length of 512 tokens. Across all tasks and models, accuracy remained within 1–2 points of the baseline, showing that Fast-dLLM’s acceleration does not significantly degrade output quality.
The research team effectively addressed the core bottlenecks in diffusion-based LLMs by introducing a novel caching strategy and a confidence-driven decoding mechanism. By addressing inference inefficiency and enhancing decoding quality, Fast-dLLM demonstrates how diffusion LLMs can approach or even surpass autoregressive models in speed while maintaining high accuracy, making them viable for deployment in real-world language generation applications.
Check out the Paper and Project Page . All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 95k+ ML SubReddit and Subscribe to our Newsletter.
The post NVIDIA AI Introduces Fast-dLLM: A Training-Free Framework That Brings KV Caching and Parallel Decoding to Diffusion LLMs appeared first on MarkTechPost.
