
一个新的Benchmark,竟让大模型在复杂视频推理这事儿上统统不及格!
这就是腾讯ARC Lab和香港城市大学最新推出的Video-Holmes——
如其名,它可以说是视频推理界的“福尔摩斯测试”,通过让多模态大模型参与“推理杀人凶手”, “解析作案意图”等高难度的推理任务,以展现他们复杂视频推理能力的边界。
而且Video-Holmes可以说是规避了现在业内已有的Benchmark痛点,即视频源和问题都偏简单,没法反映推理模型和非推理模型之间的差距。
举个例子 。
。
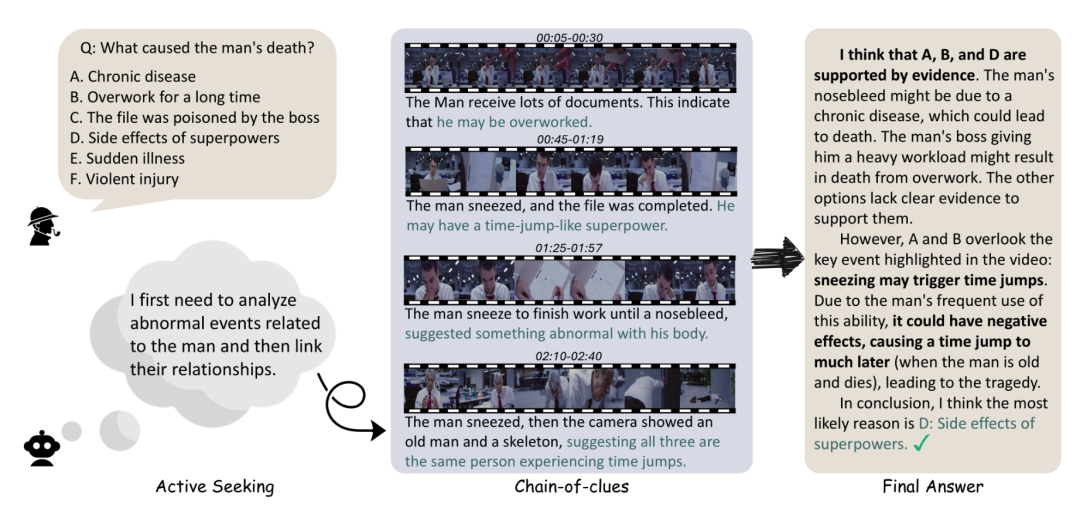
在这个例子中,为了寻找男人真正的死因,模型需要主动思考需要关注的视觉信息,并通过逻辑关联分散在不同视频片段中的多个相关线索进行推理,最后发现男人的死因居然是:“过度使用超能力”?!
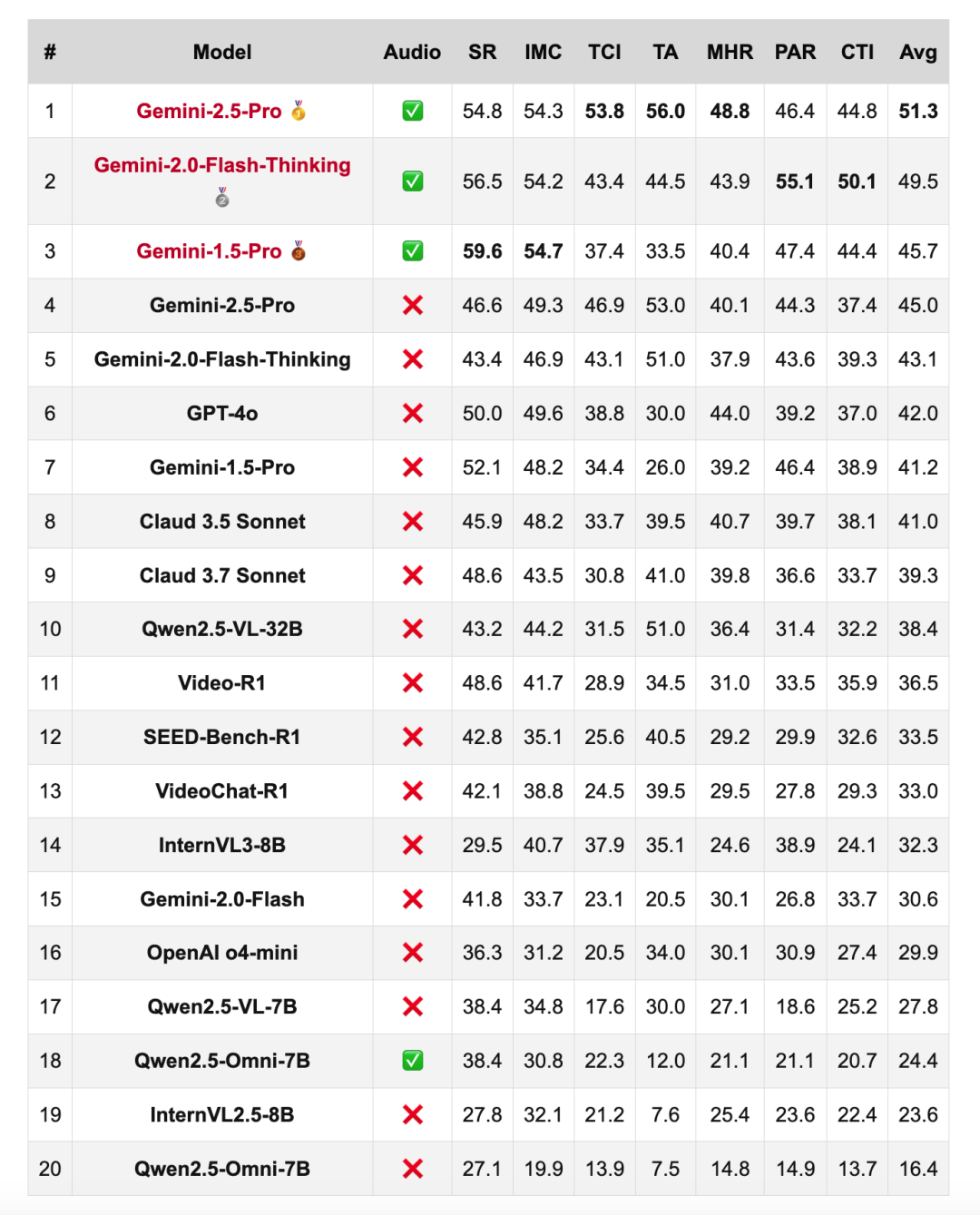
结果啊,测试的成绩可谓是大跌眼镜。
所有大模型,在各项测试中全部不及格:
(SR代表社会推理;IMC意指意图与动机链;TCI表示时间因果推理;TA时间线分析;MHR即多模态提示推理;PAR为物理异常推理;CTI代表核心主题推理。)
值得一提的是,这个Benchmark的“一键测评懒人包”,目前已经上线到了GitHub和HuggingFace,有做视频推理相关的小伙伴,可以去挑战一下了(地址见文末)。
让大模型全军覆没的新Benchmark
正如刚才提到的,现有视频推理基准(如 VCR-Bench、MVBench 等)主要评估模型的视觉感知和接地能力。
大多数问题也是基于显式提示或孤立视觉线索(如 “女人穿了什么”),无法模拟人类在现实中主动搜索、整合、分析多线索的复杂推理过程。
即使是较为前沿的模型,在这些基准上的提升也非常有限(如从 68.3% 到 69.4%),难以验证模型的真实推理能力。
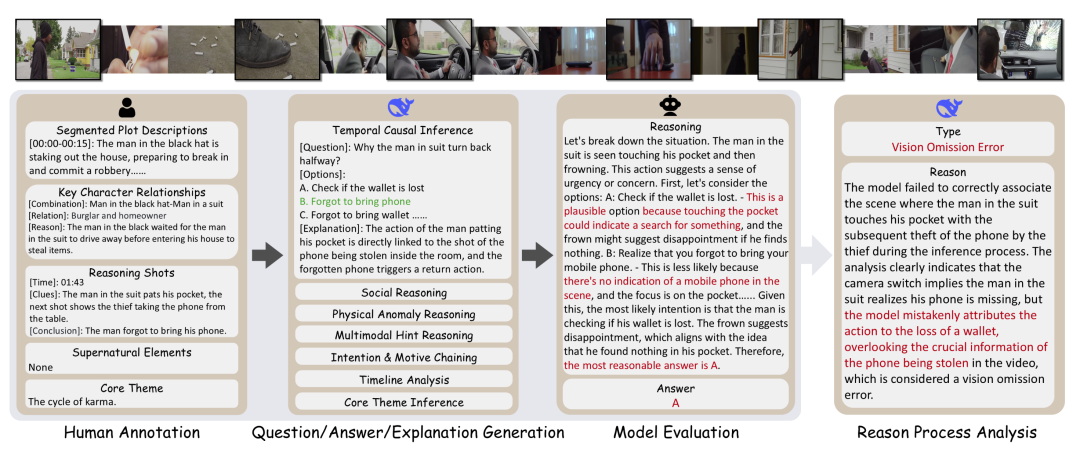
因此,团队收集并人工标注了270部1-5分钟的“推理短电影”,并设计了7种高推理要求的单选题,强迫模型提取,串联多个散布在电影中的关键信息来推导出最终的真相。
值得注意的是,设计的问题是由DeepSeek来生成,并且也是由DeepSeek来评估的响应。
至于问题的类型(上文我们提及的几大类型),具体的“打开方式”如下:

再深入到具体问题的回答,各个大模型回答结果如下(以SR和IMC为例):


测试结果显示,即使强大入Gemini-2.5-Pro的闭源模型,也仅达到了45%的准确率。
并且Video-Holmes能够反应推理模型和对应非推理版本之间的Gap——
SEED-Bench-R1 比 Qwen2.5-VL-7B提升了5个点,而Gemini-2.0-Thinking比Gemini-2.0提升了整整12个点!
除此之外,团队进一步还分析了模型的推理过程,结果显示,现有模型整体上能够正确感知视觉信息,但它们普遍在线索串联信息(推理能力)上欠缺,以及容易遗漏关键的视觉信息。
注:Video-Holmes的标注、构建、测试、推理过程分析的资料和代码,以及论文全部都开源啦(见文末)~
如何“食用”?
大家若是想下载Video-Holmes,可以运行如下代码:
git clonehttps://github.com/TencentARC/Video-Holmes.gitcd Video-Holmespip install huggingface_hubpython download.py —hf_token YOUR_HUGGINGFACE_ACCESS_TOKENunzip Benchmark/videos.zip -d Benchmark/unzip Benchmark/annotations.zip -d Benchmark/
团队还为基线模型提供了一体化的评估代码:
python evaluate.py —model_name YOUR_MODEL_NAME —model_path YOUR_MODEL_PATH (optional)以及可支持的大模型名单如下:

还可以通过指定——model_path参数或实现以下函数来定制模型:prepare_your_model(第388行)和generate_your_model(第439行)。
推理过程分析
首先需要应用DeepSeek API密钥,然后可以运行以下命令来分析模型的推理过程:
python evaluate_reasoning.py —model_name YOUR_MODEL_NAME —api_key YOUR_API_KEY生成你的“福尔摩斯测试”
要为带有注释的视频生成问题,你可以运行以下命令:
cd Pipelinepython generate_questions.py —api_key YOUR_API_KEY
那么你觉得这个新Benchmark如何?感兴趣的话就快去试试吧 ~
~
 HF Daily Paper:
HF Daily Paper:
https://huggingface.co/papers/2505.21374
 Homepage:
Homepage:
https://video-holmes.github.io/Page.github.io/
 Code:
Code:
https://github.com/TencentARC/Video-Holmes
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
