


Long-context LLMs enable advanced applications such as repository-level code analysis, long-document question-answering, and many-shot in-context learning by supporting extended context windows ranging from 128K to 10M tokens. However, these capabilities come with computational efficiency and memory usage challenges during inference. Optimizations that leverage the Key-Value (KV) cache have emerged to address these issues, focusing on improving cache reuse for shared contexts in multi-turn interactions. Techniques like PagedAttention, RadixAttention, and CacheBlend aim to reduce memory costs and optimize cache utilization but are often evaluated only in single-turn scenarios, overlooking real-world multi-turn applications.
Efforts to improve long-context inference focus on reducing computational and memory bottlenecks during pre-filling and decoding stages. Pre-filling optimizations, such as sparse attention, linear attention, and prompt compression, reduce the complexity of handling large context windows. Decoding strategies, including static and dynamic KV compression, cache offloading, and speculative decoding, aim to manage memory constraints effectively. While these methods enhance efficiency, many rely on lossy compression techniques, which can compromise performance in multi-turn settings where prefix caching is essential. Existing conversational benchmarks prioritize single-turn evaluations, leaving a gap in assessing solutions for shared contexts in real-world scenarios.
Researchers from Microsoft and the University of Surrey introduced SCBench, a benchmark designed to evaluate long-context methods in LLMs through a KV cache-centric approach. SCBench assesses four stages of KV cache: generation, compression, retrieval, and loading across 12 tasks and two shared context modes (multi-turn and multi-request). The benchmark analyzes methods like sparse attention, compression, and retrieval on models such as Llama-3 and GLM-4. Results highlight that sub-O(n) memory methods struggle in multi-turn scenarios, while O(n) memory approaches perform robustly. SCBench provides insights into sparsity effects, task complexity, and challenges like distribution shifts in long-generation scenarios.
The KV-cache-centric framework categorizes long-context methods in LLMs into four stages: generation, compression, retrieval, and loading. Generation includes techniques like sparse attention and prompt compression, while compression involves methods like KV cache dropping and quantization. Retrieval focuses on fetching relevant KV cache blocks to optimize performance, and loading involves dynamically transferring KV data for computation. The SCBench benchmark evaluates these methods across 12 tasks, including string and semantic retrieval, multi-tasking, and global processing. It analyzes performance metrics, such as accuracy and efficiency, while offering insights into algorithm innovation, including Tri-shape sparse attention, which improves multi-request scenarios.
The researchers evaluated six open-source long-context LLMs, including Llama-3.1, Qwen2.5, GLM-4, Codestal-Mamba, and Jamba, representing various architectures such as Transformer, SSM, and SSM-Attention hybrids. Experiments used BFloat16 precision on NVIDIA A100 GPUs with frameworks like HuggingFace, vLLM, and FlashAttention-2. Eight long-context solutions were tested, including sparse attention, KV cache management, and prompt compression. Results showed that MInference outperformed in retrieval tasks, while A-shape and Tri-shape excelled in multi-turn tasks. KV compression methods and prompt compression yielded mixed outcomes, often underperforming in retrieval tasks. SSM-attention hybrids struggled in multi-turn interactions, and gated linear models showed poor performance overall.
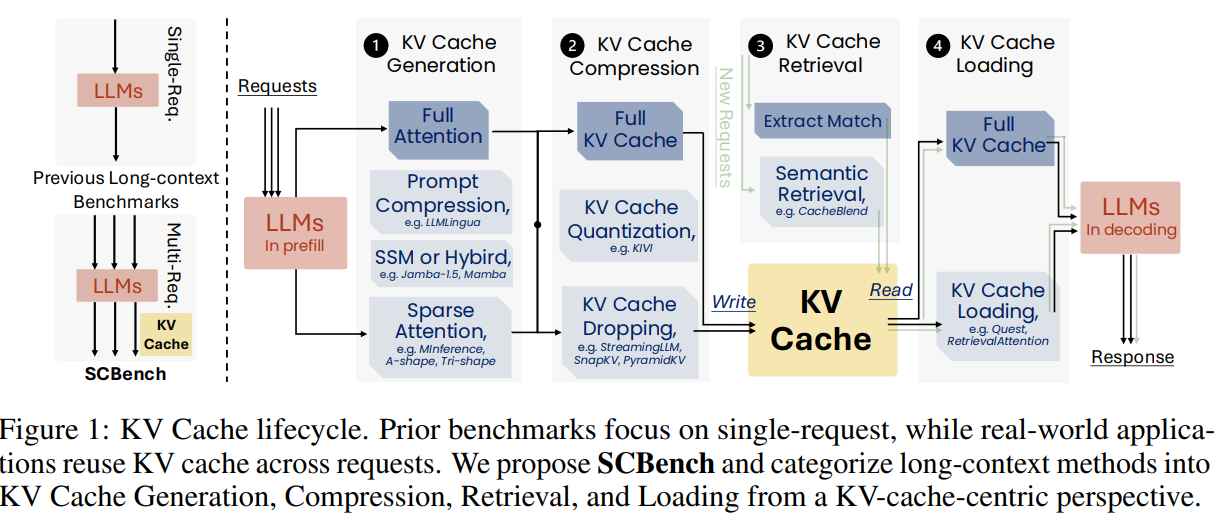
In conclusion, the study highlights a critical gap in evaluating long-context methods, which traditionally focus on single-turn interactions, neglecting multi-turn, shared-context scenarios prevalent in real-world LLM applications. The SCBench benchmark is introduced to address this, assessing long-context methods from a KV cache lifecycle perspective: generation, compression, retrieval, and loading. It includes 12 tasks across two shared-context modes and four key capabilities: string retrieval, semantic retrieval, global information processing, and multitasking. Evaluating eight long-context methods and six state-of-the-art LLMs reveals that sub-O(n) methods struggle in multi-turn settings. In contrast, O(n) approaches excel, offering valuable insights for improving long-context LLMs and architectures.
Check out the Paper and Dataset. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post Microsoft AI Introduces SCBench: A Comprehensive Benchmark for Evaluating Long-Context Methods in Large Language Models appeared first on MarkTechPost.
